并发基础思想
并发编程:
并发:逻辑控制流在时间上与另一个逻辑控制流重叠。
并行:并发的一个真子集,两个逻辑控制流并发的运行在不同的处理器/计算机上。
thread.h
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <stdatomic.h>
#include <assert.h>
#include <unistd.h>
#include <pthread.h>
#define NTHREAD 64
enum { T_FREE = 0, T_LIVE, T_DEAD, };
struct thread {
int id, status;
pthread_t thread;
void (*entry)(int);
};
struct thread tpool[NTHREAD], *tptr = tpool;
void *wrapper(void *arg) {
struct thread *thread = (struct thread *)arg;
thread->entry(thread->id);
return NULL;
}
void create(void *fn) {
assert(tptr - tpool < NTHREAD);
*tptr = (struct thread) {
.id = tptr - tpool + 1,
.status = T_LIVE,
.entry = fn,
};
pthread_create(&(tptr->thread), NULL, wrapper, tptr);
++tptr;
}
void join() {
for (int i = 0; i < NTHREAD; i++) {
struct thread *t = &tpool[i];
if (t->status == T_LIVE) {
pthread_join(t->thread, NULL);
t->status = T_DEAD;
}
}
}
__attribute__((destructor)) void cleanup() {
join();
}
BUG的根源
原子性的消失
状态迁移的确定性消失
我们在高级语言中的原子性操作,经过汇编,cpu内部的原语,到实际的数字逻辑电路执行前,已经被拆分成了多条语句。
#include "thread.h"
int sum = 0;
void hello(int id) {
for (int i = 0; i < 10000; i++) {
sum++;
}
}
int main() {
for (int i = 0; i < 2; i++) {
create(hello);
}
join();
printf("sum = %d
", sum);
}
运行结果示例:
gcc sum.c && ./a.out
sum = 14915
gcc sum.c && ./a.out
sum = 14756
看下最终的可执行文件中的hello部分
objdump -d a.out | less
0000000000001348 <hello>:
1348: f3 0f 1e fa endbr64
134c: 55 push %rbp
134d: 48 89 e5 mov %rsp,%rbp
1350: 89 7d ec mov %edi,-0x14(%rbp)
1353: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
135a: eb 13 jmp 136f <hello+0x27>
135c: 8b 05 de 32 00 00 mov 0x32de(%rip),%eax # 4640 <sum>
1362: 83 c0 01 add $0x1,%eax
1365: 89 05 d5 32 00 00 mov %eax,0x32d5(%rip) # 4640 <sum>
136b: 83 45 fc 01 addl $0x1,-0x4(%rbp)
136f: 81 7d fc 0f 27 00 00 cmpl $0x270f,-0x4(%rbp)
1376: 7e e4 jle 135c <hello+0x14>
1378: 90 nop
1379: 90 nop
137a: 5d pop %rbp
137b: c3 ret
整个sum被分成了
mov 0x32de(%rip),%eax #将sum 从内存中读取到寄存器
add $0x1,%eax #执行+1
mov %eax,0x32d5(%rip) #从寄存器中写回内存
现在再来看一个原子性版本的sum
#include "thread.h"
#define N 100000000
long sum = 0;
void Tsum() {
for (int i = 0; i < N; i++) {
asm volatile("lock addq $1, %0": "+m"(sum));
}
}
int main() {
create(Tsum);
create(Tsum);
join();
printf("sum = %ld
", sum);
}
运行结果如下:
gcc sum-atomic.c && ./a.out
sum = 200000000
再来看下编译后的可执行文件
objdump -d a.out | less
0000000000001348 <Tsum>:
1348: f3 0f 1e fa endbr64
134c: 55 push %rbp
134d: 48 89 e5 mov %rsp,%rbp
1350: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
1357: eb 0d jmp 1366 <Tsum+0x1e>
1359: f0 48 83 05 de 32 00 lock addq $0x1,0x32de(%rip) # 4640 <sum>
1360: 00 01
1362: 83 45 fc 01 addl $0x1,-0x4(%rbp)
1366: 81 7d fc ff e0 f5 05 cmpl $0x5f5e0ff,-0x4(%rbp)
136d: 7e ea jle 1359 <Tsum+0x11>
136f: 90 nop
1370: 90 nop
1371: 5d pop %rbp
1372: c3 ret
先来看一段deepseek对lock addq $0x1,0x32de(%rip)解释:
- 关于lock前缀:
- LOCK是一个x86指令前缀,用于在多核/多线程环境中保证紧跟其后的指令执行的原子性3
- 它会通过拉低CPU的LOCK#引脚电位,在指令执行期间锁定总线或缓存行,防止其他处理器同时访问同一内存区域35
- 现代x86处理器(P6及之后)通常使用缓存锁而非总线锁,仅当操作跨缓存行或数据未缓存时才触发总线锁37
- 支持的指令包括ADD/ADC/AND/XADD等算术逻辑运算,以及CMPXCHG等特殊指令3
- 关于原子性实现:
- 传统非原子操作需要”读-改-写”三步(如示例中的a++操作)6,而LOCK前缀直接将这三步合并为单条原子指令3
- ADDQ指令本身支持内存操作数,配合LOCK前缀后可直接在内存位置完成”读取-加1-写入”的完整原子操作13
- volatile关键字确保编译器不会优化掉这段汇编代码,保证其按预期执行1
- “+m”(sum)约束表示sum变量既是输入又是输出的内存操作数,编译器会正确处理其地址引用
总之现在的sum变成了:lock addq $0x1,0x32de(%rip) ,会锁住内存,然后直接在内存位置完成 读取-加1-写入
即使到了汇编成面,语句在cpu实际执行时,还会进一步被拆分成各种微指令
顺序性的消失
代码按照顺序执行的逻辑消失
经过编译器的优化,实际指令执行的顺序不一定与我们在高级语言中的定义一致。
并没有找到合适的例子,之前的sum运行O2优化,变成了直接+10000
0000000000001220 <hello>:
1220: f3 0f 1e fa endbr64
1224: 81 05 12 2e 00 00 10 addl $0x2710,0x2e12(%rip) # 4040 <sum>
122b: 27 00 00
122e: c3 ret
122f: 90 nop
总之,静态调度在不影响语义的情况下,会对程序的顺序进行调整,这种调整在多线程中可能就会影响语义了。
可见性的消失
全局指令执行顺序的消失
一般我们会假设,线程对内存的都是 立即写入&立即读出 ,基于此假设,对于整个系统存在一个全局的指令执行顺序。但真实的世界,共享内存模型并不满足立即写入与立即读出。
在顺序性的消失中提到了静态调度与动态调度,静态调度我们可以通过代码中加入barrier阻止编译器优化。动态调度,虽然我们有流水线&超量标,有对数据冒险(前后指令有数据依赖,cpu会保证顺序)&控制冒险(走错分支,cpu会丢掉当前指令重新执行正确的指令)的处理。但单个处理器是无法探知到其他处理器对共享内存的修改。
内存模型:硬件内存模型&编程语言内存模型
这里简单介绍下硬件内存模型,编程语言的暂时不介绍,没有实战的死记case,对于我是极其低效的。
X86:
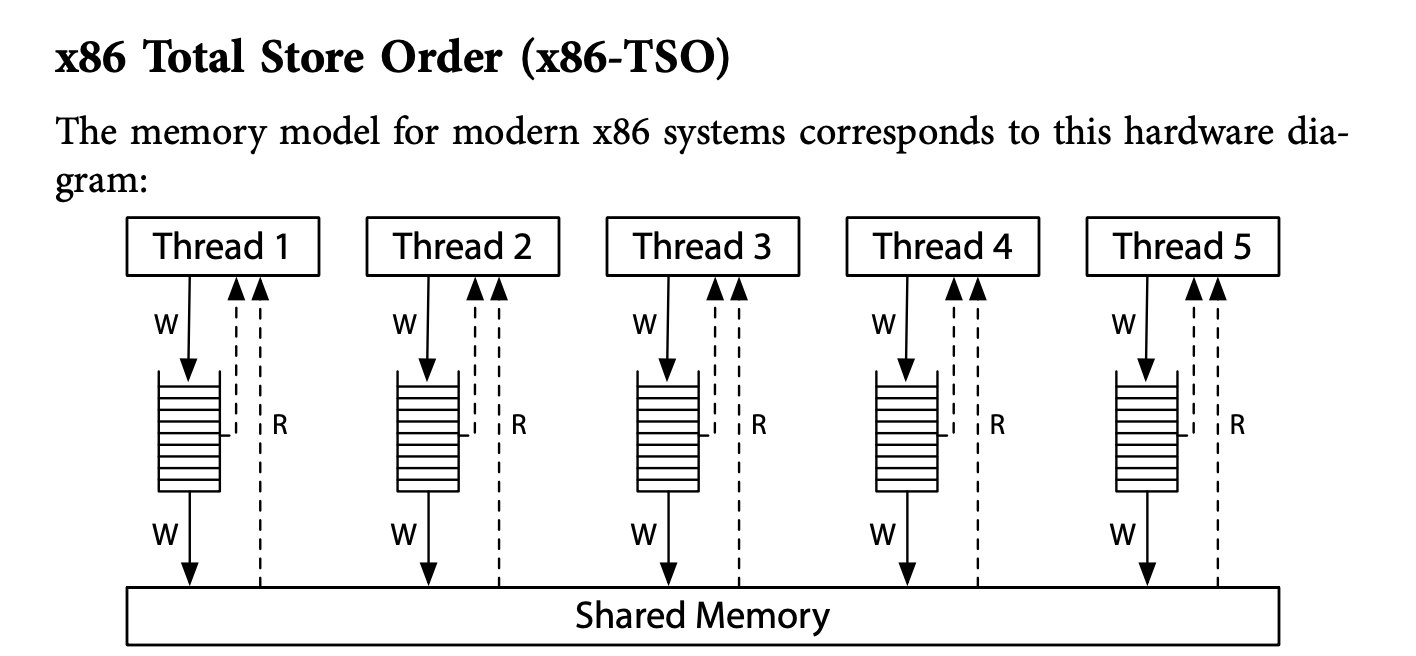
简单介绍下x86的内存模型下的可见性:
//thread1
x = 1;
y = 1;
//thread2
r1 = y;
r2 = x;
在严格的一致性内存模型下:single-use-at-a-time shared memory (处理器直连共享内存,读与写均没有缓存)
永远不会出现r1=1,r2=0
x86架构下,如上图:处理器,读是直接从共享内存读,但每个处理器有属于自己的写缓存。
x86的架构也是不可能出现r1=1,r2=0的情况。内存一致性模型(如Total Store Order)确保了所有处理器看到的写入操作的顺序是一致的。
//thread1
x = 1;
r1 = y;
//thread2
y = 1;
r2 = x;
但是在x86的内存模型下,完全有可能r1=0,r2=0.因为写都在buffer中,读的都是初始化的值。
至于下面的ARM的内存模型,则不提供任何保障。
ARM:
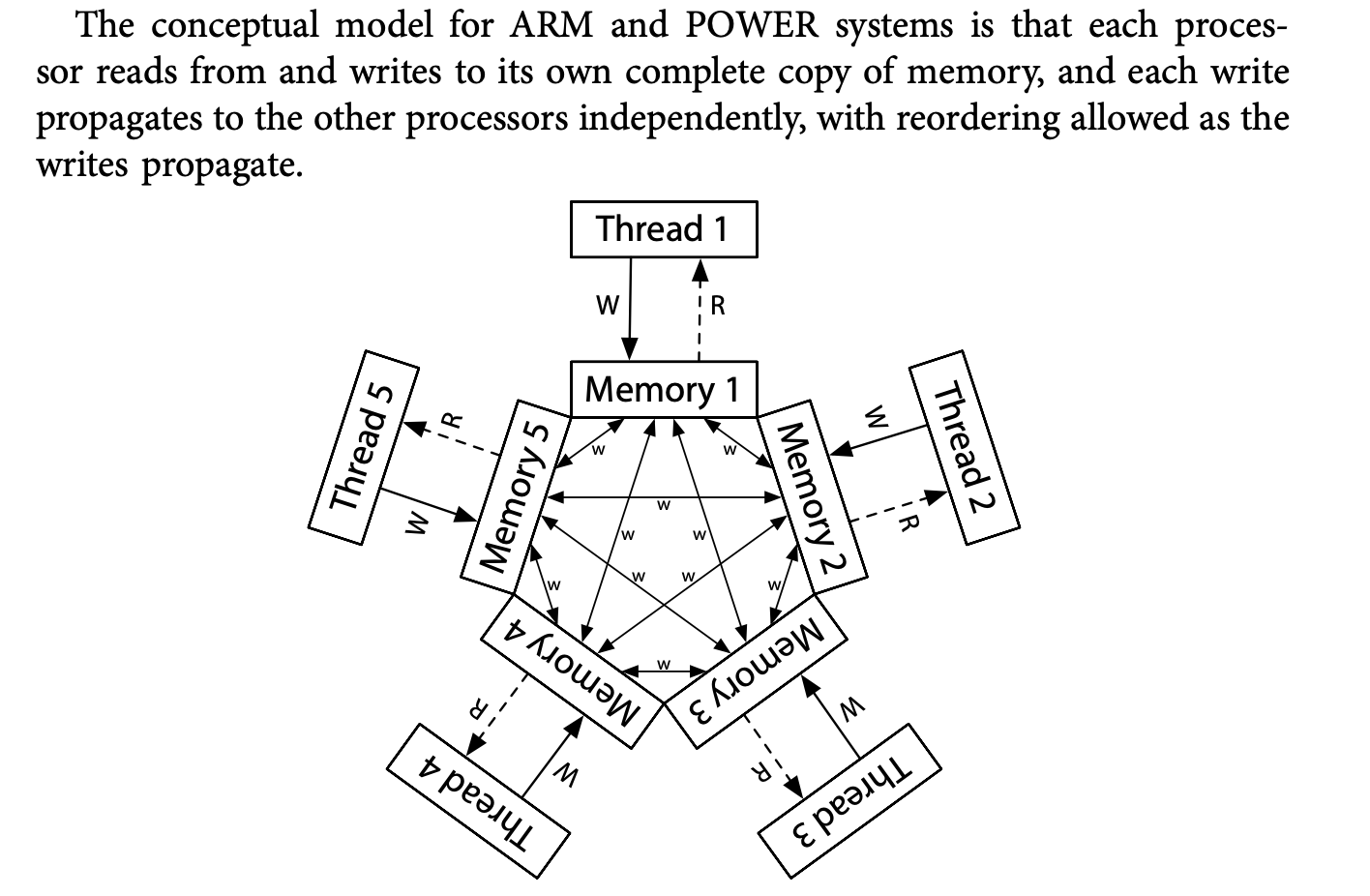
例子:
#include "thread.h"
int x = 0, y = 0;
atomic_int flag;
#define FLAG atomic_load(&flag)
#define FLAG_XOR(val) atomic_fetch_xor(&flag, val)
#define WAIT_FOR(cond) while (!(cond)) ;
__attribute__((noinline))
void write_x_read_y() {
int y_val;
asm volatile(
"movl $1, %0;" // x = 1
"movl %2, %1;" // y_val = y
: "=m"(x), "=r"(y_val) : "m"(y)
);
usleep(1);
printf("%d ", y_val);
}
__attribute__((noinline))
void write_y_read_x() {
int x_val;
asm volatile(
"movl $1, %0;" // y = 1
"movl %2, %1;" // x_val = x
: "=m"(y), "=r"(x_val) : "m"(x)
);
usleep(1);
printf("%d ", x_val);
}
void T1(int id) {
while (1) {
WAIT_FOR((FLAG & 1));
write_x_read_y();
FLAG_XOR(1);
}
}
void T2() {
while (1) {
WAIT_FOR((FLAG & 2));
write_y_read_x();
FLAG_XOR(2);
}
}
void Tsync() {
while (1) {
x = y = 0;
__sync_synchronize(); // full barrier
usleep(1); // + delay
assert(FLAG == 0);
FLAG_XOR(3);
// T1 and T2 clear 0/1-bit, respectively
WAIT_FOR(FLAG == 0);
printf("
"); fflush(stdout);
}
}
int main() {
create(T1);
create(T2);
create(Tsync);
}
Flag 作为标识位,两个bit,00,第一位为1的时候T1执行,然后xor置为0,第二位为1是允许T2执行,然后xor置为0.
当一个输出时,一定写了另外一个。一定有一个1,不可能出现00.
对这个的理解需要一点时间:我需要再过一遍…
服务器太弱了? 完全在服务器上复现不了
model checker
Todo
临界区
对于并发,终极的问题就在与对共享资源的利用,用jyy的例子,就是多人去抢占一个厕所。如果我们给每个人都配了一个厕所自然没有并发的问题。所有对并发的解决都是通过将共享资源串行化使用。真实的世界每个人都是并发的,各自处理各自的生活,可对于有限的共享资源厕所而言,大家都是在串行使用的。
临界区就是操作共享资源的代码片段。这里贴一个csapp中的配图
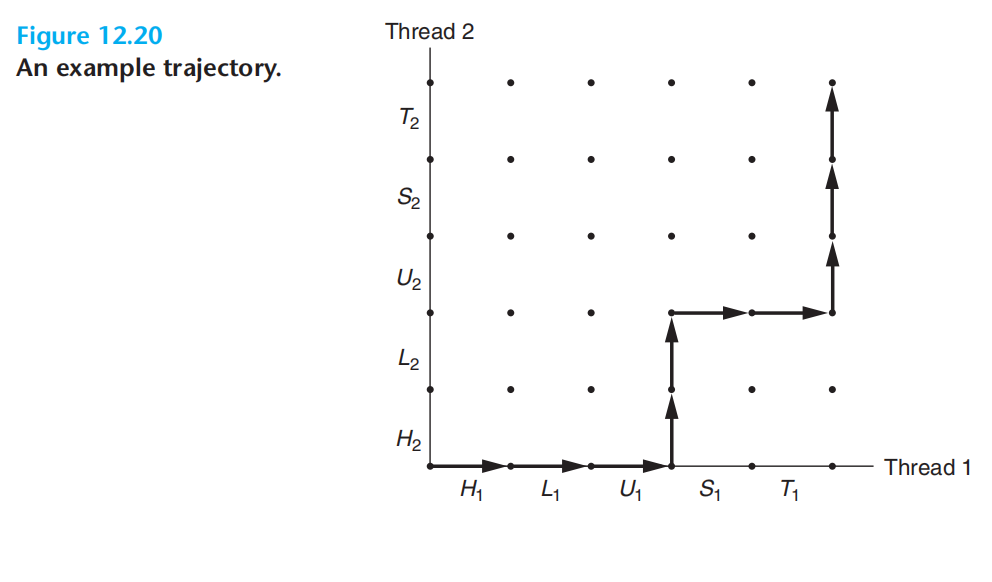
上面的图,描述了两个线程的执行流,每一段就是cpu的时间片。线程1从h1到t1在x轴表示。线程2从h2到t2在y轴表示。
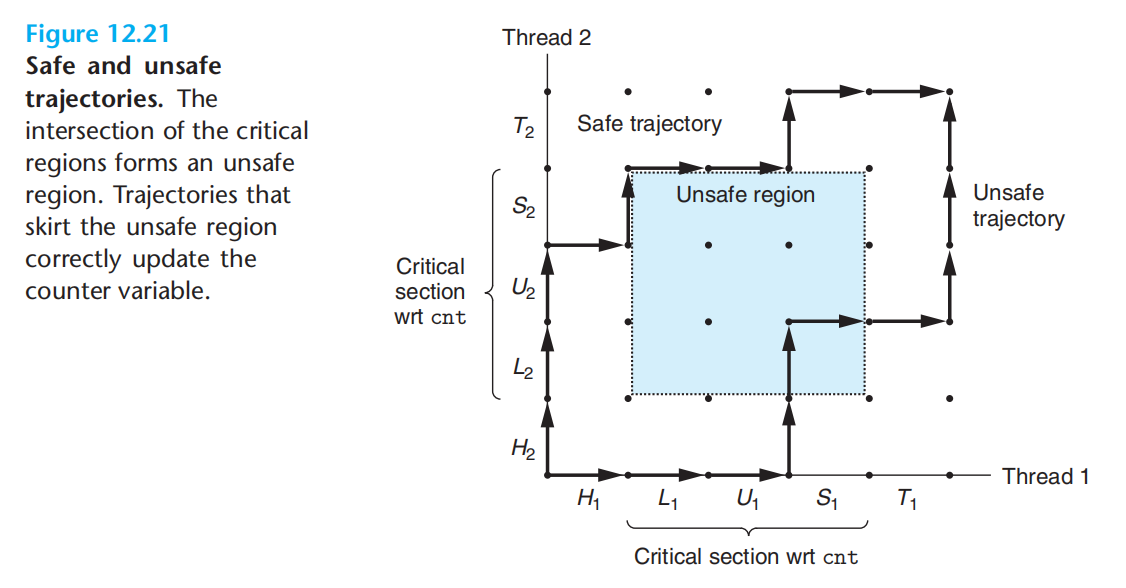
任何对临界区的穿越都违反了临界区的串行要求。
真实世界的并发模型,及我们对临界区资源的串行化访问要求,需要我们对线程进行一些控制:互斥&同步
互斥
互斥的困难:不能同时 读/写 共享内存。
硬件提供原子指令:load & store :https://en.cppreference.com/w/cpp/header/stdatomic.h
void Tsum() {
for (int i = 0; i < N; i++) {
asm volatile("lock addq $1, %0": "+m"(sum));
}
}
x86汇编指令:lock 前缀 确保了原子性&内存屏障
一般抽象模型:
load:看看四周是否允许
exec:开始行动
store: 保存结果
因为不能同时读写内存
load后,马上闭眼,开始exec时,别人可能已经改动了状体
store时,不能读,可能别人覆盖了我们的exec,存成别人的了
软件不够,硬件来凑:提供原子化的:load-exec-store
锁的基本思想:一个变量,为程序员提供了最小程度的调度控制。
锁的最底层是依靠硬件的支持,硬件层面提供类似下述操作的原子版本:x86的xchg等等
int test_and_set(int *old_ptr, int new) {
int old = *old_ptr;
*old_ptr = new;
return old;
}
int CompareAndSwap(int *ptr, int expected, int new) {
int original = *ptr;
if (original == expected)
*ptr = new;
return original;
}
有了硬件提供的原子性支持,就可以开始自己构建锁了。
先来个最简单的自旋锁 spin lock:
int locked = 0;
void lock() {
while (xchg(&locked, 1)) ;
}
void unlock() {
xchg(&locked, 0);
}
tips:xchg返回的是旧的值,当旧值为1时(标明别人在用)一直循环,直到自己将其至为1并返回0;
自旋锁糟糕在自旋🫠:while会消耗大量的cpu时间片 + 获取了锁的线程还是有可能被切出去。优点在于简单。
互斥锁mutex:
既然自旋白白消耗了cpu时间片,那我搞个队列,发现线程没有获取到锁就扔进睡眠队列,释放cpu资源,但操作系统发现锁释放了后就唤醒队列中沉睡的线程,再次竞争。
futex = mutex + spin lock
futex是什么?
todo…
自旋锁:
更快的fast path:xchg成功,直接进入临界区
更慢的slow path:xchg失败,不停的自旋
睡眠锁:
更慢的fast path:上锁成功,也需要进入内核走一遭(将锁标记为已持有)
更快的slow path:上锁失败,进入内核睡眠
futex:
fast path:用户空间,一条原子指令,上锁成功就返回
slow path:上锁失败,进入内核
同步
互斥已经确保了共享资源的串行化访问,同步则对多个线程之间提供更强的控制
条件变量
一个队列,不满足条件,线程加入队列,条件满足时,线程被唤醒。
signal(&condition):唤醒一个在条件变量对应的队列中睡眠的线程
wait:将线程放进等待队列并释放锁
while(done == 0) {
wait(&conditon, &lock)
}
broadcast:唤醒所有在该条件上等待的线程
信号量
P -1 & V +1
来一段jyy oslab手搓的信号量:
void kmt_sem_init(sem_t *sem, const char *name, int value) {
sem -> lock = pmm -> alloc(sizeof(sem_t));
kmt_spin_init(sem -> lock, "semaphore`s spin_lock");
sem -> count = value;
sem -> name = name;
}
//-1,<0 wait
void kmt_sem_wait(sem_t *sem) {
//获取锁
kmt_spin_lock(sem -> lock);
//-1
sem -> count--;
if (sem -> count < 0) {
//标记当前线程不可再执行
task_t *cur = my_task();
cur -> status = BLOCKED;
debug("task: %s status asign to %d", cur->name, cur->status);
//将当前线程加入semaphore的等待队列
struct link_task *wait = pmm -> alloc(sizeof(struct link_task));
wait -> task = cur;
wait -> next = sem -> wait_task;
sem -> wait_task = wait;
debug_sem(sem, "sem_wait");
}
//释放锁
kmt_spin_unlock(sem -> lock);
if (sem -> count < 0) {
//中断
yield();
}
}
//+1,wake one that on waiting
void kmt_sem_signal(sem_t *sem) {
//获取锁
kmt_spin_lock(sem -> lock);
//+1
sem -> count++;
//唤醒一个正在等待的线程
if (sem -> count <= 0) {
struct link_task *cur_wait = sem -> wait_task;
if (cur_wait) {
debug("sem %s, cur_wait task name = %s, status = %d
", sem->name, cur_wait->task->name, cur_wait->task -> status);
assert(cur_wait -> task -> status == BLOCKED);
cur_wait -> task -> status = RUNNABLE;
sem -> wait_task = cur_wait -> next;
pmm -> free(cur_wait);
debug("task: %s status asign to RUNNABLE", cur_wait -> task ->name);
debug_sem(sem, "signal");
}
}
kmt_spin_unlock(sem -> lock);
if (sem -> count <= 0) {
yield();
}
初始化为1的=锁
初始化为0 = 条件变量
生产者&消费者
基于锁:
#include "thread.h"
#include "thread-sync.h"
int n, count = 0;
mutex_t lk = MUTEX_INIT();
void Tproduce() {
while (1) {
retry:
mutex_lock(&lk);
if (count == n) {
mutex_unlock(&lk);
goto retry;
}
count++;
printf("(");
mutex_unlock(&lk);
}
}
void Tconsume() {
while (1) {
retry:
mutex_lock(&lk);
if (count == 0) {
mutex_unlock(&lk);
goto retry;
}
count--;
printf(")");
mutex_unlock(&lk);
}
}
int main(int argc, char *argv[]) {
assert(argc == 2);
n = atoi(argv[1]);
setbuf(stdout, NULL);
for (int i = 0; i < 8; i++) {
create(Tproduce);
create(Tconsume);
}
}
基于条件变量:
#include "thread.h"
#include "thread-sync.h"
int n, count = 0;
mutex_t lk = MUTEX_INIT();
cond_t product = COND_INIT();
cond_t consum = COND_INIT();
void Tproduce() {
while (1) {
mutex_lock(&lk);
while (count == n) {
cond_wait(&product, &lk);
}
printf("("); count++;
cond_signal(&consum);
mutex_unlock(&lk);
}
}
void Tconsume() {
while (1) {
mutex_lock(&lk);
while (count == 0) {
pthread_cond_wait(&consum, &lk);
}
printf(")"); count--;
cond_signal(&product);
mutex_unlock(&lk);
}
}
int main(int argc, char *argv[]) {
assert(argc == 2);
n = atoi(argv[1]);
setbuf(stdout, NULL);
for (int i = 0; i < 8; i++) {
create(Tproduce);
create(Tconsume);
}
}
基于信号量:
#include "thread.h"
#include "thread-sync.h"
int n = 0;
sem_t* sem_producer;
sem_t* sem_consumer;
void Tproduce() {
while (1) {
P(sem_producer);
printf("(");
V(sem_consumer);
}
}
void Tconsume() {
while (1) {
P(sem_consumer);
printf(")");
V(sem_producer);
}
}
int main(int argc, char *argv[]) {
assert(argc == 2);
n = atoi(argv[1]);
assert(n > 0);
setbuf(stdout, NULL);
sem_producer = malloc(sizeof(sem_t));
sem_consumer = malloc(sizeof(sem_t));
SEM_INIT(sem_producer, n);
SEM_INIT(sem_consumer, 0);
for (int i = 0; i < 8; i++) {
create(Tproduce);
create(Tconsume);
}
}
总结
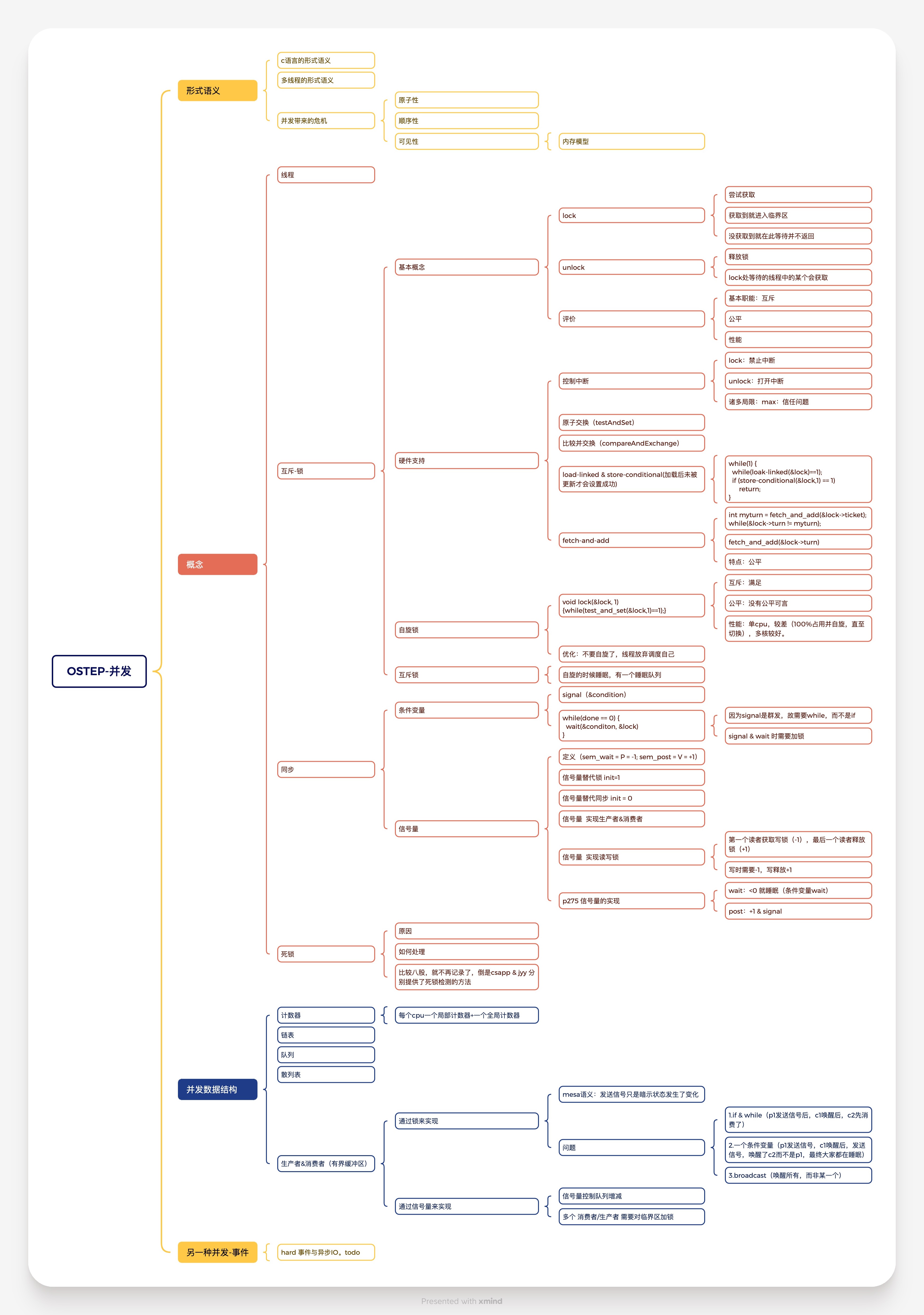
基于事件的并发
Crux :不用线程,如何构建并发服务器
1.等待某事发生
2.检查事件类型
3.处理事件
while (1) {
events = getEvents();
for (e in events)
processEvent(e);
}
linux的IO多路复用
- select / poll 是通过轮询fd来通知对应事件
- epoll fd就绪,通过中断通知对应线程
java中的锁
前面提到通过锁来控制共享资源实现串行访问,同步则是控制线程调度。
锁的实现,本质是通过cpu提供的原子操作结合内存中的某个位置,实现排他性。被锁包起来的代码就是临界区。
关于java中的并发部分,此处并不打算做一个大而全的总结显得非常的verbose,API的部分及内存模型等非常细节的也不打算纳入,这些东西永远应该是使用的时候才去查找。
java中的互斥:
synchronized:
自动加锁,修饰静态方法时等同锁住了Class对象,修饰其他方法时等同锁住了this对象
synchronized与管程模型:
在介绍这一部分之前,先来一张JVM总览:
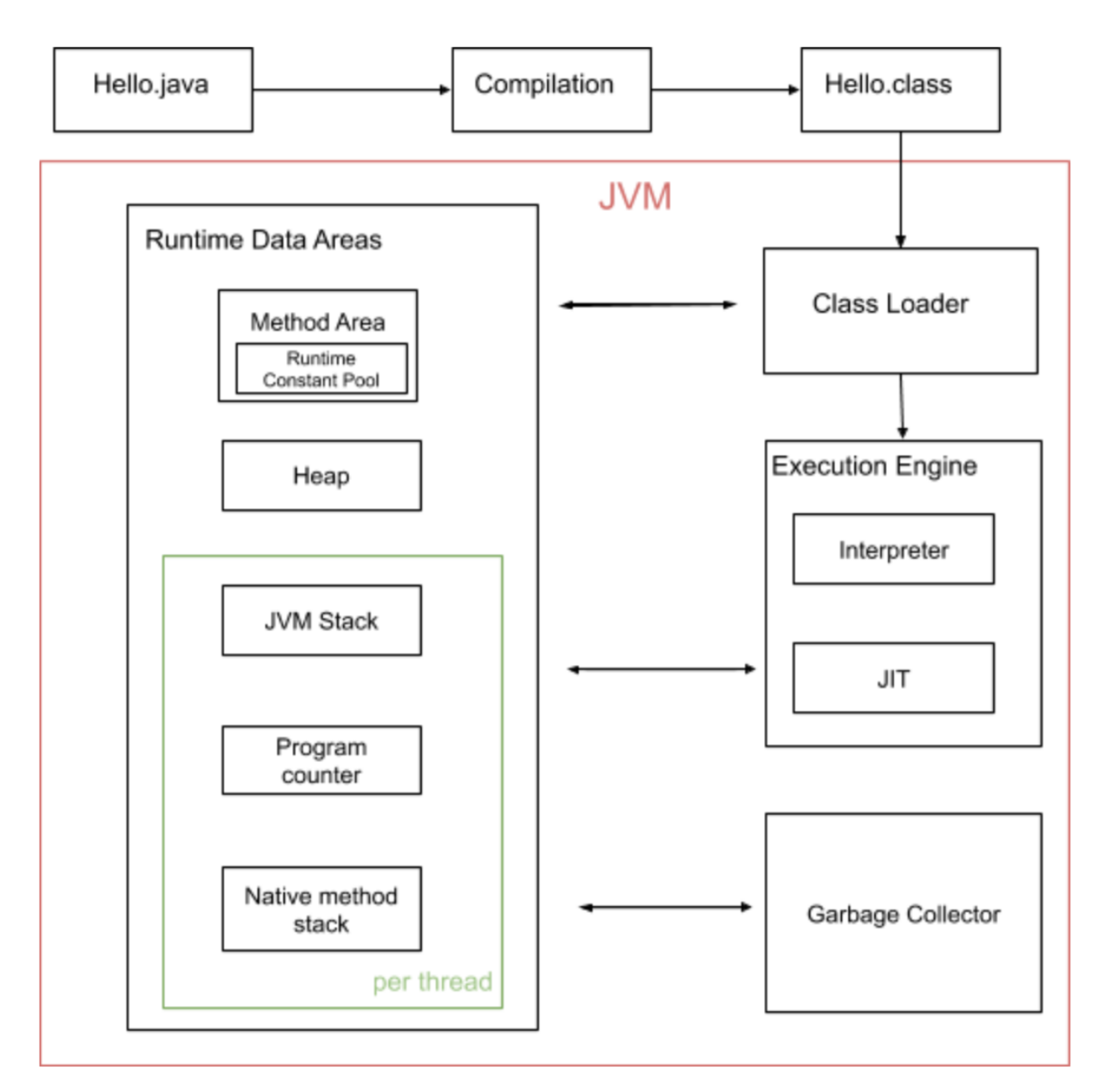
众所周知,java中的对象都是存放在heap中的,再细化一下JVM的内存结果:
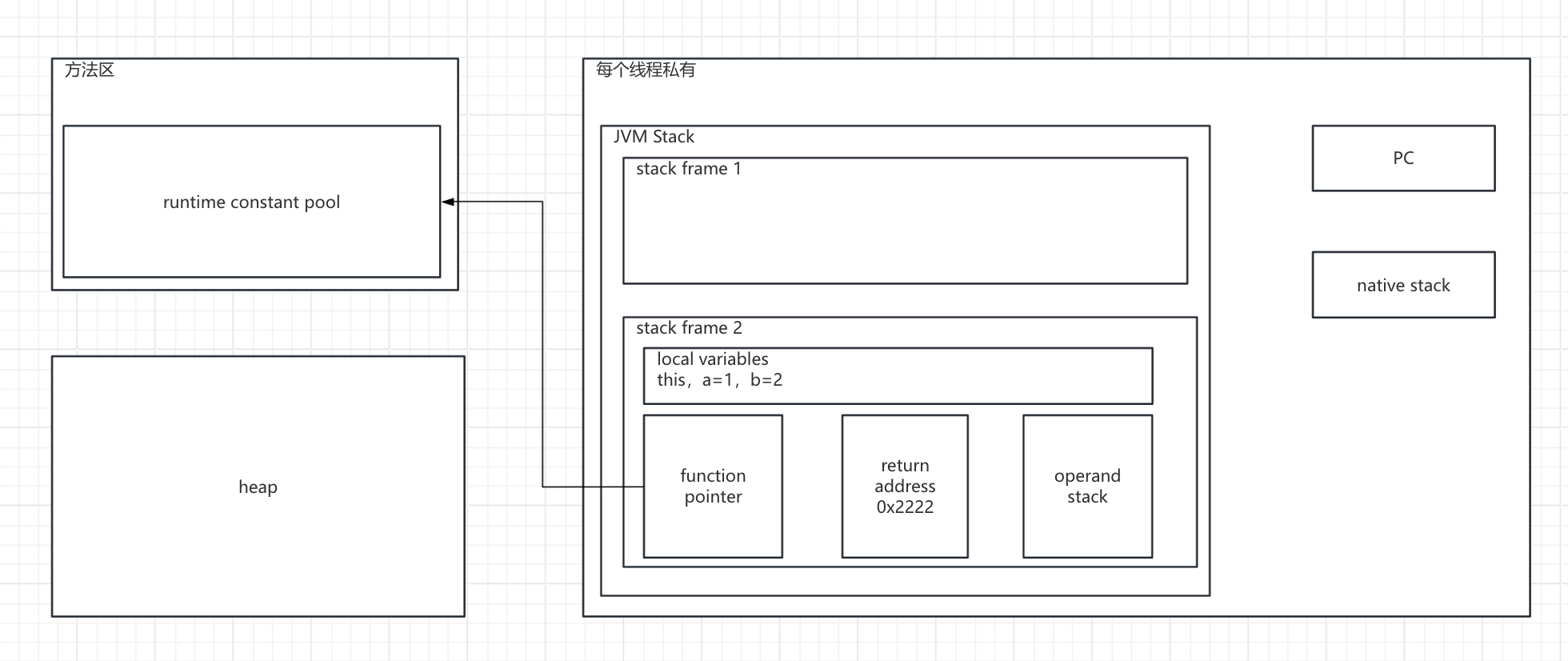
在多线程中,heap是线程共享的,也就是所有涉及的对象都是不安全的,如果涉及到修改,需要串行化。
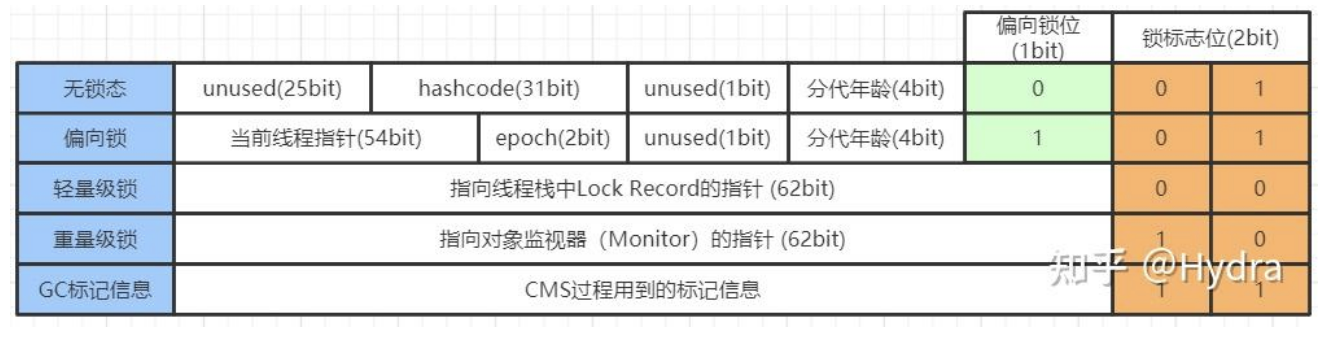
在c中一般struct占用的内存就是里面各个属性占用的内存之和。java会多一个对象头,非数组的java对象,对象头=8字节标记位+8字节类型指针(指向方法区)。
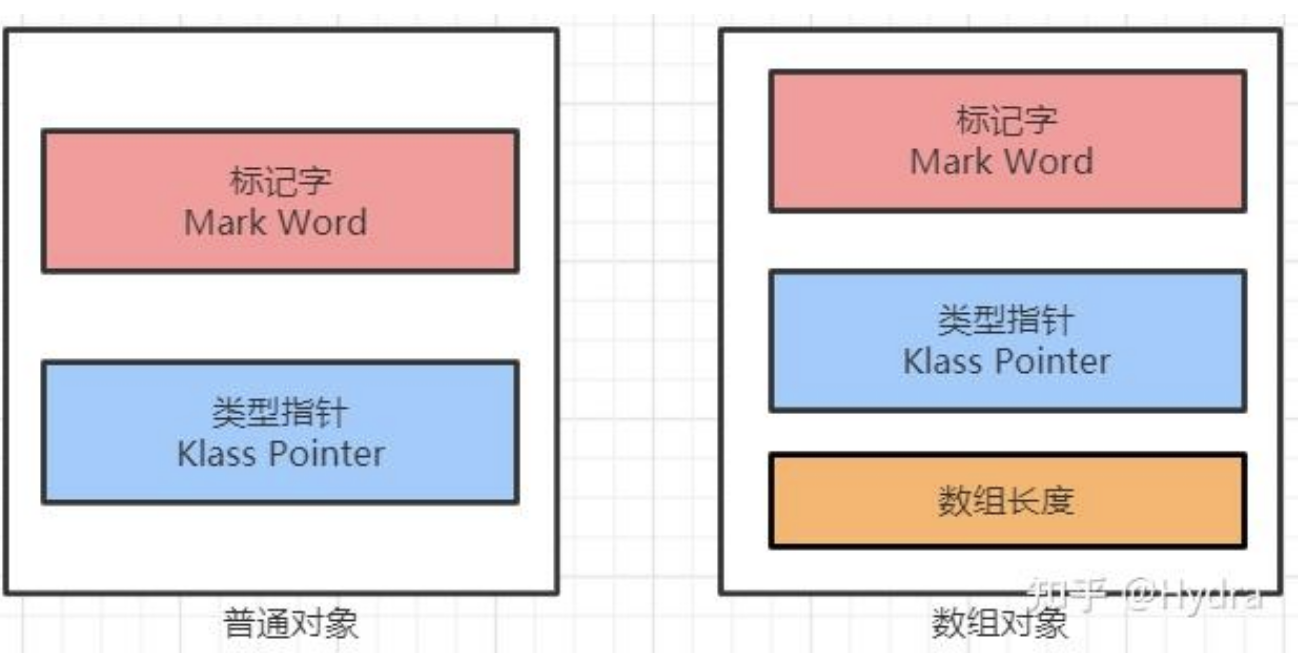
其中8字节的64bit标记位就与锁有关:
管程模型就是:
临界区+临界区对应的等待队列
MESA,模型新增了条件队列,条件队列就是一个队列,人为控制将线程放进去并睡眠or唤醒
java则是只有一个条件队列
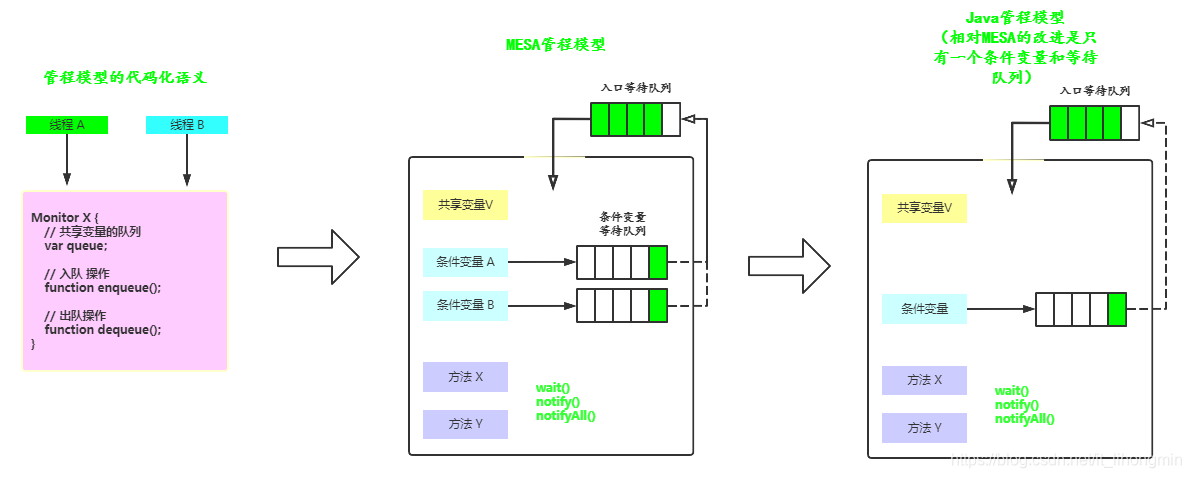
每一个java对象都有一个隐式监视器锁,及与之对应的入口等待队列
同时对象还一个隐式的条件队列,通过wait/notifyAll等入队/唤醒
使用隐式条件队列,需要线程拥有对象的隐式监视器锁
交互:
- 线程尝试获取synchronized绑定的对象的锁
- 没有获取到就进入对象的入口等待队列
- 获取到就进入临界区
- 如果临界区内,wait,会进入对象的条件队列
- 临界区内notifyAll,线程会被唤醒从条件队列扔进入口等待队列
synchronized 锁的是this对象或者Class对象,同时提供了入口等待队列+条件等待队列
ReentrantLock:
JDK提供的锁
lock负责互斥,condition负责同步,因为condition来自lock,确保了一定要获取锁才能对条件变量进行操作。
剩下的关于java中哪些极其庞大而又复杂的各类锁,及各类并发数据结构,乃至并发算法等,超出了我现阶段的要求了,强制去背,也仅仅只是知道,远谈不上理解。一看见各类面经就头大😅…
mysql中的锁
innodb为例
互斥的唯一目的就是实现对共享资源的串行化访问。
1.mysql锁有哪些类型?
2.不同类型的锁分别锁的是什么?
按照细粒度:
0.库级全局锁
阻塞线程操作
1.表锁
锁的是表对象的元数据
2.行锁
next-key
(5,10] 锁的是 5之后到10的间隙 + 10本身
gap lock
锁的是区间
record lock
锁的是具体的记录
整个锁,都可以简化理解为是加在索引上面的
如果使用的二级索引,会先锁该索引,再锁主键索引。