容器与虚拟化
虚拟机,容器,微服务,serverless
操作系统是运行在bare_mate(支持中断,io等功能的计算机)基础上的软件。
全系统模拟:qemu
对于应用程序:能看到属于自己的寄存器+地址空间+系统调用
OS:固件 到 init进程 再到定义一些对象来管理我们的物理资源
如果我们定义多套同类型的对象,均对应同一个物理资源。我在两套OS系统中,各自有各自的init进程(通过osid区分),并基于各自的init进程,演化出了不同的进程树。等同于我们在同一套物理机器上运行了多套互不干扰的系统(各自有各自pid=5的进程)。
linux namespace!
只要想 “操作系统里有什么对象” 就行了
- 需要为 osid 区别实现的对象
- pid: (刚才讲了)
- user: 用户和组 (这个很重要)
- mnt: 文件系统和设备
- ipc: 信号量、消息队列、共享内存
- net: 网络设备、协议栈、端口 (localhost:5000)
- time: 系统时间和时区
- uts: 主机名和域名
/proc/[pid]/ns/
Namespace 允许的api
clone
- 创建进程时可以带 CLONE_NEW_xxx (PID, IPC, …) 选项
setns, unshare
- 改变某一个项目的 “osid”
ioctl
- Windows Subsystem for Linux: 听我说谢谢谢你
Cgroups:控制底层的资源分配,控制每个进程允许调用的资源。
namespace+cgroups = 容器
容器是进程级别的,不需要完整的操作系统所有的部分。相比虚拟机,极大的减少了内存的消耗。
今天的架构:云原生,微服务,Serverless
Serverless:
函数是代表功能和需求的经典概念,容器都可以不需要,只需要函数就行了。
厂商根据请求,去将函数拉下来,自动分配容器然后执行。
Serverless:
Faas:Function-as-a-Service
Remote Procedure Call (RPC) 调用远程函数
Serverless = FaaS + BaaS 的经典定义
CICD 我们是否可以运行两个容器,做到无感发布
- “AI inference” 占程序运行时长的比例会越来越高吗?
docker
Dockerfile
Docker-compose
测试了下docker的教程,不过都是按部就班,有种做了跟没做一样。不过初步熟悉后先定下目标:
1.将base服务部署到docker中并启动起来
2.使用ali的流水线CICD(类似github的action)
Q:
- 如何在本地命令行中将服务启动起来?
-
将依赖的core,base api,base orm 等依赖分别mvn clean install
-
mvn clean install service
-
Java -jar ;一直失败 why?maven仓库地址没有加入classpath
-
解决办法:
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <version>3.6.1</version> <executions> <execution> <id>copy-dependencies</id> <phase>package</phase> <goals> <goal>copy-dependencies</goal> </goals> <configuration> <outputDirectory>${project.build.directory}/lib</outputDirectory> <includeScope>runtime</includeScope> <!-- 包含运行时依赖 --> </configuration> </execution> </executions> </plugin>此时会将所有依赖,打包到targte下的lib目录,target目录下运行如下命令即可
/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/bin/java -classpath ./lib -jar basecenter.service-bp-1.0.jar
-
-
重新编写dockerfile,尝试将项目打包到docker中,在docker中配置好环境,并启动
-
因为相关的jar包已经在本地都存在了,本地也可以直接在命令行中跑起来,现在只需要在docker的java8镜像中将相关依赖包copy到指定目录然后启动就ok了。先从简单的搞起,后面再尝试将整个项目在docker中编译&运行
-
故dockerfile如下:
FROM azul/zulu-openjdk:8 WORKDIR /app COPY target/basecenter.service-bp-1.0.jar . COPY target/lib/* ./lib/ ENTRYPOINT ["java","-classpath","./lib", "-jar", "basecenter.service-bp-1.0.jar"] -
` docker build -t basecenter:liaozkfrist .` 构建容器
-
docker run -it -p 8762:8763 basecenter:liaozkfrist启动容器
-
-
链接数据库,需要使用VPN,本地启动VPN,docker中能顺利链接吗?
完全可以,因为docker只是在现有os的基础上进行了部分资源的隔离,本质还是调用的现有os相关命令
- 重中之重了,目前是基于本地的打包,然后将相关资源copy到docker容器,如何以源代码构建镜像呢?将basecenter涉及的mvn&依赖的其他项目copy到镜像,在镜像中进行打包,然后运行?
jenkins
直接教程:https://www.jenkins.io/zh/doc/tutorials/build-a-java-app-with-maven/#setup-wizard
主要原因分析
- 用户映射问题(核心原因):
- 容器内的 root 用户(UID=0) ≠ 宿主机的 root 用户(UID=0)
- Docker 默认使用用户命名空间隔离,容器内的 root 实际上映射到宿主机的非特权用户
- 挂载点权限冲突:
/var/run/docker.sock在宿主机上的实际所有者是您的 macOS 用户(非 root)- 容器内的 root 用户无法直接访问宿主机的用户文件
- Docker Desktop 的 VM 隔离层:
- macOS 上的 Docker 通过 Linux 虚拟机运行
- 权限需要经过 macOS 用户 → VM 用户 → 容器用户 多层映射
坑比:linux的权限校验概念模型是通过校验进程的uid/gid是否有访问文件的权限。即使在docker中挂载,只要docker镜像启动的时的uid与gid有相关权限就可以在docker中调用。但这里mac会遇到一个问题: 1.root用户启动,但usr/bin/local/docker实际链接到application文件中的,application文件是用户权限(liaozk),root用户无权限,修改application中的权限需要关闭mac的系统完整性保护。 2.liaozk用户启动,mac上的docker实际是运行在虚拟机中的需要通过一个虚拟目录然后才能访问到系统目录,访问修改var等目录需要root权限。
练习
开启新的模拟:
- 写一个项目,用到自己的模块,也用到maven模块
- 云服务器上部署docker
- 云效管理代码
- 云效创建流水线,构建镜像,并在云服务器的docker中运行镜像
- 本地容器运行kafka
- 项目整合kafka
- 模拟消费不足,消息堆积的场景
20250621:完成1&2&3.其中,云效管理代码有个大坑,因为生产的项目也有用到云效,已经将git的用户名&密码全局配置了,导致此时必须将url配置成:用户名:密码@url的格式。(一开始还纳闷,又没有配置公钥,使用的也不是ssh,而是http,为什么没有验证,总是报错没有权限…)
20250622:尝试构建流水线&在服务器的docker中启动项目!
在官方的示例中,包含了构建与部署,这里我并不想去学习有关k8s的相关知识,既然是学习项目,我们只需要,通过云效的flow构建docker image,然后登录服务器,拉取并运行。
1.编写docker file 试图在本地将服务跑起来
绷不住了😭:api模块中 昨天添加了<skipMain>true</skipMain> 试图不校验启动类。结果今天的打包,完全跳过了编译api中的class,怪不得,命名仓库中有api的jar包,结果还是报错找不到类…
15.44:ok 终于可以在本地docker中跑起来了,还有两个小时,今日目标完成,指日可待!
2.使用云效flow构建image &推送到个人仓库
又是一个绷不住😭:阿里无法连接docker hub,无法获取基础镜像… 需要自己制作相关镜像然后上传到本地仓库
失败,maven wrapper 运行失败,应该是网络的原因,本地vpn,可以正常制作镜像,阿里云flow 则运行报错…
难难难…
next 解决 maven的问题…
17.33 做不完了,溜了,溜了…
20250623:21:38
yes! we do it! We can do it!!!!!!
We belive, we do, we achieve!
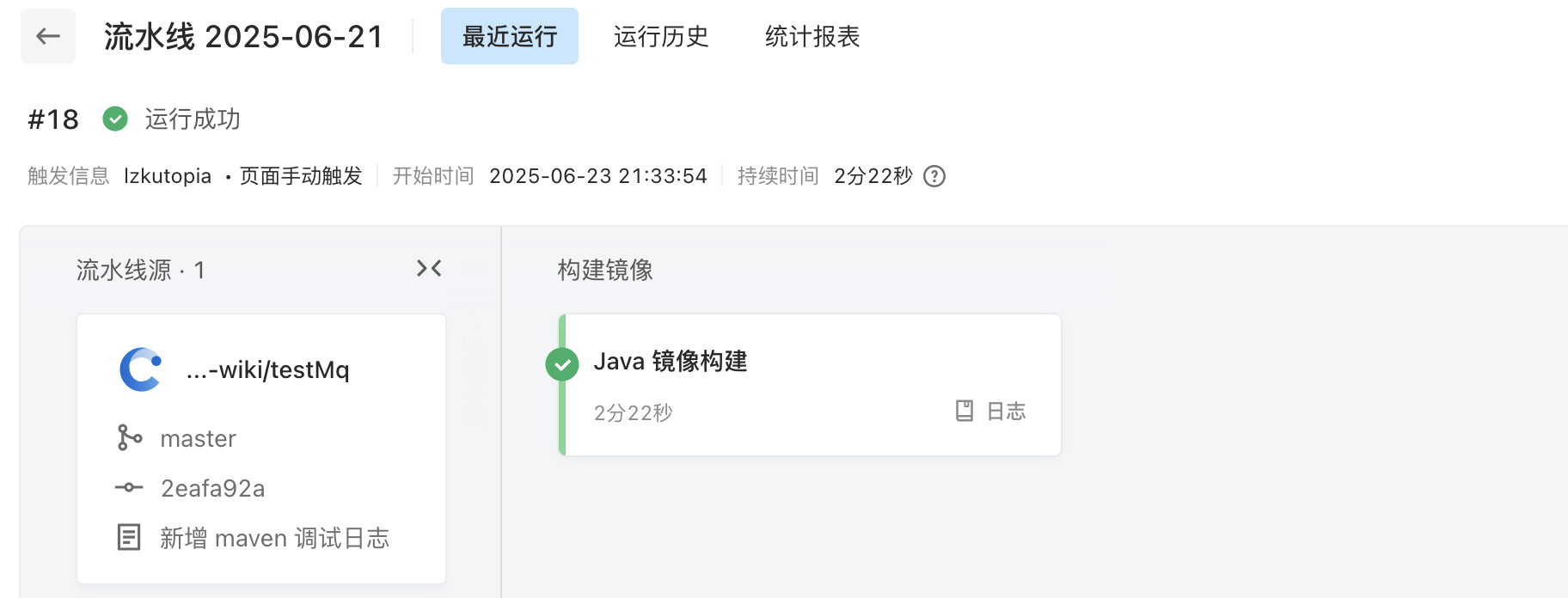
终于成功了!成功将代码构建并推送到仓库。一扫三天的阴霾,我将无所不至!我感觉前途一片光明!没有什么能阻止我了!(不是🫠)
坑1:云效的构建环境没有java,需要选择java镜像构建
坑2:why 容器环境需要arm64?因为我本地是在mac上编辑的文件?
坑3:需要自定义基础镜像,然后自定义mvn的xml,使用阿里的代理,同时还需要自定义插件…
3.服务器拉取image&运行
20250624:19:53 又是1个小时过去了,坑总是一个连着一个。mac本地下载的镜像,默认是arm的…怪不得昨天报错不兼容…重新下载了x86_64的并推送到了服务器。然后重新构建。
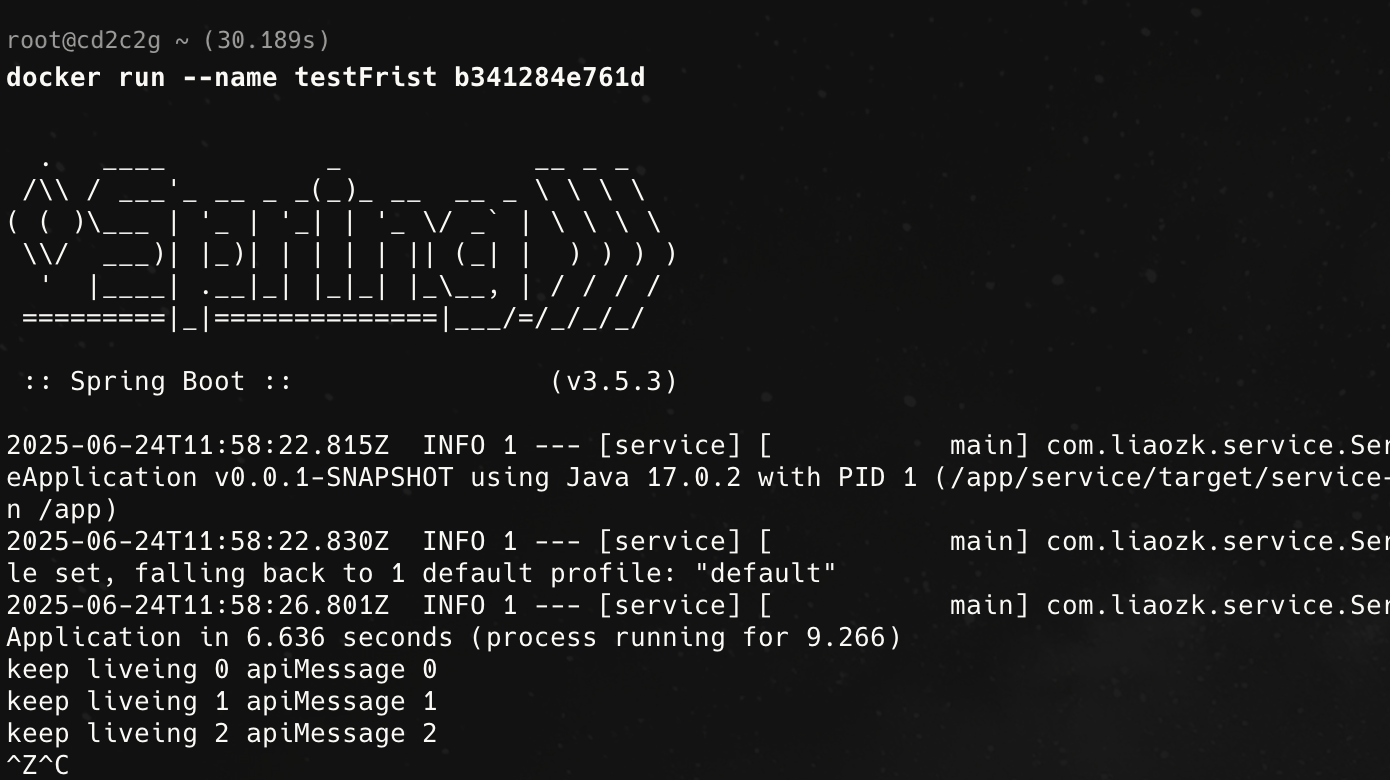
很好!
明天学习下kafka,然后整合到项目,再然后本地运行起来kafka。再抽空将部署也搞定。20.24 睡个好觉,然后明天全身心投入!
kafka
基本概念:
事件:是kafka的基本操作对象。
生产者客户端:
- 传统的MQ,activeMQ是store-and-forward结构,生产者先将消息持久化到本地,然后由服务器去拉取,服务器需要知道生产者的状态。kafka则是生产者,将数据推送到服务器,服务器持久化保存,同时通过id(生产者标识(PID)和序列号(Sequence Number)),实现生产者幂等。
- 生产者将数据发送到分区所属leader的broker。所有节点都可以回答生产者对应的当前leader是谁。
- 生产者可以自定义,发送到具体那个分区。
- 允许生产者批处理,异步批量发送数据。
消费者客户端:
- kafka采用消费者通过poll 拉取数据,无数据时,消费者IO多路复用阻塞,服务器则长轮询,有消息或超时才返回。一般一旦返回后,消费者立即发起新的poll请求。
- MQ中消费者相关的另一个问题就是:偏移量。MQ需要知道哪些消息已经发送给消费者了,哪些消息已经被确认消费了(1.消费者已经处理了消息,但确认失败将导致重复消费。2.需要维护消息的多个状态。)kafak因为分区之能被消费者组中的一个消费者处理,故只需维护对应消费者组的偏移量即可。
- 静态成员id固定,有什么用?流式处理?暂时不深入。
主题:类似文件夹,事件被组织并持久存储到主题中。一个主题,可以0,1,n个生产者&消费者,对于kafka,事件在使用后,不会被删除,可以持久化。
消费者组:传统的MQ基本上有队列模式与发布订阅模式。kafka对二者的实现是通过消费者组实现的,一个分区的消息只允许被n个消费者组中的一个消费者消费。n=1,就是队列模式,n>1就是发布订阅模式。
topic - 分区 - 事件
同一个分区,可以被不同的消费组消费,同一个消费组只能有一个消费者订阅该分区
消费者痛殴poll 拉取一批数据然后消费,poll之间有个间隔时间,若间隔时间内消费者未处理完,会下线消费者…
消息传递语义:
MQ一般可以在生产者与消费者之间提供如下消息传递语义:
- At most once—Messages may be lost but are never redelivered.
- At least once—Messages are never lost but may be redelivered.
- Exactly once—Each message is processed once and only once.
发布消息的持久性保证 + 使用消息的保证
恰好一次,有许多例外:消费者/生产者失败?消费者多线程?磁盘持久失败?
我们描述一个状态可以有两种方式:
- 描述当前存储的最终状态
- 描述对磁盘或数据的所有操作,通过操作得到最终的状态(log)
生产者-kafka的语义:
发布消息=committed to the log,只要分区副本的broker有一个还是alive,消息就不会丢失。
生产者幂等/事务,生产者id+分区序列号(前面生产者部分已叙述)
消费者-kafka的语义:
分区的所有副本,具有相同的日志,相同的偏移量。
Kafka 的 Exactly-Once 语义在跨主题消费-生产场景(如 Kafka Streams)的实现依赖 事务机制 和 隔离级别控制:
事务机制:
生产者:同一个生产者向多个分区写入数据,可以事务保证,都成功or都失败。
消费者:隔离级别,主题的数据可见性:read_uncommitted,read_committed。
此外要实现Exactly-Once,还需要消费者业务系统的支持:诸如消费成功才commit。
二者共同确保:Exactly-Once 语义
涉及到分布式系统相关概念,没太理解…:https://kafka.apache.org/documentation/#semantics
从事务开始:到同步,复制,日志压缩与配额,开始都不太理解了。
总结:
基本结构:

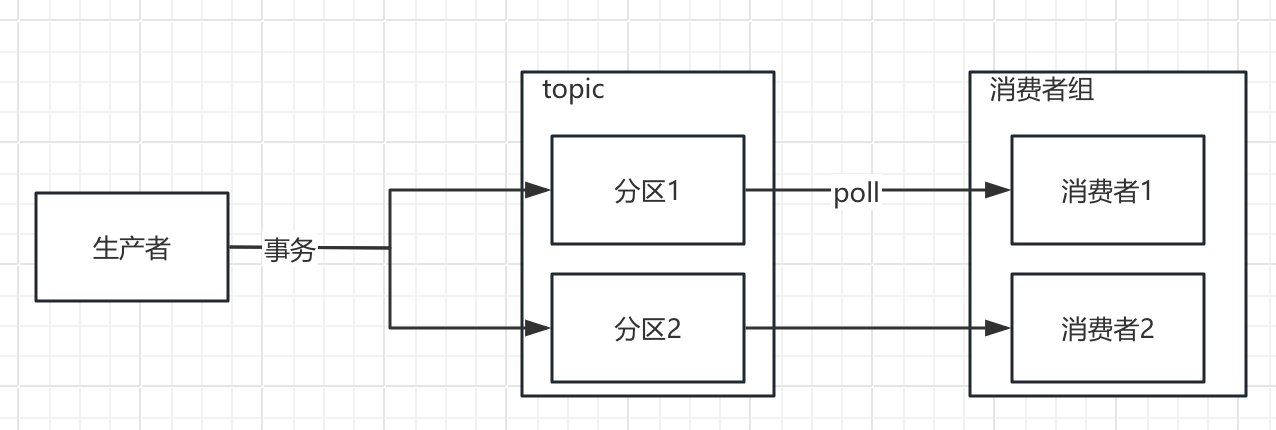
生产者:0/1/n 分区,幂等,与leader交互,批处理
服务器:主题,分区
消费者组-消费者:0/1/n 分区,poll,偏移量
kafka如何实现:恰好一次?
生产者-事务
消费者-分区之能被组内的一个消费者消费
kafka的事务是什么?
kraft是什么?
还需要更多的时间投入。
kafka集群?:Kraft
模拟消费不足
生产者:1s产生一个随机数(5以内)
消费者:拿到随机数就sleep多少秒
先是倒在了:ack上面。
- 自动确认:定时确认
- 手动:poll的一批处理完了再确认
- 立即手动:才是消费一条确认一条
然后是网络问题,无法因为多层NAT,服务器无法通过ip访问到本机端口。只能退而求其次,建立ssh 反向代理。全新的东西:
有哪些方式可以建立反向代理?
ssh的反向隧道: ssh -R 0.0.0.0:9092:localhost:9092 ali
nginx配置代理
除了反向代理还有其他方式让服务器访问到我的本地端口吗?
- 内网穿透工具:frp,Ngrok
- VPN组网
- NAT
- 动态域名+DDns
21:49 exit!
ok 成功模拟:先是通过ssh 建立反向代理,然后服务器内启动容器时,–network host,使用宿主机网络地址(因为宿主机的9092已经被我们ssh反向代理了,容器启动无法再进行映射)。
消费者多线程改造,需要考虑某个线程失败后怎么处理。