程序如何之为可能(todo)
这篇文章,其实老早之前就写了,一直不太满意,可是又没有分太多的时间细细打磨,秉着「完成比完美更重要」的原则,先弄出来,当作一个todo挂在这里。
程序如何之为可能
当我们在编写代码的时候,我们究竟在干什么?
当我们在执行代码的时候,电脑到底发生了什么?
所有的一切如何成为可能的呢?
我们编写了一段代码 hello.c:
#include <stdio.h>
#include <assert.h>
int main(void)
{
assert(1 == 1);
printf("hi, buddy!
");
return 0;
}
只需要gcc hello.c 然后 ./a.out 终端上立即就会输出 :hi, buddy!
gcc hello.c && ./a.out
hi, buddy!
但是,在这表象之下到底发生了什么呢?我们在键盘上敲下按键,如何变成屏幕上的字符,并最终转换为电信号,跑完逻辑电路,然后输出的?
计算机系统漫游
物理机
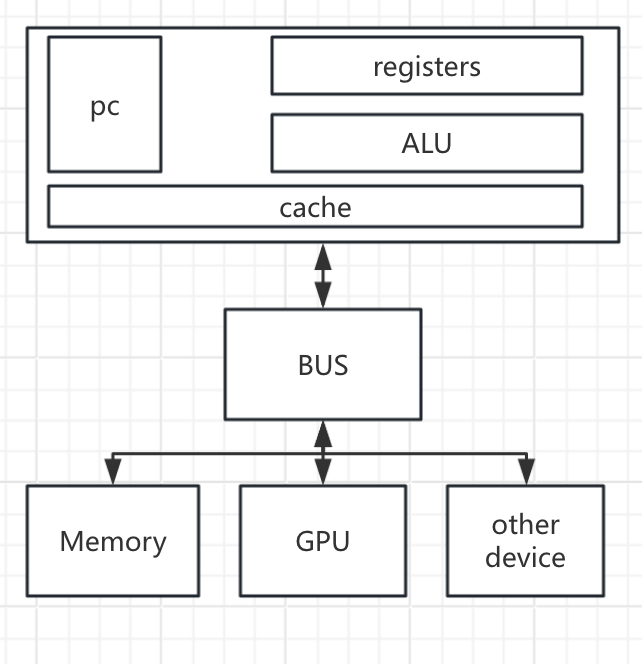
我们首先对物理机进行抽象,将其定义为:
cpu+bus总线+外围设备
cpu:缓存+pc寄存器+寄存器+计算单元
设备:一组特定功能的线+寄存器 (更一般的抽象:状态寄存器,指令寄存器,数据寄存器)
bus:设备太多了,将设备注册到bus中,统一管理(cpu:请bus将第三个插槽的第6个寄存器的值给我),甚至可以给设备寄存器分配不同地址空间
虚拟机
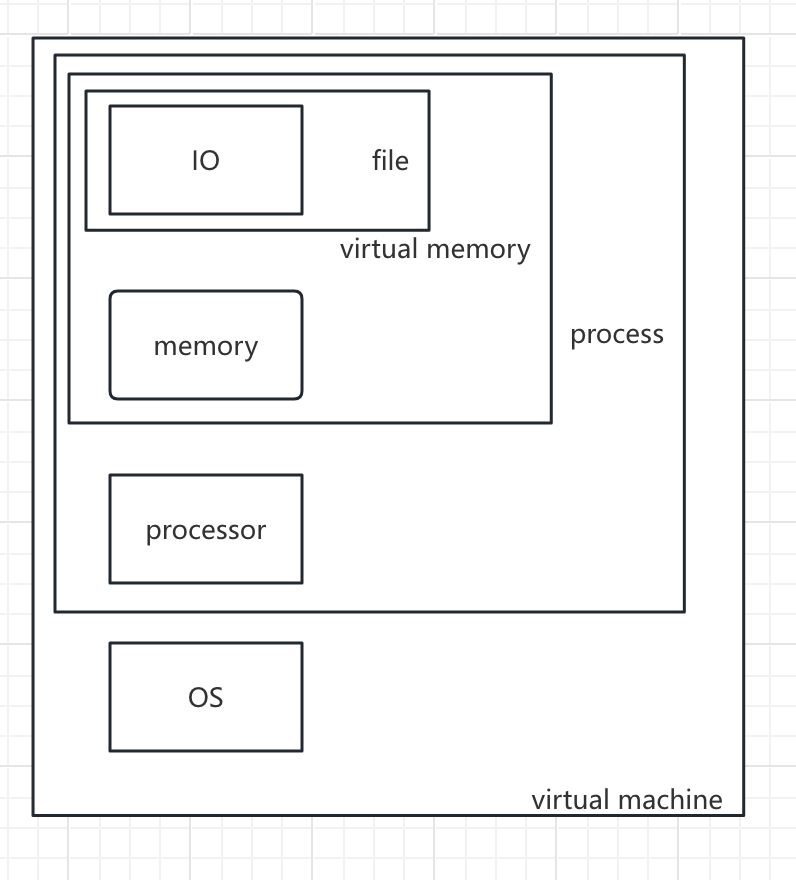
IO设备:为我们提供了文件这个概念
磁盘+内存= 虚拟地址空间
虚拟内存+虚拟CPU = 进程
进程+OS = 虚拟机
程序
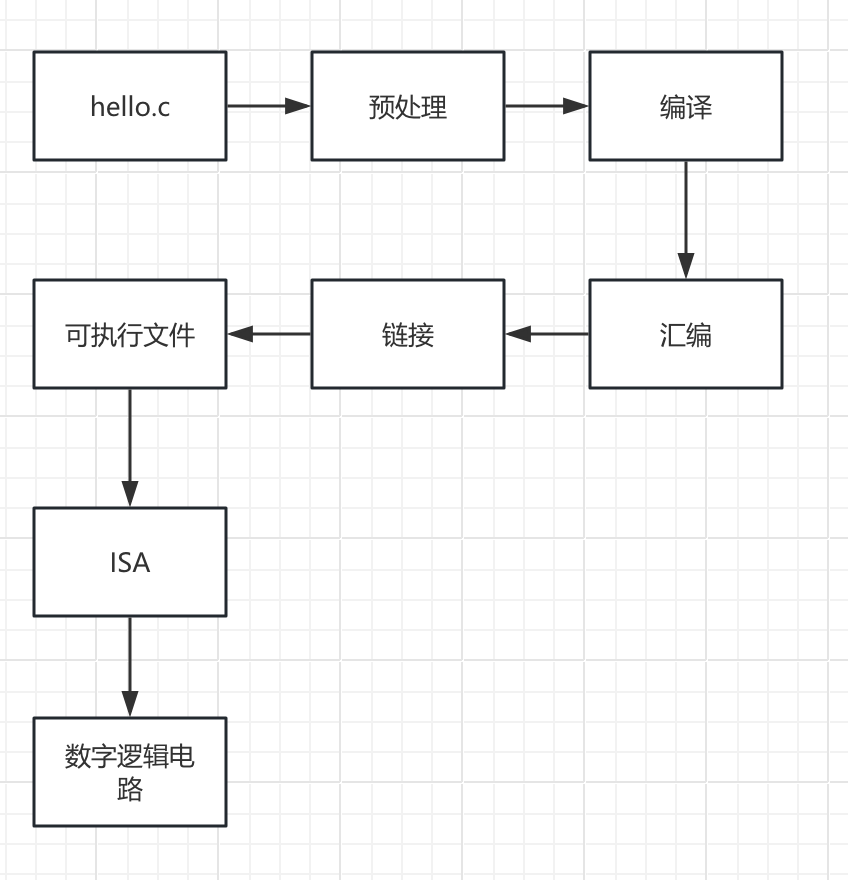
高级语言:信息=特定上下文下的比特序列
预处理:宏之类
编译:编译成汇编语言
汇编:带有符号的目标文件
链接:将符号转化为具体地址,真正的可执行文件
ISA:指令集体系,指令集体系上面是软件是对指令集的各种抽象,下面则是数字逻辑电路负责实现语义
并发与并行
并发:执行逻辑流上存在交叉。逻辑流在时间上与另一个逻辑流重叠。
线程级别并行:多处理器,并行就是并发运行在不同的处理器上。
指令级并行(Prompt:现代cpu提供的指令级并行是什么):一条指令产生多个并行执行的操作
大纲
1.只有0和1这段代码如何成为可能?(信息的表示)
编译
链接
为什么要./a.out 而前面只需要gcc 就行了,不需要指定是那个路径下的gcc,为什么?
2.是怎么变成a.o的?(链接)
3.为什么地址是从0x4…开始的?(虚拟内存)
4.按下./a时操作系统发生了什么?(shell 与进程&并发)
5.磁盘上路径下的a.out是如何被加载到内存?(存储体系&文件系统& 异常 & 中断)
6.PC是如何跳转的?
7.cpu是如何执行哪些指令的?
8.操作系统是如何运行起来的
信息的表示
0和1与万物:code-隐匿在计算机软硬件背后的语言
众所周知,计算机中只有0和1,高电压与低电压是如何构成我们今天的一切呢?比特序列是如何表达了今天的万事万物呢?
人类社会中,文字作为信息的载体,计算机世界中,比特序列则作为信息的载体。单个的比特位一般不能包含太多的信息,可一但按照特定的序列将其组合起来,并赋予解释,一切便就有了意义。(世间本无意义,人去赋予了一切意义。比特序列本无意义,规则赋予了其意义🫠)
这里的关键概念在于规则:
- 字符
- ascii
- utf-8
- GBK
- 无符号整数数
- 二进制
- 有符号整数
- 补码(解释了为什么是-128到正的127 ,而不是正负128/127)
- 浮点数IEEE浮点数
- [S·E·M]= -1^s^ *2^e^ *f

在汇编层面,并不存在什么long类型,int 类型,所有的一切都是对比特序列的解读。 为什么溢出会变成负数? 数字之间的类型转换(无符号转有符号,32位整数转64位整数等)是什么? 为什么浮点数不精确? 所有一切的答案都是因为规则定义。 不同类型的文件,都是遵从不同规则的比特序列。我们定义了一个又一个数据结构,通过这个数据结构来表达并描述现实
世界真实存在的物质,从而完成了现实世界到计算机世界的映射。 一个典型的例子就是字符串转数字:
man ascii 即可得知:字符串中的0~9,在ascii编码规则中使用的是数字48~57来表示。
#include <stdio.h>
#include <assert.h>
int main(int argc, char *argv[])
{
assert(argc > 1);
char* str = argv[1];
int result = 0;
while (*str != '\0') {
result = result * 10 + (*str- 48);
str += 1;
}
printf("转换结果: %d
", result);
return 0;
}
gcc str2num.c && ./a.out 1357
转换结果: 1357
已经了解了信息的表示,接下来就是讲解我们的代码片段是如何变成可执行文件的
从代码到可执行文件
基本步骤:
- 预处理
- 编译成汇编文件
- 汇编成可重定位目标文件
- 链接成可执行目标文件
汇编代码可以理解为对预处理后文件的翻译
可重定位文件就是对汇编代码的进一步翻译与组织,翻译成机器码并区分出txt段,data段等
最终可执行文件就是将可重定位文件中的符号引用翻译成具体的地址(相对/绝对)
链接的输入是可重定位目标文件,输出是可执行目标文件/共享目标文件
静态链接,直接输出可执行目标文件,此时所有的符号都已经变成了地址
动态链接,则是输出共享目标文件,通过GTO&PLT 运行时解析
也就是,对于可重定位目标文件,静态链接与动态链接 各自的结构有一些差异
预处理
gcc -E hello.c -o hello.i
int main(void)
{
# 6 "hello.c" 3 4
((void) sizeof ((
# 6 "hello.c"
1 == 1
# 6 "hello.c" 3 4
) ? 1 : 0), __extension__ ({ if (
# 6 "hello.c"
1 == 1
# 6 "hello.c" 3 4
) ; else __assert_fail (
# 6 "hello.c"
"1 == 1"
# 6 "hello.c" 3 4
, "hello.c", 6, __extension__ __PRETTY_FUNCTION__); }))
# 6 "hello.c"
;
printf("hi, buddy!
");
return 0;
}
可以看到assert宏被展开了。
编译成汇编代码
gcc -S hello.i -o hello.s
.file "hello.c"
.text
.section .rodata
.LC0:
.string "hi, buddy!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
leaq .LC0(%rip), %rax
movq %rax, %rdi
call puts@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
编译行为将c语言翻译成汇编代码,此时我们看到的还是一个文本文件,虽然GCC给里面添加了各种伪指令,甚至还有.text,.section, .rodata等信息,此时依然是一个文本,不具备elf数据结构。
这个阶段有一个非常重要的事情:静态调度
我们来看下O2优化下的代码
gcc -O2 -S hello.i -o hello.s
.file "hello.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "hi, buddy!"
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
leaq .LC0(%rip), %rdi
call puts@PLT
xorl %eax, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
具体的差异,我也没去了解过🤣,总之关于静态调度的部分,发生在编译器将c文件翻译成汇编语言的阶段。
编译可以理解为一种函数映射,在输入的c代码,输出的是汇编代码,二者的语义相同。在这里jyy提供了一种全新的思想:状态机视角下的c与汇编。
c语言的形式语义:地址空间+语句
todo:一张配图
汇编的形式语义:寄存器+指令
todo:一张配图
现在我们要做的就是在保证关键节点一致的情况下,在二者间建立映射关系。
todo:一张配图
对于编译原理暂时没有了解过,不过了解过其青春版:REPL(scip中有介绍,用scheme语言实现一个REPL)
如何对表达式进行求值呢?
例如:1+2*3-4/5
1.需要求解1 +(2 * 3) - (4/5):将原本的表达式拆分成 A+B-C的形式(一棵二叉树,树的叶子节点就是基本的不可拆分的表达式)
2.进一步求值B=2*3 = 6
3.进一步求值C=4/5=0.8
4.最终得到:1+6-0.8 =6.2
大致是这样,可以看下xv6中的shell实现,代码就不贴了。
汇编成可重定位目标文件
这个可是重头戏,当初第一次看时很懵逼。
因为链接分为:静态链接,与动态链接,生成的可重定位目标文件虽然都是elf格式,不过有些微的差距。
这里先问一个问题:elf文件是什么?
elf文件就是一个数据结构,其相关定义在elf.h中。这个数据结构包含前面的汇编相关指令,还有一些额外信息用于辅助后面的链接,及更后面的程序执行。
重定位目标文件-静态链接
gcc -c hello.s -o hello.o
此时我们得到的是真正的二进制文件了,vi打开看到的是乱码。
readelf可以查看elf文件
readelf -a hello.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 616 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 15
Section header string table index: 14
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 WA 0 0 1
[ 3] .bss NOBITS 0000000000000000 00000040
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .rodata.str1.1 PROGBITS 0000000000000000 00000040
000000000000000b 0000000000000001 AMS 0 0 1
[ 5] .text.startup PROGBITS 0000000000000000 00000050
000000000000001b 0000000000000000 AX 0 0 16
[ 6] .rela.text.s[...] RELA 0000000000000000 00000190
0000000000000030 0000000000000018 I 12 5 8
[ 7] .comment PROGBITS 0000000000000000 0000006b
000000000000002c 0000000000000001 MS 0 0 1
[ 8] .note.GNU-stack PROGBITS 0000000000000000 00000097
0000000000000000 0000000000000000 0 0 1
[ 9] .note.gnu.pr[...] NOTE 0000000000000000 00000098
0000000000000020 0000000000000000 A 0 0 8
[10] .eh_frame PROGBITS 0000000000000000 000000b8
0000000000000030 0000000000000000 A 0 0 8
[11] .rela.eh_frame RELA 0000000000000000 000001c0
0000000000000018 0000000000000018 I 12 10 8
[12] .symtab SYMTAB 0000000000000000 000000e8
0000000000000090 0000000000000018 13 4 8
[13] .strtab STRTAB 0000000000000000 00000178
0000000000000018 0000000000000000 0 0 1
[14] .shstrtab STRTAB 0000000000000000 000001d8
0000000000000089 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)
There are no section groups in this file.
There are no program headers in this file.
There is no dynamic section in this file.
Relocation section '.rela.text.startup' at offset 0x190 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000b 000300000002 R_X86_64_PC32 0000000000000000 .LC0 - 4
000000000010 000500000004 R_X86_64_PLT32 0000000000000000 puts - 4
Relocation section '.rela.eh_frame' at offset 0x1c0 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text.startup + 0
No processor specific unwind information to decode
Symbol table '.symtab' contains 6 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS hello.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 5 .text.startup
3: 0000000000000000 0 NOTYPE LOCAL DEFAULT 4 .LC0
4: 0000000000000000 27 FUNC GLOBAL DEFAULT 5 main
5: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts
No version information found in this file.
Displaying notes found in: .note.gnu.property
Owner Data size Description
GNU 0x00000010 NT_GNU_PROPERTY_TYPE_0
Properties: x86 feature: IBT, SHSTK
elf文件的各部分解释:交给AI
我们的代码被放在了.text段中可以objdump -d查看[Disassembly of section .text.startup]
objdump -d hello.o
hello.o: file format elf64-x86-64
Disassembly of section .text.startup:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 48 83 ec 08 sub $0x8,%rsp
8: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # f <main+0xf>
f: e8 00 00 00 00 call 14 <main+0x14>
14: 31 c0 xor %eax,%eax
16: 48 83 c4 08 add $0x8,%rsp
1a: c3 ret
这里先介绍下可重定位条目:
1.可重定位条目是什么?
我们在文件中调用了外部的函数,此时没有没法知道外部函数的具体地址,只能打一个标记。后续对标记进行解析。这些标记就是重定位条目。(注意,此时讲的是静态链接)
2.我们如何在elf格式文件中查看该条目?
上面的elf文件中的Relocation section 相关的就是。
代码段的:
Relocation section '.rela.text.startup' at offset 0x190 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000b 000300000002 R_X86_64_PC32 0000000000000000 .LC0 - 4
000000000010 000500000004 R_X86_64_PLT32 0000000000000000 puts - 4
3.他是如何工作的?
对于下面这条指令而言就是要满足:assert((char *)main + 0x14 + offset == (char *)puts);
f: e8 00 00 00 00 call 14 <main+0x14>
链接时需要将补0占位的32位字节填充:S+A-P = offset
S:puts的位置
A:-4 (重定位条目的addend)
P:main+0x10 =(char *)main + 0xf + 1 (0x10是重定位条目的offset)
下面这个例子:
S=0x40c180
P=0x401650+0x10
Offset = 0x40c180 - 0x4 -0x401660 = 0xab1c
gcc -static hello.o -o a.out
objdump -d a.out | less
0000000000401650 <main>:
401650: f3 0f 1e fa endbr64
401654: 48 83 ec 08 sub $0x8,%rsp
401658: 48 8d 3d a5 69 09 00 lea 0x969a5(%rip),%rdi # 498004 <_IO_stdin_used+0x4>
40165f: e8 1c ab 00 00 call 40c180 <_IO_puts>
401664: 31 c0 xor %eax,%eax
401666: 48 83 c4 08 add $0x8,%rsp
40166a: c3 ret
40166b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
000000000040c180 <_IO_puts>:
40c180: f3 0f 1e fa endbr64
40c184: 41 55 push %r13
40c186: 41 54 push %r12
0x401664+ 0xab1c= 0x40c180
不过好像知道这个也没什么用🤣,权当复习了。
重定位目标文件-动态链接
动态链接又叫做与位置无关代码
gcc -c -fPIC hello.s -o d_hello.o
尴尬:readelf 好像没什么区别… 都是R_X86_64_PLT32
哦原来问题在:
原始的动态库:.data(包含GTO) .txt(包含PLT)
代码段都是:只读&共享
数据段都是:进程私有
即:共享库在所有的进程中PLT是一样的,但GTO是不同的。
PLT都是固定的代码模板,PLT中保存的是相对于GTO符号的偏移量,无论共享库被加载到哪里,偏移量不变,动态链接器会在第一次访问函数时填充GTO中对应函数的在进程的实际地址。
函数->PLT->GTO->实际地址
链接成可执行目标文件
如果是位置无关的可重定位目标文件,我们需要一些操作,然后才能变成可执行目标文件,此时代码中并不包含所引用库的具体代码。可执行文件加载进入内存后,进行动态链接。这里的操作就不细究了。
如果是静态链接,需要将重定位条目转换为具体的地址。我们最终的可执行文件是包含了程序执行所需的全部代码。
1.有多个同名符合,如何处理?
Rule 1. Multiple strong symbols with the same name are not allowed.
Rule 2. Given a strong symbol and multiple weak symbols with the same name,choose the strong symbol.
Rule 3. Given multiple weak symbols with the same name, choose any of the weak symbols.
2.静态链接如何进行符号解析?
链接器使用静态库:
E:可重定位目标文件
U:未解析的符号
D:已被先前文件定义的符号
- For each input fifile f on the command line, the linker determines if f is an object fifile or an archive. If f is an object fifile, the linker adds f to E, updatesU and D to reflflect the symbol defifinitions and references in f , and proceeds to the next input fifile.
- If f is an archive, the linker attempts to match the unresolved symbols in U against the symbols defifined by the members of the archive. If some archive member m defifines a symbol that resolves a reference in U, then m is added to E, and the linker updates U and D to reflflect the symbol defifinitions and references in m. This process iterates over the member object fifiles in the archive until a fifixed point is reached where U and D no longer change. At this point, any member object fifiles not contained in E are simply discarded and the linker proceeds to the next input fifile.
- If U is nonempty when the linker fifinishes scanning the input fifiles on the command line, it prints an error and terminates. Otherwise, it merges and relocates the object fifiles in E to build the output executable fifile.
f:目标文件就更新u&d,库就将与u中匹配的目标文件添加到e,同时更新u&d,遍历结束,排除库中不在e的其他文件
这个算法会导致顺序问题。先库,后目标文件,就一定会报错。
以静态链接为例我们得到的最终成果(片段):
0000000000401650 <main>:
401650: f3 0f 1e fa endbr64
401654: 48 83 ec 08 sub $0x8,%rsp
401658: 48 8d 3d a5 69 09 00 lea 0x969a5(%rip),%rdi # 498004 <_IO_stdin_used+0x4>
40165f: e8 1c ab 00 00 call 40c180 <_IO_puts>
401664: 31 c0 xor %eax,%eax
401666: 48 83 c4 08 add $0x8,%rsp
40166a: c3 ret
40166b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
我们已经有了可执行文件,现在让我们开始执行吧!
操作系统扮演的角色
此时我们要执行程序只需要./a.out
环境变量
为什么执行需要加上路径,表明是当前路径下的a.out文件。直接a.out 提示 a.out: command not found。那为什么前面的gcc可以不加路径,平时的javac,ls,python3等都不需要加路径,a.out就需要加?
答案就是环境变量
strace ls 便可发现:execve(“/usr/bin/ls”, [“ls”], 0x7ffc79bac5c0 /* 27 vars */) = 0
实际执行的是/usr/bin/ls
为什么ls 会去/usr/bin/ 路径下找?答案就是环境变量中的PATH
echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/snap/bin
在shell中执行时,没有路径会先去PATH环境变量下的路径中寻找,没找到则会提示command not found。
ps:shell有自己的内置命令,如cd就没有对应的可执行文件
strace cd ..
strace: Can't stat 'cd': No such file or directory
shell
shell是一个软件,我们在shell中敲下./a.out时
strace ./a.out
execve("./a.out", ["./a.out"], 0x7ffd0c908830 /* 27 vars */) = 0
实际干的是:
1.fork一个进程
2.execve开始在fork的进程中执行我们的程序
fork中有许多细节,诸如:fork后线程是如何处理的,文件描述符又是如何处理的等(都不记得了🤣)
fork简单理解为状态机的复制,fork后现在有两个一模一样的状态机了
execve就是状态机重置。重置为可执行目标文件所描述的状态
进程
进程是一个伟大的概念,在这个概念下:每个进程独占cpu,拥有独立的地址空间
在上面的例子中,我们的可执行文件的main函数地址是固定的0x401650,在其它文件中0x401650可能指向的是其它代码,为什么他们不会冲突呢?答案就是虚拟内存。
在虚拟内存的vr眼镜下,每个进程都独立的拥有完整的地址空间。
进程地址空间分布:
todo 图
再来对比下elf文件的结构:
todo图
更能明白为什么说elf文件就是对初始状态的描述。
加载就是按照elf文件的描述,将状态机初始化好。
每一个进程都有一个属于自己的页表,该页表描述了虚拟地址到物理地址的映射,x86 ISA中一般页表的指针存放在CR3寄存器,每次进程切换时,会同时切换CR3寄存器的值。
虚拟地址到物理地址之间的翻译:
p位:2^p^= 页大小 vpo=ppo = 数据在页内的偏移量
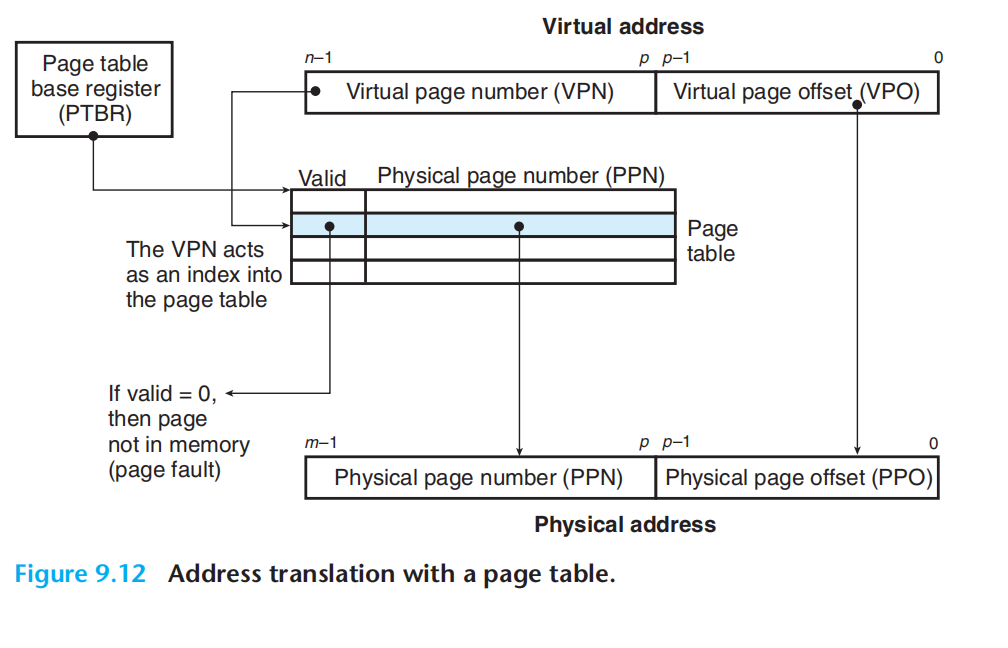
vpn -> 页表 -> ppn
完整的翻译流程:
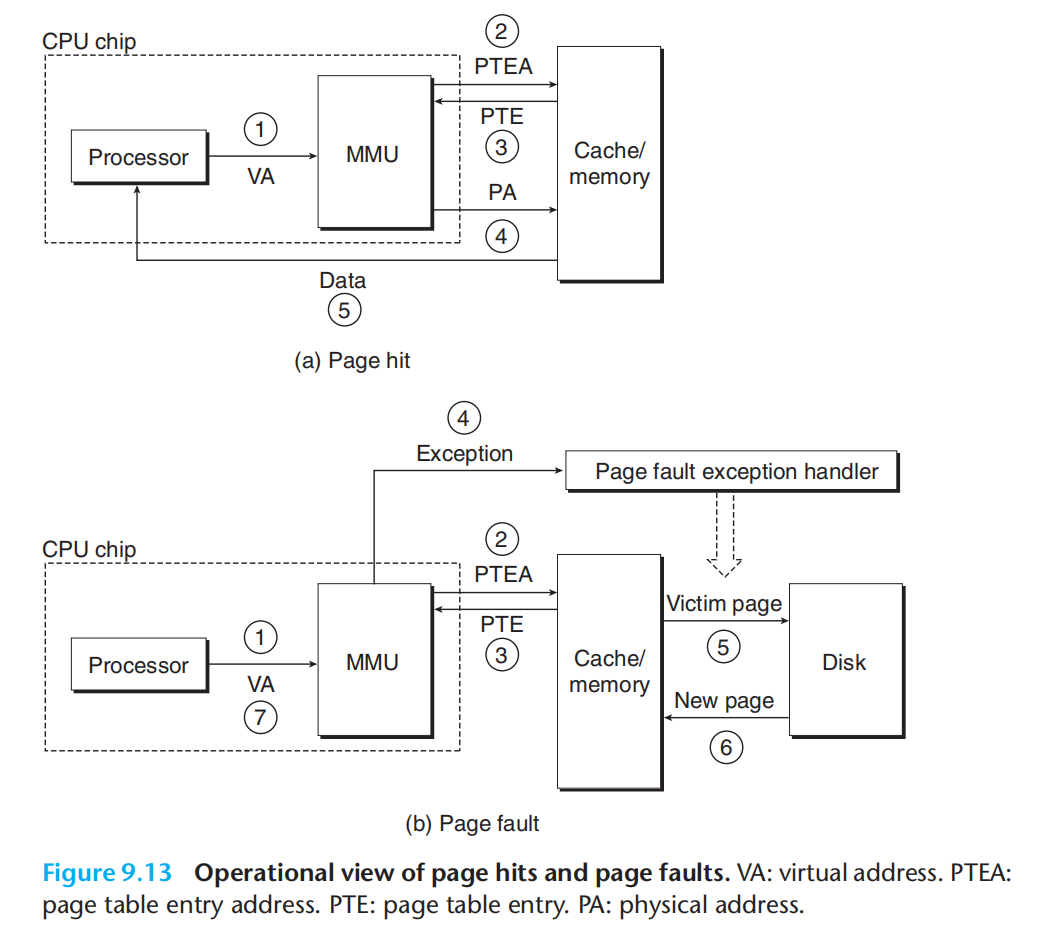
在上面这个流程中我们需要从缓存中获取页表项,后面引入了快表Translation Lookaside Buffer:

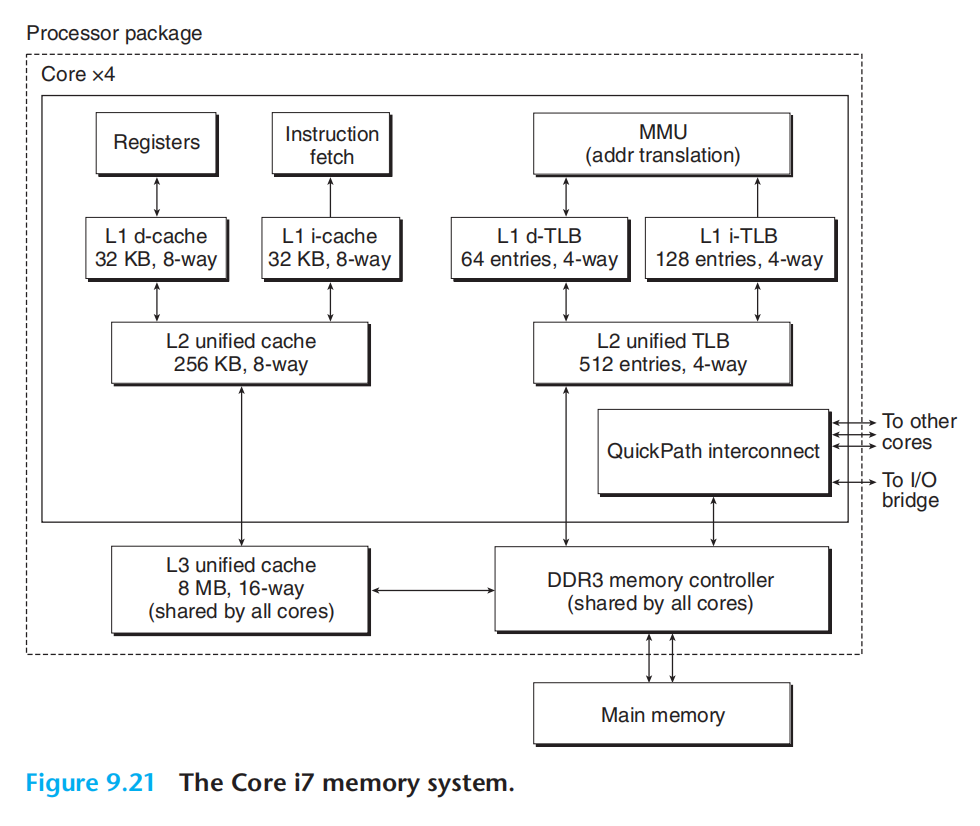
可以在csapp中模拟一个完整的翻译流程:不过此时不想做了…
下面是一个完整流程示例:
前面讲了虚拟内存,现在开始进程这个概念下另一个抽象:虚拟CPU
我们是如何做到在只有一个cpu一个核心的基础上实现“同时”运行多个程序的呢?
这里先解释一下并发这个概念:程序执行的逻辑流在时间上存在重叠(交叉)即为并发
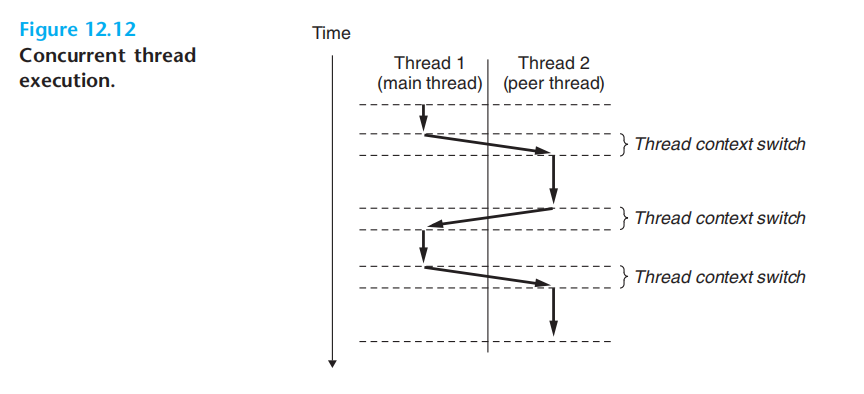
这里的核心概念就是context switch。
理解这个,最好的办法就是看下xv6中trap相关的代码。就不帖了。
异常
首先我们先定义异常:异常就是控制流的突变
分为:
1.中断:
上下文切换,cpu虚拟化的核心机制。进程切换,的调度程序就是中断处理程序之一
2.陷阱:
人为的修改上下文,syscall
3.故障:
可以被修复的错误引起,发生后调用故障处理程序,然后再执行原执行流。缺页
4.终止:
硬件错误
运行总结
当我们在shell中./a.out 后,shell会fork当前进程,然后调用execve,按照elf文件的描述,初始化进程地址空间,最后将pc指针指向我们程序的_start。然后cpu作为无情的指令执行机器,开始执行我们的代码。
CPU如何执行指令
汇编层级的程序
ISA:指令集体系结构,连接程序语言与cpu
数字逻辑电路负责物理实现其语义
高级程序语言则是对ISA的抽象,使之更符合人的思维方式
C语言的形式语义
计算机是一个状态机,程序就是描述了一个状态,c语言层面:状态是什么?状态如何流转的呢?
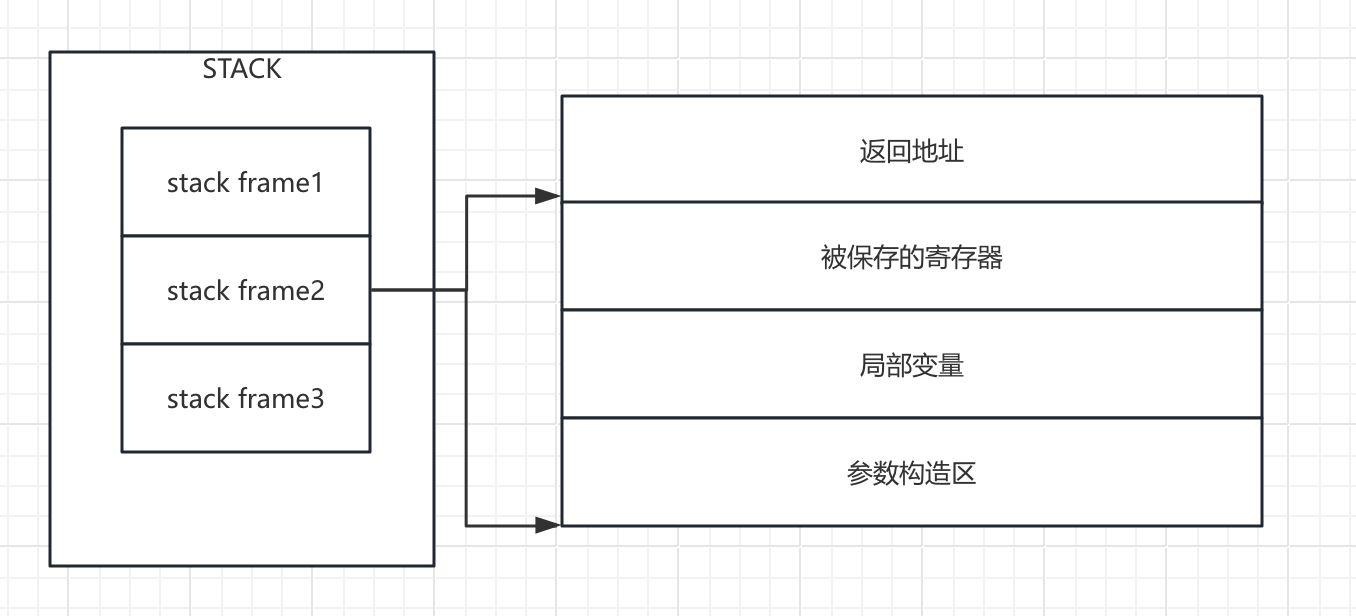
状态就是变量:全局变量存在进程地址空间.data段,局部变量存在函数的stack frame 中
状态的流转就是程序语句
当我们调用函数时,就创建一个对应函数的stack frame,函数返回时就销毁对应stack frame
汇编语言的形式语义
状态:各类寄存器
状态的流转:语句
我们想要保存某一个时刻,程序的状态怎么办?
只需要将相关的寄存器值(例如pc寄存器,rax寄存器等等)存入到内存即可
不同类型的数据在内存中是如何分布的呢?
数组:虚拟地址中连续的地址空间int[3][2]

struct:

union:
按照占用空间最大的那个进行分配
处理器体系结构
逻辑电路中的状态机:
状态:寄存器
转台的流转:组合电路
数字电路是计算机最小的公里体系
高级语言级别:我们认为基本运算不可拆分:例如a+b的计算就是一步完成的。
汇编级别:a+b 被转换成了三条指令:mov a, r1; mov b, r2; add r1,r2;
逻辑电路:上述每条汇编又是按照先后顺序,一条一条执行的吗?
一个基本的指令集应该包含哪些内容?:
- 状态单元
- 指令(控制状态流转)及指令对应的数字编码
- 编程规范
- 异常处理
Y86-64 指令集
4042cdab896745230100 = rmmovq %rsp,0x123456789abcd(%rdx)
40=rmmovq
4=%rsp
2=%rdx
cdab896745230100 = 0x123456789abcd
pushq %rsp:stack中存的是原始值还是push完-8的值?
数字电路
逻辑门电路:电路层面的and 、or、 not
组合电路:多个逻辑门遵循规则组网
1.输入只能是其中之一:a:系统输入,b:某个存储单元的输出,c:某个逻辑门的输出
2.多个逻辑门的输出不能连接在一起
3.网是没有环的
字级组合电路:
组合电路只是一个过程,没有状态,状态机=状态+状态的流转
1.需要保存状态
2.需要一个东西去触发状态的流转(触发时序电路)
时钟寄存器:
- 输入数据在时钟有效边沿被采样并保持到下一周期
- 输出始终保持当前存储值直到下次时钟触发
组合电路+时钟寄存器 = 时序电路(可以保存数据,并按照时钟周期将值在组合电路中传递)
如何用数字电路实现ISA
现在我们开始解释:如何用电路实现rmmovq %rsp,0x123456789abcd(%rdx)
此时指令的机器码是:4042cdab896745230100
- fetch(取指):从当前PC寄存器指向的地址读出4042cdab896745230100,并计算valP = PC+0xA(指令长度10字节)icode=0x40,rA=%rsp,rB=%rdx,valC=0x123456789abcd,valP=PC+0xA
- decode(译码):分别读取%rsp与%rdx 两个寄存器中存储的比特串valA=R[rA],valB=R[rB]
- execute(执行):依据指令的语义,执行相应的数字逻辑电路、计算内存引用的地址、增加减少栈指针,得到valE。对于我们的指令则是计算地址valE=valC+valB
- memory(访存):将数据写入内存/从内存读出,将%rsp寄存器中的值写入到计算出的valE地址的内存中
- write back(写回):将结果写回到寄存器,rmmovq指令不涉及
- update PC(更新PC):将valP 更新到PC寄存器
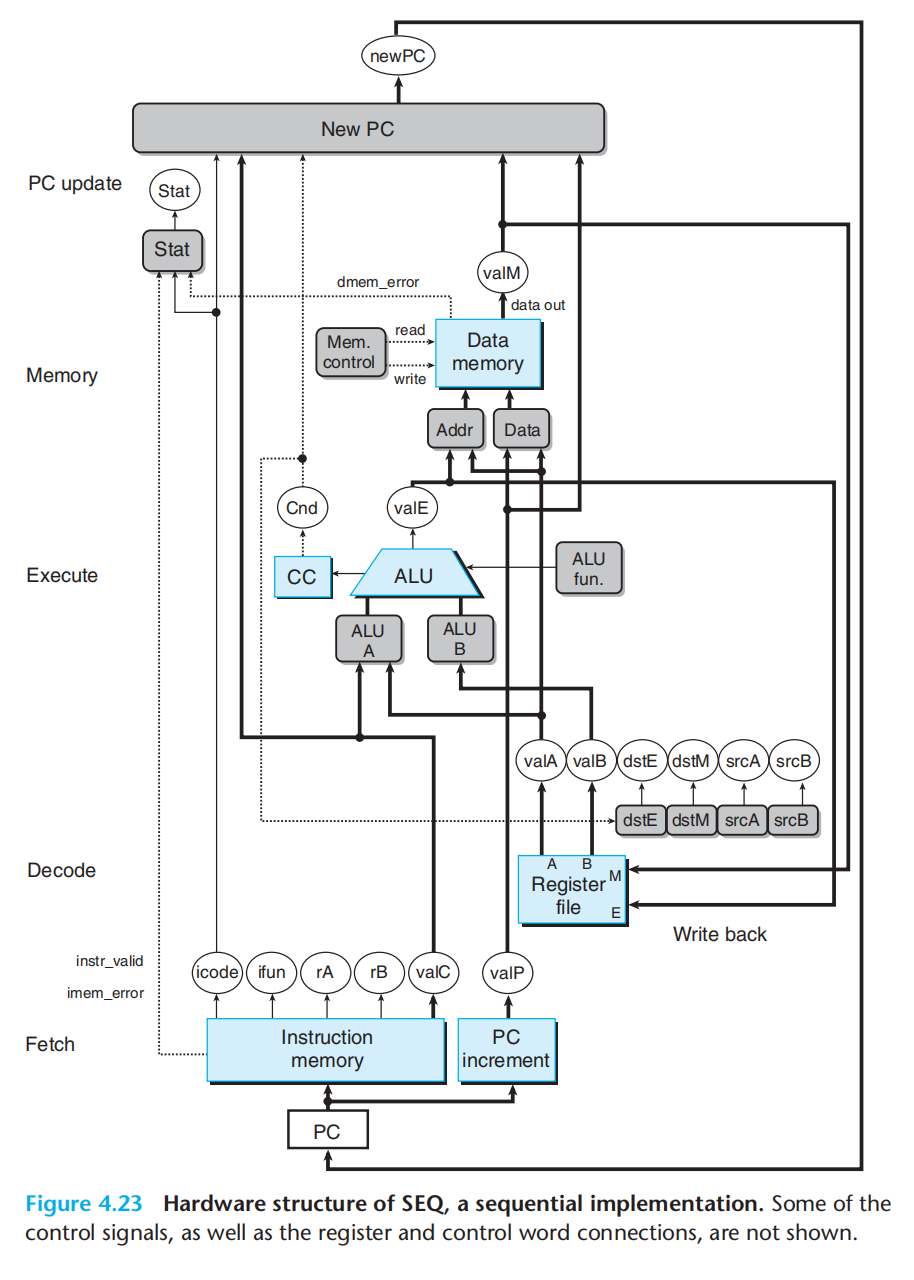
书中涉及的每一条指令的上述阶段实际计算,就不再详述了。
假设我们一个时钟周期完成上述全部逻辑=SEQ(顺序电路设计),时钟必须非常慢,因为需要在一个周期跑完所有的逻辑电路。
高级语言的一个基本计算会被翻译成多条汇编语言,一条汇编语言的实际执行又涉及数字电路的多个部分。
流水线
既然SEQ中的逻辑电路设计,被分割成了不同的部分,可以在每个部分中插入时钟寄存器,保存上一部分电路的输出,同时作为下一阶段逻辑电路的输入。
流水线的数学描述:
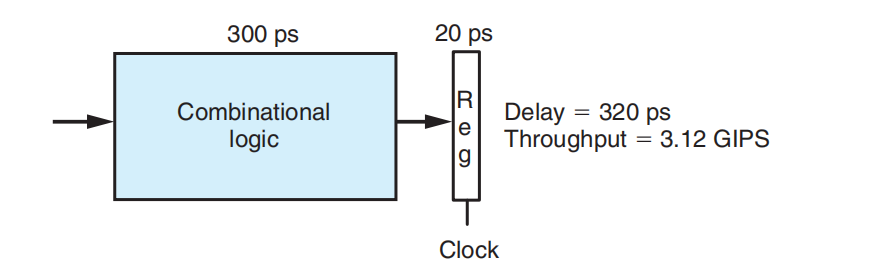
非流水线:组合逻辑-寄存器(组合逻辑300ps,寄存器20ps)3.12GIPS
流水线:组合逻辑A-寄存器-组合逻辑B-寄存器-组合逻辑C-寄存器 = 100+20+100+20+100+20 = 360ps。因为每一阶段(120ps)出去一条指令再进来一条指令 8.33GIPS
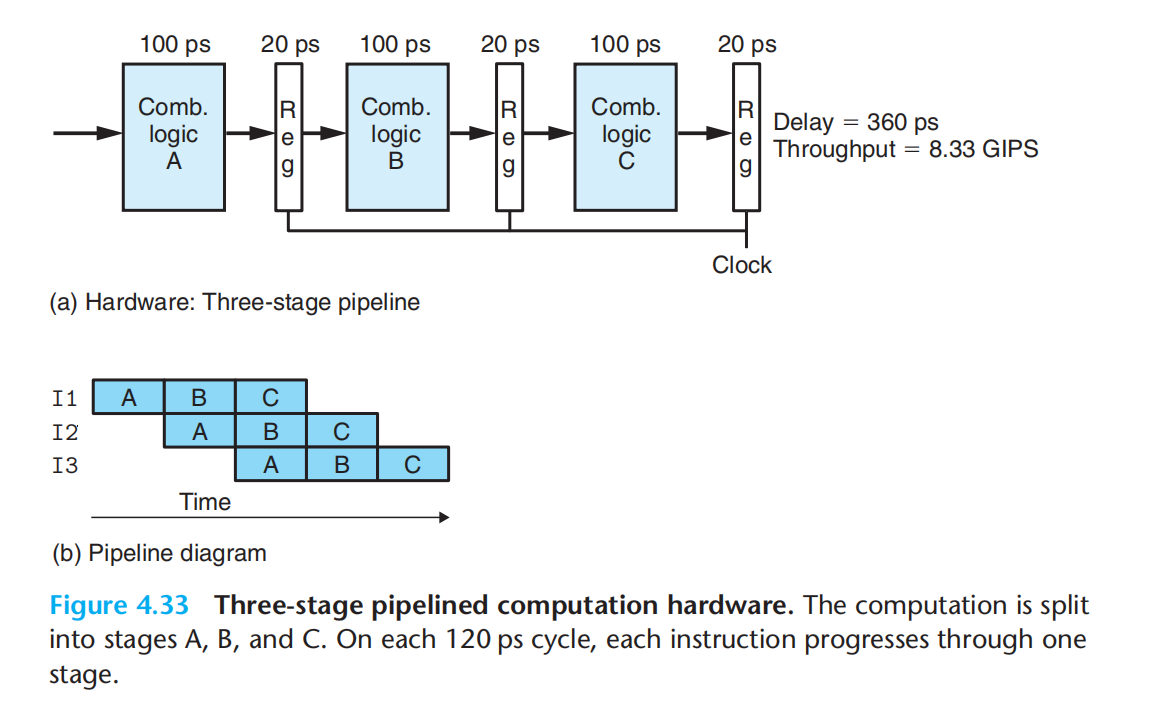
实际:
1.各阶段延迟不一致
2.流水线过深,效益递减
各指令并不完全独立,存在依赖:
1.数据依赖(依赖于同一个寄存器)
2.控制依赖(jne 依赖之前的计算)
Y86-64流水线
前面的SEQ中,PC总是在所有逻辑电路跑完后计算的,但流水线要求,每一个阶段都需要一条指令。
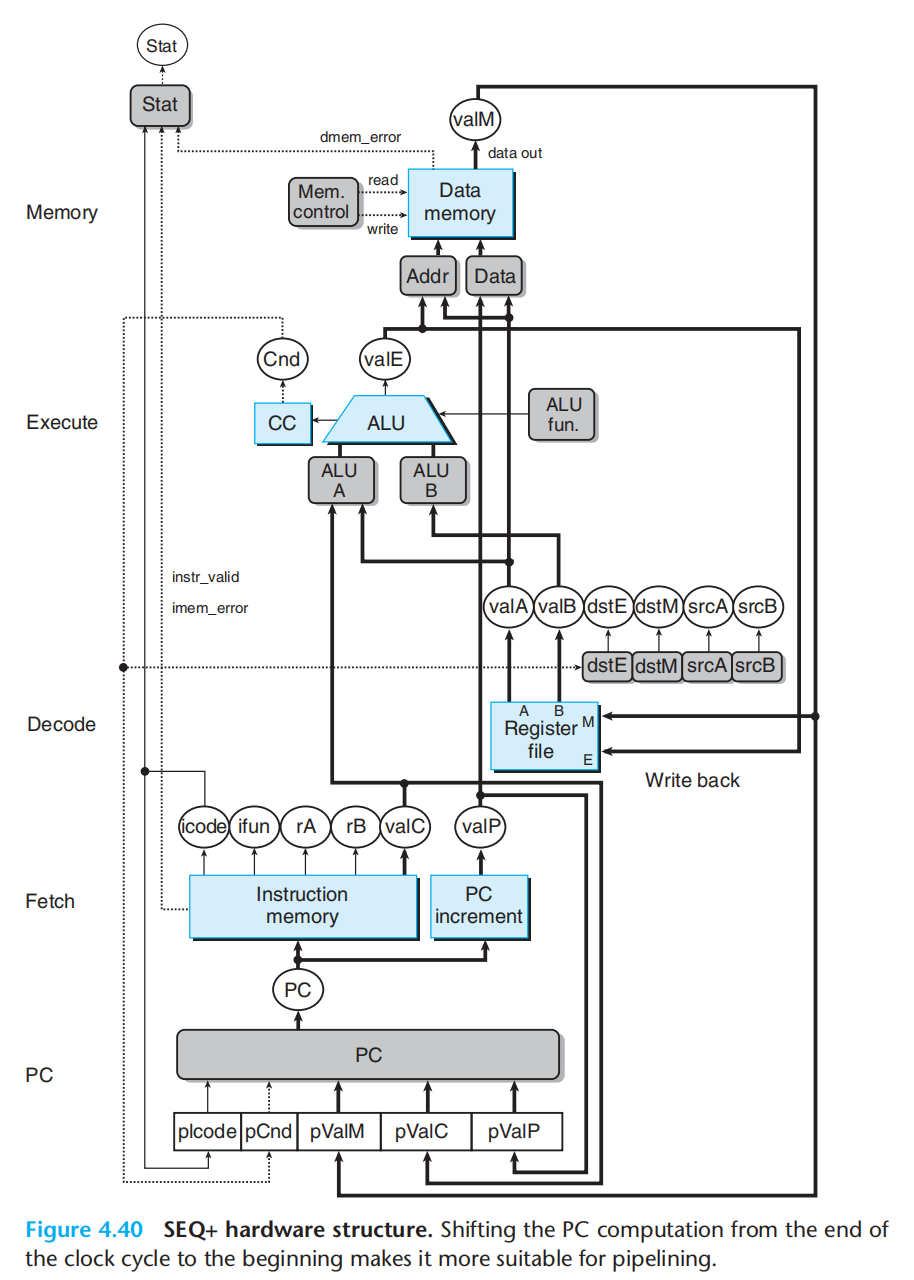
ISA的语义规定了PC寄存器,但此时我们通过上一条指令计算出PC位置,取消了PC寄存器。
一个添加了数据转发的流水线逻辑结构:
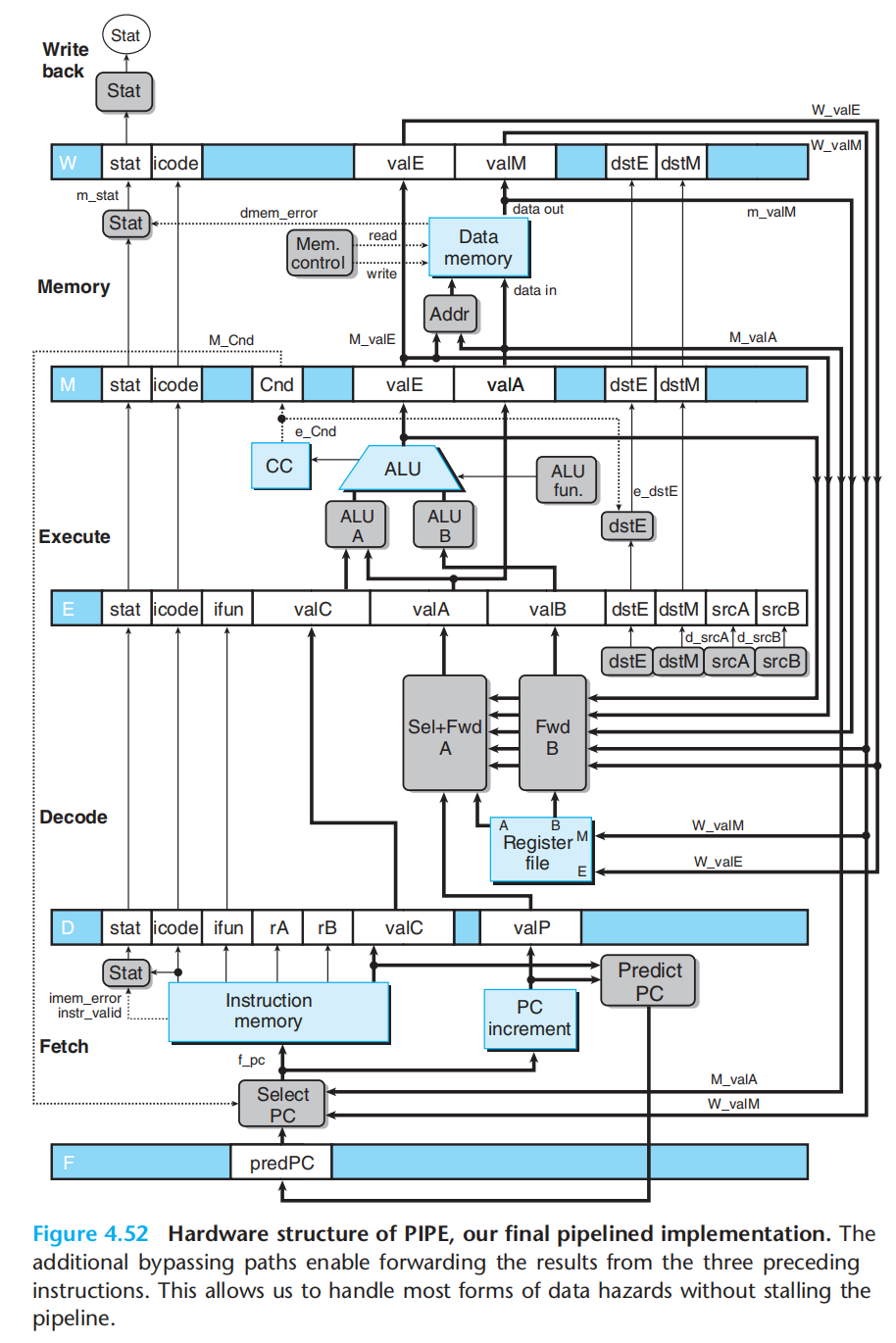
数据冒险:
1.nop
2.数据转发
3.nop+数据转发
控制冒险:
1.ret就暂停
2.预测错误就nop,终止错误指令,开始执行正确指令
异常处理的原则:
1.流水线化的系统中,可能有多条异常指令分布于不同阶段,原则:最深的指令,优先级最高。
2.预测错误的分支存在的异常,不应该被报告
3.异常指令在完成前,后面的指令不能改变系统状态。
关于流水线中的许多特殊细节就不再深究与描述了:毕竟不是所有值得做好的事情都需要做好,人生也是一个system。
重要的是形成:
- 汇编指令到机器码
- 数字逻辑电路实现状态的流转,时钟寄存器实现状态的保存与启动状态的流转
- 机器码经过取指令,译码,执行,访存,写回,更新pc的几个数字逻辑电路处理阶段完成语义
- 各个阶段插入时钟寄存器,保存各阶段的状态,组建流水线式处理
下一章节,会进一步讲述乱序处理器
调度
调度分为静态调度与动态调度
静态调度:编译器,将高级语言在保证关键步骤一致(状态机状态流转一致)的情况下,将高级语言翻译成低级语言
动态调度:cpu内部的指令乱序执行(不能影响状态机语义)
所有调度的目的都是在保证正确性的情况下,尽可能的提高性能。
如何度量性能
Cycles Per Element:每元素的周期数
4Ghz = 每秒 4 * 10^9^ 周期 = 1周期0.25纳秒(1纳秒 = 10^-9^ 秒)
以时钟周期作为计算程序耗时的标准,更关注在循环中,每一个元素消耗的周期,而不是整个程序消耗的周期。
静态调度
示例与论证就不再详细阐述了,仅简单记录结论
1.消除低效循环(循环中有一些函数调用可以取消:strlen等)
2.减少过程调用(展开),创建函数stack frame 也是需要时间的
3.消除不必要的引用(循环中无需每次修改指针,临时变量保存,最后再赋值给指针)
静态调度暂时没必要深究,代码中多用批处理,减少不必要的数据库查询,设计好数据结构与算法,就不错了。
动态调度
ISA的模型中,程序是一条一条按顺序被执行的,但现代处理器(超标量,乱序执行),支持指令级并行。
延迟界限:完成单条指令所需的最短时间(乘法需要3个周期,循环中的先后数据依赖等)
吞吐量界限:单位时间可以完成的最大操作数(4个ALU,流水线每周期发射多少指令等)
现代处理器微体系结构
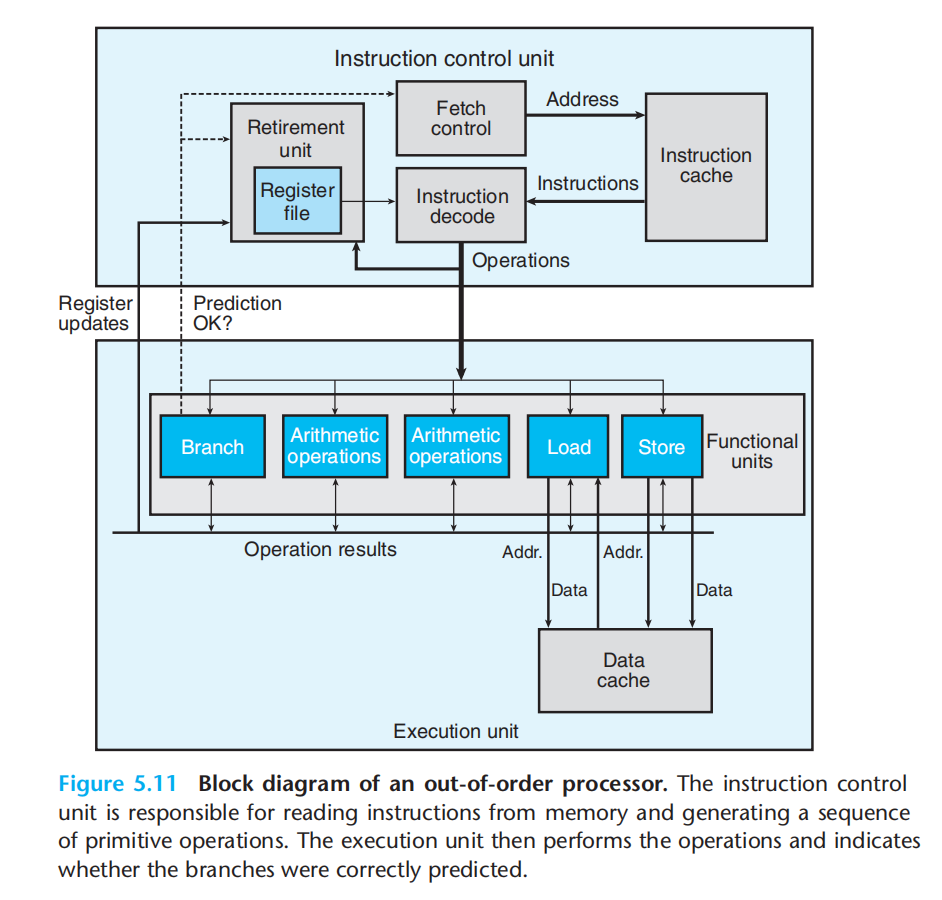
简单抽象:
1.有多个功能单元,每个功能单元可以执行一种或多种操作
2.退役单元retirement unit 保存了所有的状态,只有分支预测正确&指令执行完成,才会将指令退役,只有退役时才会修改寄存器
3.ICU将一条指令翻译成多个操作
4.EU负责执行操作
性能刻画:
延迟:完成运算所需要的总时间
发射时间:同类型运算需要的最小时钟周期
容量:该类型功能单元的数量
关键路径
循环中因为数据依赖形成了关键路径,关键路径又影响了并行度。
for(i=0; i<length;i++) {
acc = acc * data[i];
}
上述代码被翻译成如下指令

这四条指令,被翻译成5个计算步骤
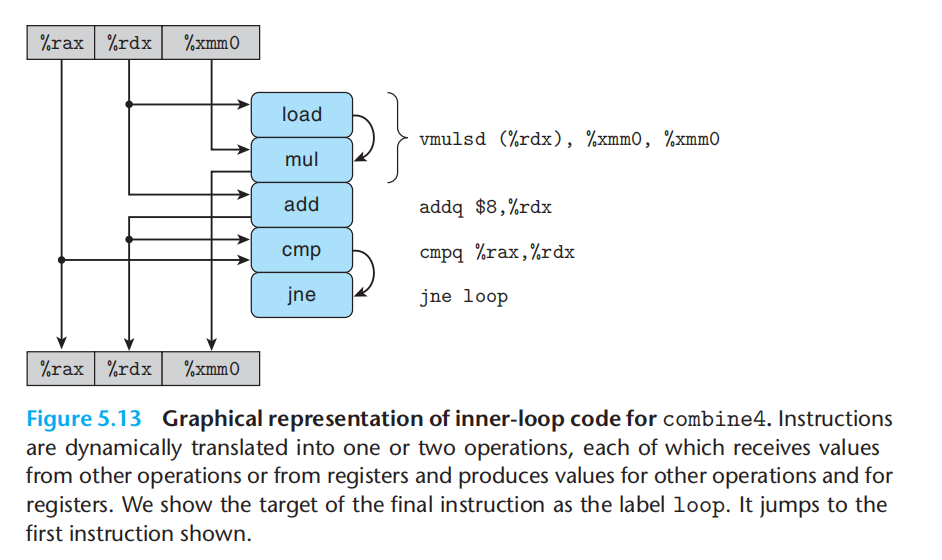
load:从%rdx中读取data[i]的值,并作为mul的输入
mul:load输入的data[i] + %xmm0中的acc 作为输入,计算完成后将输出存放在%xmm0
add:读取%rdx中的data 地址 并将其+8,输出到%rdx,与cmp
cmp:读取%rax中的data+length的地址,并与当前的data中读取到的地址%rdx比较,修改状态寄存器
jne:依据cmp修改后的状态寄存器判断分支如何走
每次循环中的数据依赖:
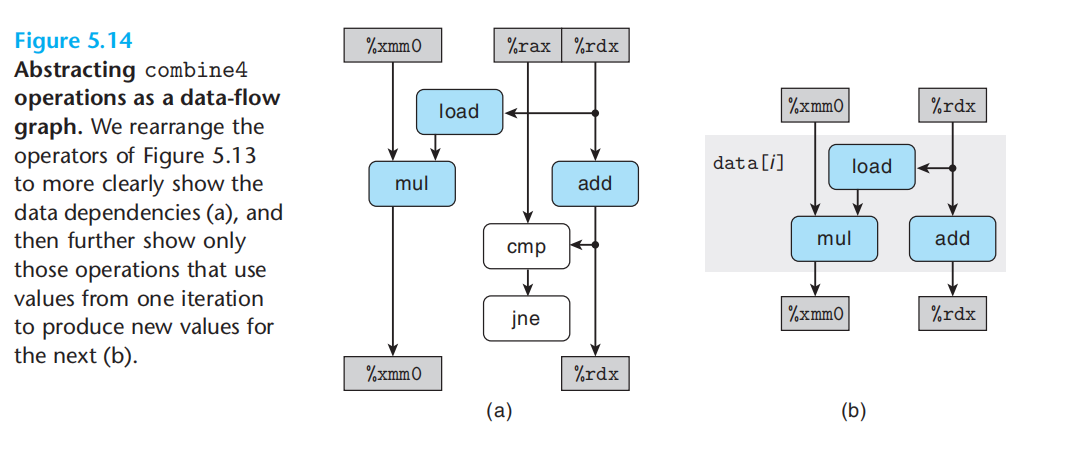
critical path:
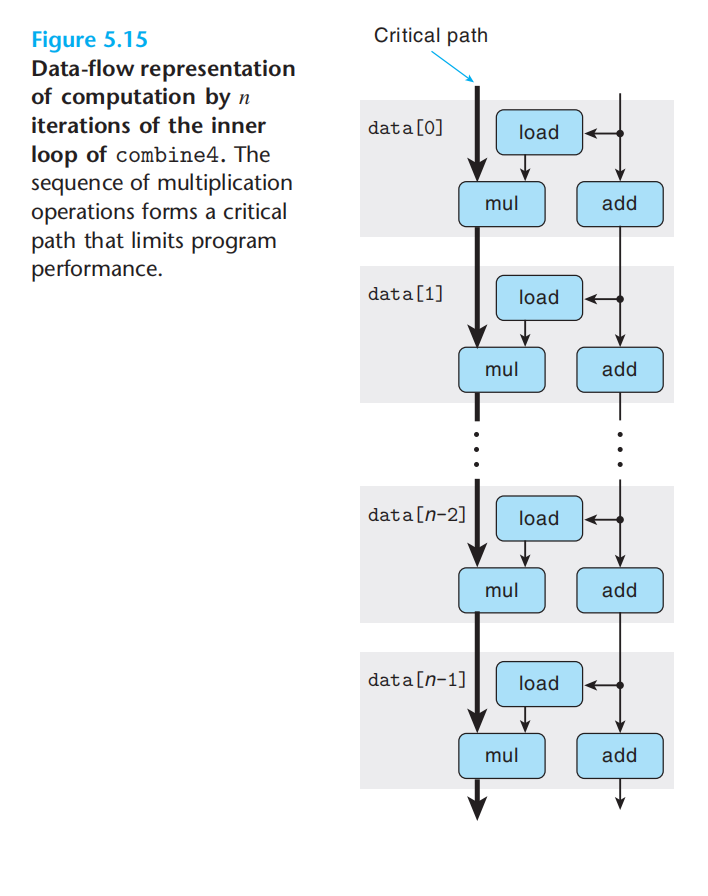
为什么不是add呢? 因为mul的延迟更长。
优化
制约的关键路径已经明确了,如何优化?
1.减少循环的次数=循环展开
for(i=0; i<length;i+=2) {
acc = (acc * data[i])*data[i+1];
}
2.提高并行性(毕竟我们有多个计算单元)
2.1多累积变量(后面的计算不再依赖前面的结果)
for(i=0; i<length;i+=2) {
acc1 = acc1 * data[i];
acc2 = acc2 * data[i+1];
}
2.2重新结合变换P373 不详细展开
其它影响因素
从内存中读取数据需要耗时
profile
调度这部分的内容,主要是了解补充动态调度是在流水线处理器上的更进一步
至此我们基本已经非常粗略的描述了程序的执行过程。敲下的符号,最终如何变成我们想要的结果。在此之外还有一个重要的模块,断电后,数据如何存储呢?–存储系统
存储系统
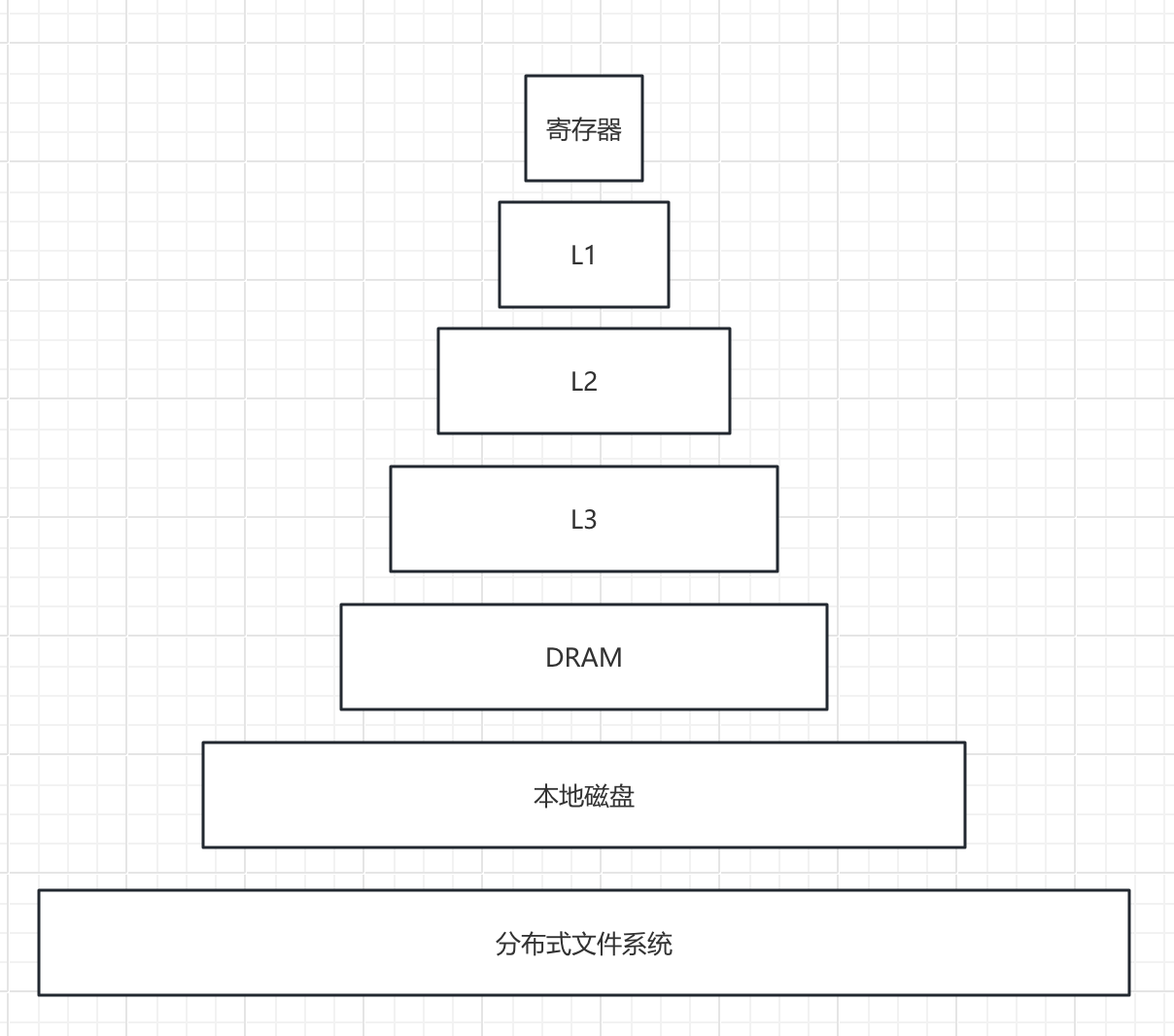
越底层,存储的容量就越大,单位空间价格越便宜,速度也越慢。
磁盘的物理结构
- 主轴
- 盘片
- 盘面
- 磁道
- 扇区
- 读写头
- 传动臂
图?不贴了
设备是什么
从cpu的角度,设备就是能与之交换数据的接口
可一抽象为:几组定义好功能的线+寄存器
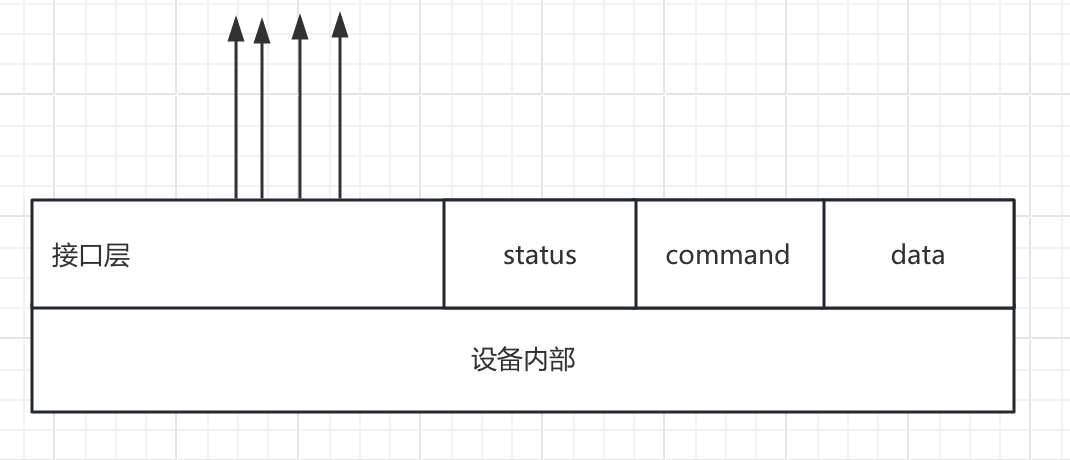
1.先看status是否准备好了
2.好了就发送指令数据到command寄存器
3.轮询状态直到数据准备好了
4.从data寄存器中不停的读取数据
驱动是什么
操作系统定义了IO接口:read & write & ioctl
驱动就是将操作系统的接口语义翻译成对寄存器的操作
文件系统是什么
我们将磁盘视为一个block array ,驱动给我们提供了block read,block write
文件系统是一个数据结构,基于bread,bwrite构建的一个数据结构
磁盘是一个可以读写的字节序列
虚拟磁盘是一个可以读写的动态字节序列
文件系统就是在磁盘上虚拟出许多的虚拟磁盘(每一个文件就是一个std::vector)
构建一个文件系统
原始:我们只拥有block array
Step1:block set 集合中管理,放入取出 balloc,bfree
Step2:实现虚拟磁盘(文件),一个文件需要多少块就balloc多少块,实现可变长的byte array
Step3:用文件实现目录
这里简单解释一下FAT文件系统(File Allocate Table)
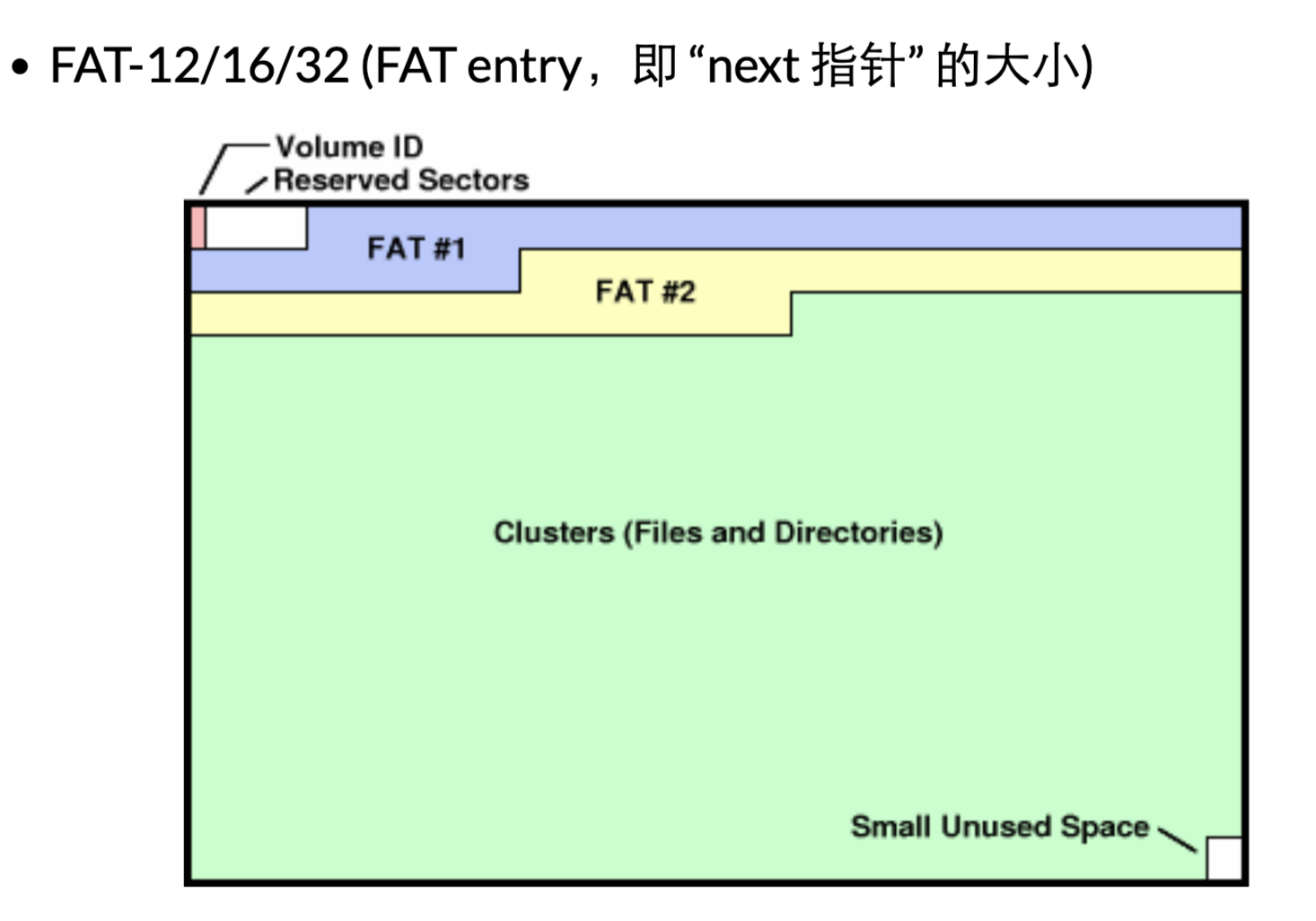
大致分为:保留区,FAT区,数据区。
一个大的文件,通常需要被保存在多个cluster中,这些有顺序的cluster构成了文件的物理实体。简单理解就是FAT区中存放的就是一个个有顺序的链表,链表中的每一项有一个指针指向了cluster。一个完整的链表就是一个文件。
那么目录又是什么呢?如何理解linux中目录也是文件呢?
目录是一个由目录项构成的文件,每个目录项基本包含了:一些元数据(名称,大小等)+ fat中的文件起始项。
fat32中,目录的实体也是存在数据区的cluster中。
通过对FAT文件系统的极简介绍可知:当我们修改某个文件时,不仅仅只修改cluster中的数据,可能还需要修改fat中的信息。即对一个文件的修改,需要我们修改数据结构中与之关联的多个部分。问题来了?如何做到原子性?– log
数据结构的两种视角:
1.物理视角,一个完整的最终状态的数据结构
2.日志视角,初始状态+操作 = 最终状态
两个 “视角”
- 存储实际数据结构
- 文件系统的 “直观” 表示
- crash unsafe
- Append-only 记录所有历史操作
- “重做” 所有操作得到数据结构的当前状态
- 容易实现崩溃一致性
二者的融合
- 数据结构操作发生时,用 (2) append-only 记录日志
- 日志落盘后,用 (1) 更新数据结构
- 崩溃后,重放日志并清除 (称为 redo log;相应也可以 undo log)
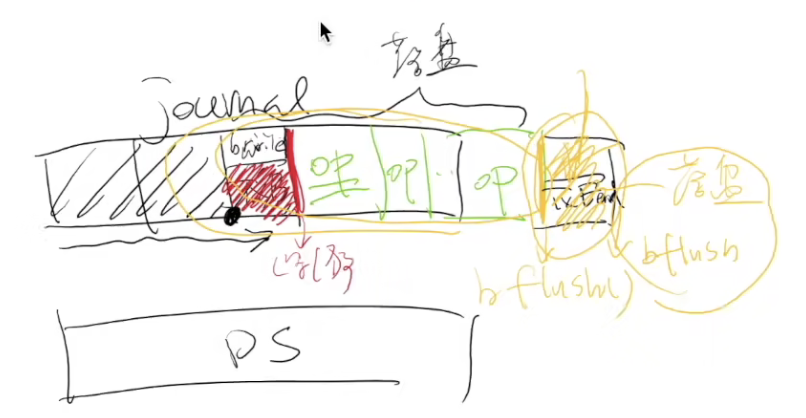
1.先写tx开始(无论是否flush)
2.再写op
3.写完op必须flush落盘
4.最后写tx结束并flush
5.然后再写入数据
崩溃后磁盘找到了tx结束的部分,则保证data部分与journaling一致,如果没发现tx结束的标记则删除对应日志。

缓存是什么
如前所述,cpu的数字逻辑电路只与寄存器交互
存在磁盘的数据并不是直接加载到寄存器,而是:
1.cpu请求某个地址的数据,先从L1中找
2.L1中没有就从L2中找
3.L2中没有就从L3中找
4.L3中没有就从DRAM中找
5.DRAM中没有就从磁盘中加载
因为我们把内存当作磁盘的缓存来使用,所以:内存就像厨房的垃圾桶,永远不够大🤣
对于每一个进程而言,他所拥有的是全部地址空间。
不同层级的缓存,做不到对地址空间的一一映射,所以我们需要在地址空间与缓存实际大小之间建立映射关系
缓存的数学结构描述:[S, E, B, m]
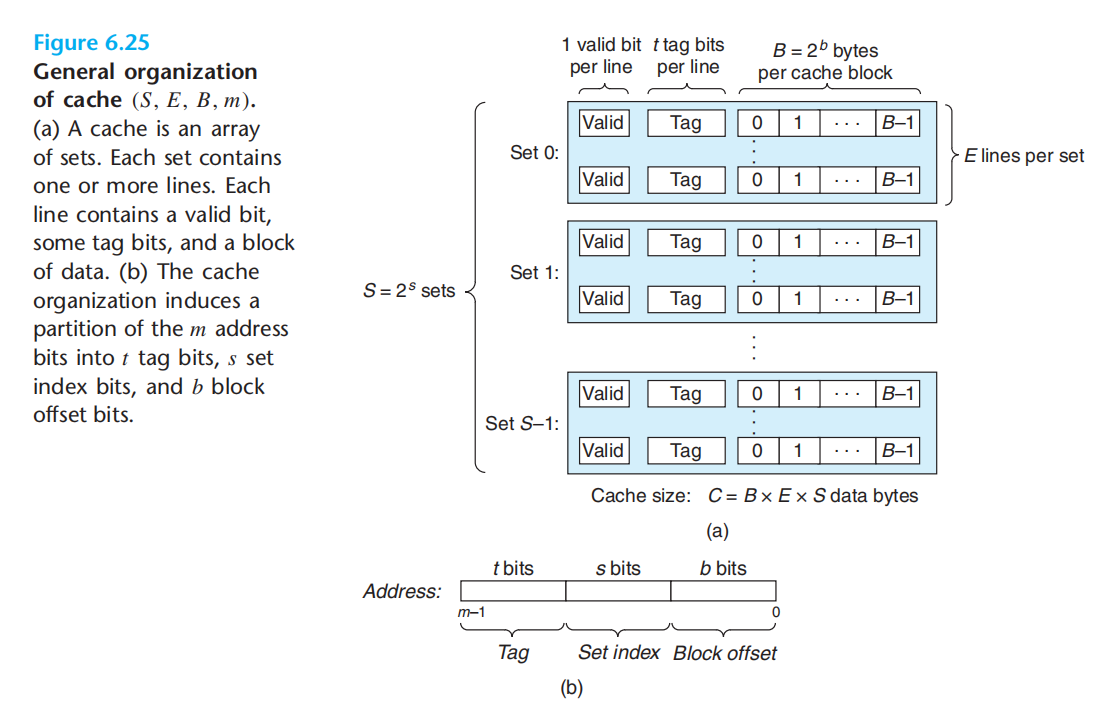
写回:缓存中的块要被驱逐的时候才写入到下一级(虽然我们已经在代码中修改了数据,但修改后的数据此时不一定已经持久化了)
写分配:先将数据加载到缓存,然后再更新缓存,而不是直接更新磁盘
我们如何从磁盘中读写文件
Todo
缓存与虚拟内存
Todo