Kubernetes Overview
20250729
今天开始简单的学习Kubernetes
蚌埠住了,一个简单的minikube就需要2c2g,显然服务器不够用,只能本地学习&测试了
MiniKube
一下内容均来自minikube
minikube:简单的k8s单节点集群
kubectl:与k8s集群交互的终端,类似reids-cli
安装并运行minikube,相当于在本机上运行了一套k8s集群
安装好上述两个软件后:
1.minikube start
2.minikube dashboard
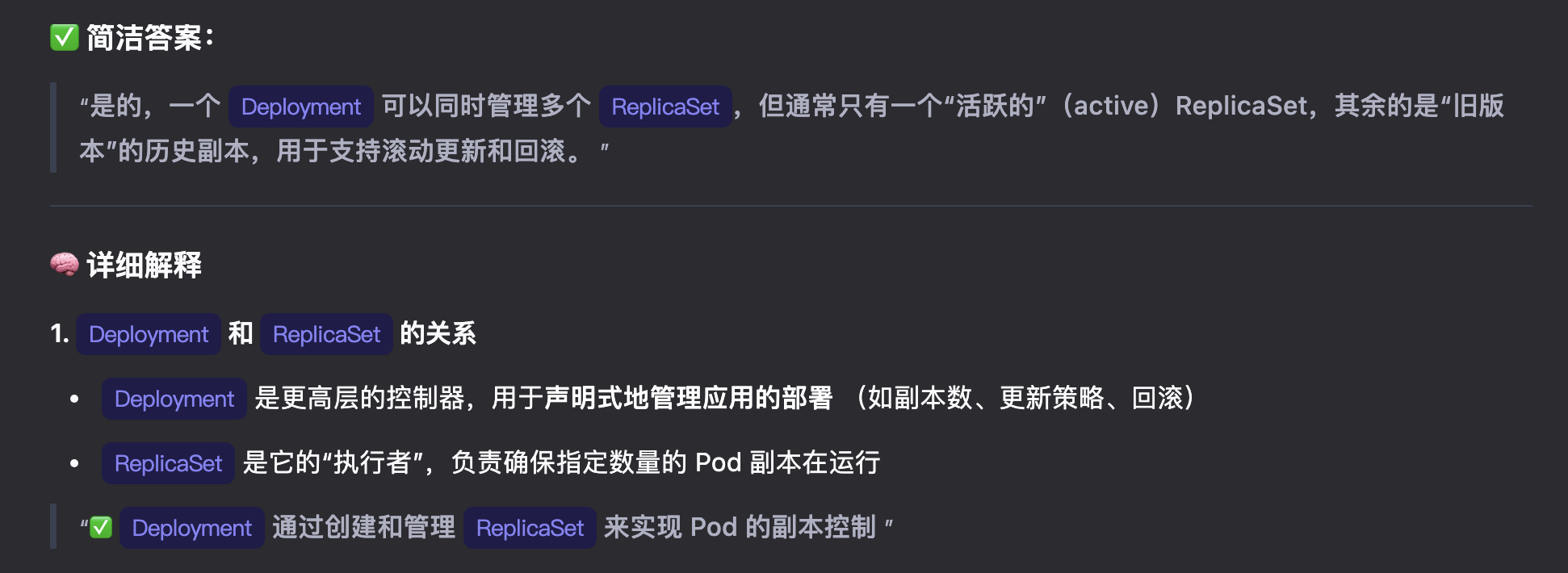
3.创建pod(逻辑机器,一个pod内的容器,命名空间一样)kubectl create deployment hello-node --image=registry.k8s.io/e2e-test-images/agnhost:2.39 -- /agnhost netexec --http-port=8080,这个命令创建的是deployment,但是deployment会依据配置,自动创建ReplicaSet并由其创建pod,即我们创建了deployment,最终会间接创建出pod。
kubectl get deployment
kubectl get replicaset
kubectl get pod

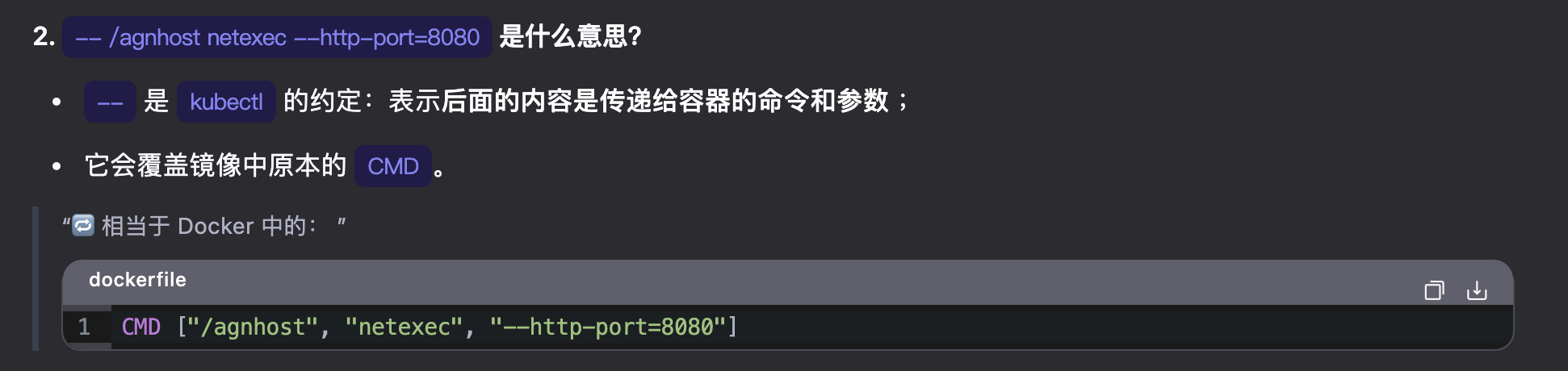
CMD [“可执行文件”, “参数1”, “参数2”, …]
这里有一个概念:pod是通过deployment去管理的,要创建pod,需要创建deployment。
Deployment
│
├── 定义:我想要 3 个运行 nginx:1.21 的 Pod
│
▼
ReplicaSet(副本集)
│
├── 确保始终有 3 个 Pod 在运行
│
▼
Pods(多个)
├── nginx-pod-1
├── nginx-pod-2
└── nginx-pod-3
Deployment 控制一个 ReplicaSet, ReplicaSet 负责确保指定数量的 Pod 始终运行,所有 Pod 都是基于 Deployment 中定义的 pod template 创建的.
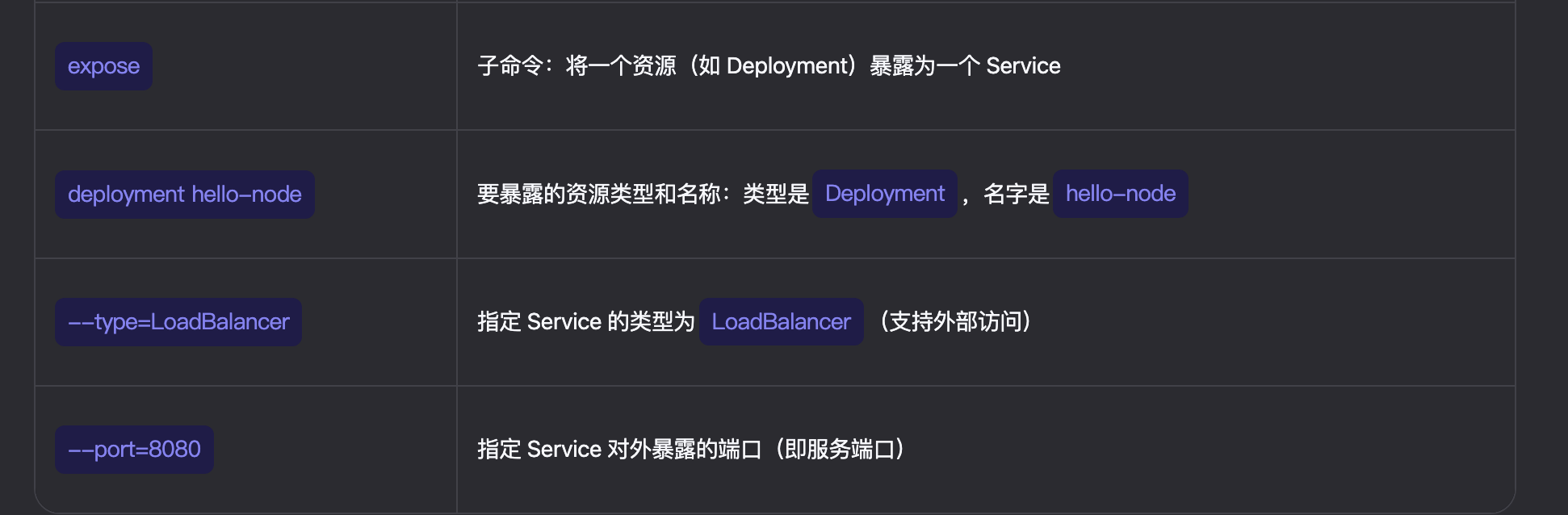
4.目前我们创建了pod,但pod有自己的namespace,也就意味着有自己的一套独立网卡(虚拟网卡)。实际使用中会有多个pod副本,统一对外提供服务,需要创建service,一统所有pod。kubectl expose deployment hello-node --type=LoadBalancer --port=8080
kubectl get services
Deployment 管理 Pod 的“生老病死” → Service 管理 Pod 的“对外服务“。
既然service作为一堆pod的统一对外服务点,是否使用了kube就不再需要nginx了?
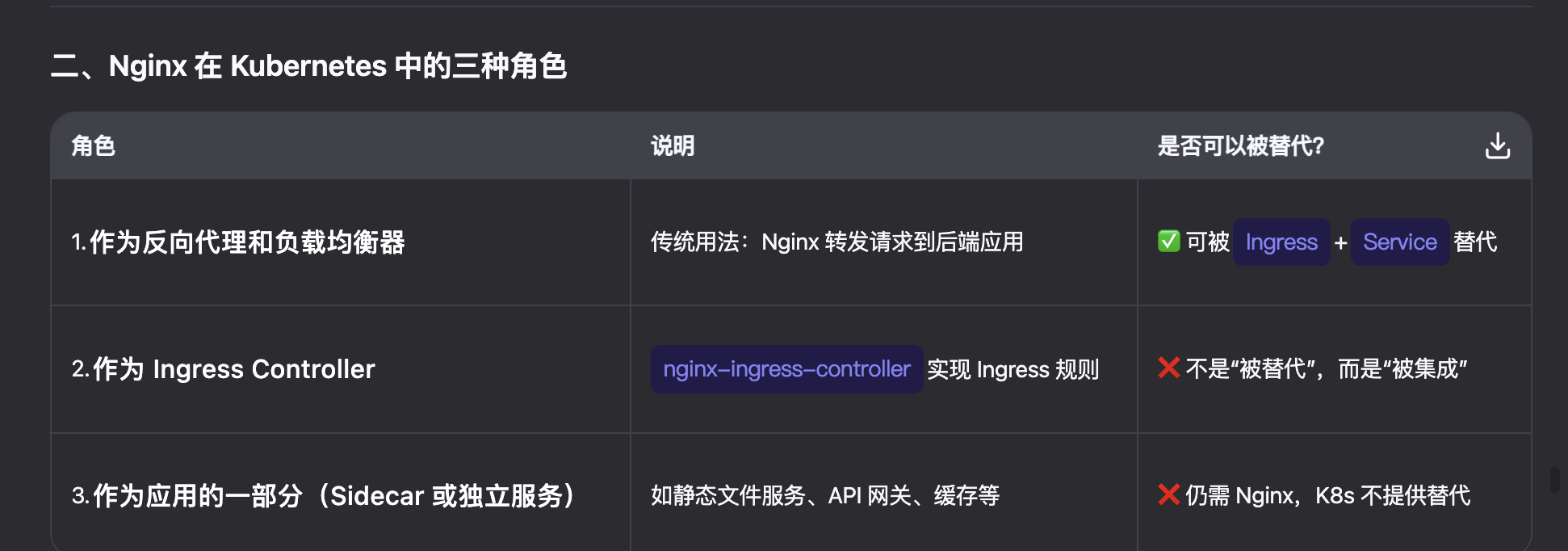
反向代理与负载均衡的功能已经被替代了
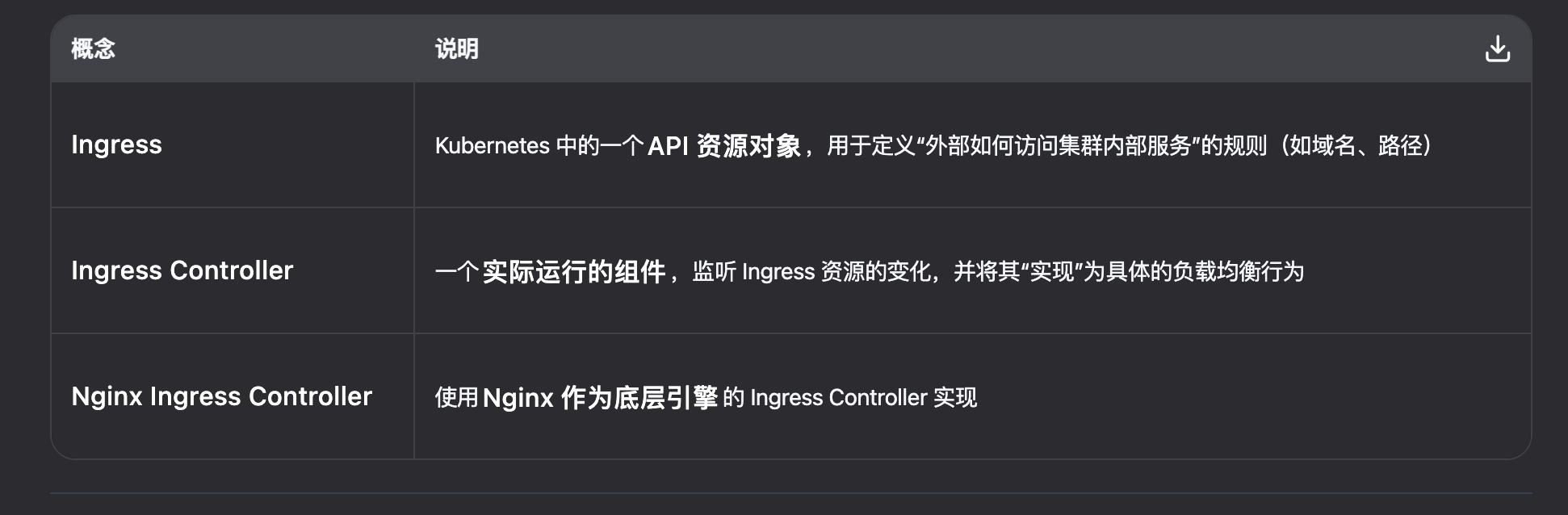
不过nginx可以作为kube的ingress的具体实现
此外,nginx可以提供静态文件服务等功能。
至此,我们引入了:
- Kubernetes集群
- node 集群中的一个逻辑机器(可以是一个容器,也可以是一台虚拟机,或一台物理机)
- Control Plane :控制平面,集群的leader,可以与载荷node一起部署在同一台机器,也可以单独部署到所谓的master结点,可以部署1个实例,也可集群部署。但逻辑上选举产生只有一个leader。
- deployment:Control Plane负责产生,deployment逻辑上属于Control Plane,deployment控制并管理pod。物理上一个deployment可能涉及多个node。物理上的node里面可能包含多个pod。
- ReplicaSet副本集,deployment可以持有多个ReplicaSet,但只有一个生效,ReplicaSet直接产生pod。deployment 说要6个pod,ReplicaSet产生6个pod,假设此时集群只有3台node,可能A上1个,B上3个,C上2个。
- pod是kube的最小管理单元,可能有1个or多个容器。
- service:也是属于Control Plane,为一组pod提供稳定的网络地址。这些pod可以跨node。
至此,就有一个kube的整体结构图:
逻辑上:
- Control Plane
- deployment、service
- ReplicaSet,一个deployment可以有多个ReplicaSet,但激活的只有一个,其他的是历史版本
- pod
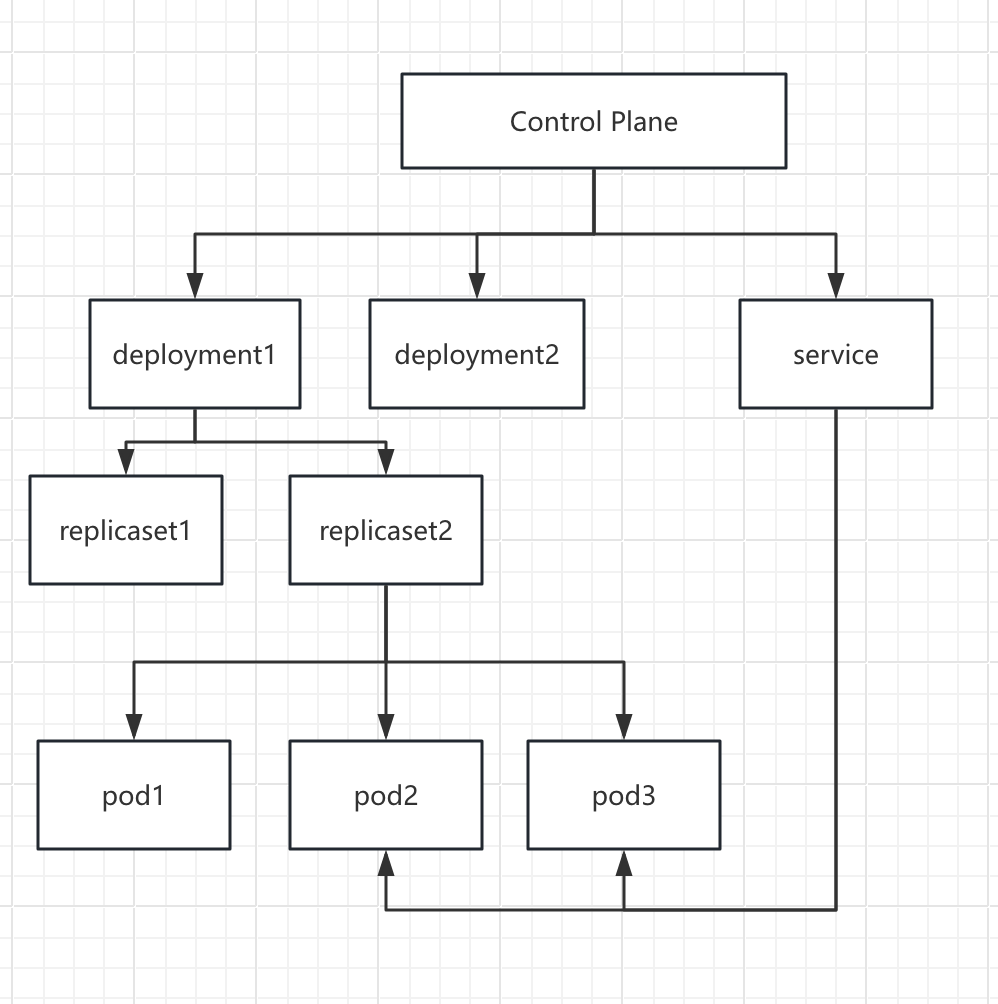
物理上:
- Control Plane 是集群的leader,可能在多个host上存在副本
- Node就是host,有自己的network namespace,一个deployment的pod可能涉及多个node
- pod是部署在node上的,一个node可以存在多个pod。这个pod可以来自一个或多个deployment。
node作为host,有自己的namespace
pod的定义就是属于相同namespace的一组容器

插件
清理
minikube stop
基础教程
使用 Minikube 创建集群
集群有两种资源:
- 控制面(Control Plane) 调度整个集群
- 节点(Nodes) 负责运行应用

每个node有:
- Kubelet 充当代理,control plane的指令都通过kubelet执行
- 容器的runtime环境
Minikube start
Q1:现在的minikube 只有一个node,如何添加更多的node到集群?
部署应用

kubectl action resource
kubectl create deployment kubernetes-bootcamp --image=gcr.io/google-samples/kubernetes-bootcamp:v1
在kube中所有的pod都是在一个扁平网络中,所有的pod之间是可以相互通信的。
kubectl proxy
- API Server 通常运行在 Control Plane 节点上,监听
6443端口 - 它是唯一与
etcd通信的组件
运行了kubectl proxy后 本机的localhost:8080映射到集群的网络的APIservice所监听的端口。其实只需要简单理解为:ssh 反向代理。ssh -R
查看pod
pod内共享的资源:
- 卷形式的共享存储
- 集群内唯一的 IP 地址,用于联网
- 有关每个容器如何运行的信息,例如容器镜像版本或要使用的特定端口

一般只有容器需要共享磁盘时才将其编排到一个pod。
node:

这里需要注意:
node ip = 结点的可访问ip,如果结点是物理机,node ip 就是结点物理世界的ip地址
pod ip(Pod IP 来自一个虚拟子网(如10.244.0.0/16))
使用 Service 公开你的应用

service 是pod的逻辑集合:
- ClusterIP(默认)- 在集群的内部 IP 上公开 Service。 这种类型使得 Service 只能从集群内访问。
- NodePort - 使用 NAT 在集群中每个选定 [Node] 的相同端口上公开 Service 。 使用
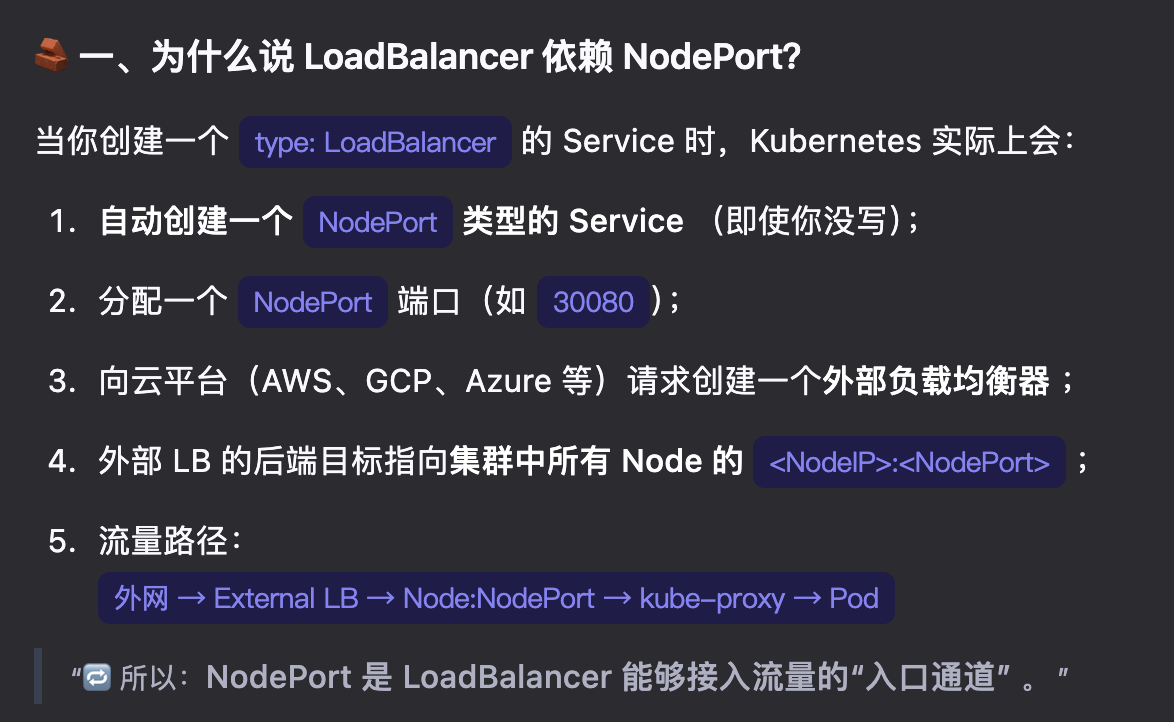
NodeIP:NodePort从集群外部访问 Service。这是 ClusterIP 的超集。- LoadBalancer - 在当前云中创建一个外部负载均衡器(如果支持的话), 并为 Service 分配一个固定的外部 IP。这是 NodePort 的超集。
- ExternalName - 将 Service 映射到
externalName字段的内容(例如foo.bar.example.com), 通过返回带有该名称的CNAME记录实现。不设置任何类型的代理。 这种类型需要kube-dns的 v1.7 或更高版本,或者 CoreDNS 的 v0.8 或更高版本。
对于clusterIP类型的举例:
- Pod IP:
10.244.0.10(来自10.244.0.0/16) - Service ClusterIP:
10.96.123.45(来自10.96.0.0/12) - 它们不在同一子网,但都在集群内部可达,由
kube-proxy和 CNI 插件协同管理。
ClusterIP 是一个虚拟 IP,与 Pod IP 同属“集群内部网络”,但通常来自不同的 IP 段,属于不同的子网
到达service所在ip+端口的流量会被负载均衡到某一个具体的pod。
NodePort 类型的 Service 会在集群中每一个 Node 上监听一个预定义的高端口(如 30000-32767)。外部用户可以通过任意 Node 的 IP + NodePort 访问该服务。请求进入任一 Node 后,由 kube-proxy 根据 Service 的规则,将流量负载均衡到后端任意一个健康的 Pod 上——即使该 Pod 运行在另一个 Node 上。NodePort = ClusterIP + 在每个 Node 上开放一个端口
似乎开始有点理解service了,service作为一个逻辑层,其实就是负责监听目标socket,然后再转发到内部的某个pod。
LoadBalancer 则是有一个公网ip,然后将socket监听到的信息转发到部分(依据规则)nodeip:nodeport,再然后到service 再到pod。loadBalancer = NodePort + 云厂商的外部负载均衡器(External Load Balancer)
ExternalName 是 Kubernetes 中一种特殊的 Service 类型,它的作用是:在集群内部为一个外部服务(如数据库、API、SaaS 系统)提供一个别名,使得 Pod 可以通过标准的 Service 名称访问外部资源,而无需硬编码外部域名。(倒反天罡🤣)
如何通过lable等创建service暂时先不了解了
运行多实例


kubectl scale deployments/kubernetes-bootcamp --replicas=4 给deployment 扩容
kubectl scale deployments/kubernetes-bootcamp --replicas=2
滚动更新
哦耶,终于到了kube生产中目前最有意思的部分了,毕竟当前我们的生产实际上没有高并发,倒是无感发布有价值的多。
蚌埠住了:kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=docker.io/jocatalin/kubernetes-bootcamp:v2 这么简单
回滚:
kubectl rollout undo deployments/kubernetes-bootcamp
kubectl delete deployments/kubernetes-bootcamp services/kubernetes-bootcamp
教程结束了?
感觉网络上的疑问更多🫠
当然还有很多细节了,but,不求甚解+遇到问题再去了解 是当前我选择的策略,so what next?
maybe :尝试将我们在阿里上部署的服务,发布到kube?yes。i must do something even like toy。
kube toy
我那可怜的2g服务器实在难为他了。
一个长久todo:将旧笔记本安装WSL,想办法配置成一台服务器,虽然它羸弱,架不住16G2C啊。
搜了下,K3d一键docker中部署kube集群…
1.先运行kube集群
2.修改云效flow镜像
3.完成云效中镜像构建完后无感发布到kube
1.docker中运行kube集群
k3d cluster create mykubecluster \
--servers 1 \
--agents 2 \
--port "80:80@loadbalancer" \
--port "443:443@loadbalancer" \
--k3s-arg "--disable=traefik@server:*"
这是一个最好的时代🤣
1.kubectl get nodes 失败:"Unhandled Error" err="couldn't get current server API group list: Get \https://host.docker.internal:54058/api?timeout=32s\": EOF
我已经明确知道config中kubectl访问service的地址是
https://host.docker.internal:54058
,k3d-mykubecluster-serverlb的端口映射为6443/tcp -> 0.0.0.0:54058,现在我在宿主机运行kubectl get pods 会提示”Unhandled Error” err=”couldn’t get current server API group list: Get "
https://host.docker.internal:54058/api?timeout=32s": EOF” 。ping
https://host.docker.internal:54058
显示198.18.2.221 可以ping通
fuck: 因为可以ping通说明网络是连通的,但是eof,qwen给的解释是host.docker.internal 未被包含在 TLS 证书中。于是修改config切换service 地址为127.0.0.1:54058 终于可以成功访问。开头就是一棒子🥹
2.制作arm版的镜像
20250803,阴天,中午一点,自习室竟然有座位,暑假以来第一次自习室占到座…
为了更好的模拟,我决定在现有的mqtest 模块中引入web 部分,新增一个url,然后本地docker启动kafka,实现云效集成并在本地发布。
- 引入web
- 新增接口与consumer 联动
- 使用arm镜像,允许云效生成arm版的镜像
- 本地docker中启动新的镜像并调试通相关服务
还好之前有amd64 & arm 的两个版本的镜像。
卡在第四步:需要修改kafka的配置,因为是在容器中运行,localhost是容器内的地址,现在需要容器内的服务可以访问到宿主机的9092端口。
Q:已经将配置修改为host.docker.internal:9092,但服务启动依旧读取的127.0.0.1:9092
A:查明原因是kafka容器中的配置advertised.listeners=PLAINTEXT://localhost:9092
服务通过host.docker.internal:9092连接到了kafka,然后kafka告诉服务应该通过127.0.0.1:9092来连接broker。
修改配置为:advertised.listeners=PLAINTEXT://host.docker.internal:9092 即可。
16:45 终于在docker中成功启动了服务,并暴露了接口。next..
3.CICD
在CICD之前,先试着在本地docker中的kube集群中部署并启动服务,同时创建一个service暴露接口。
1.kube集群中启动服务
2.创建service暴露接口
kubectl create deployment myapp \
--image=crpi-7m50baljoy8xmhl0.cn-chengdu.personal.cr.aliyuncs.com/liaozk_test/liaozk_test_docker:001 \
--replicas=3
失败了?ErrImagePull
哦~ 仓库需要授权
kubectl create secret docker-registry my-secret \
--docker-server=crpi-7m50baljoy8xmhl0.cn-chengdu.personal.cr.aliyuncs.com \
--docker-username=lzkutopia \
--docker-password=******** \
--namespace=default
删除旧deployment
创建deployment 使用secret
kubectl create deployment myapp \
--image=crpi-7m50baljoy8xmhl0.cn-chengdu.personal.cr.aliyuncs.com/liaozk_test/liaozk_test_docker:001 \
--replicas=3 \
--image-pull-secret=my-secret
k3d创建的集群不支持参数:image-pull-secret
还是不能偷懒,只能使用yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: crpi-7m50baljoy8xmhl0.cn-chengdu.personal.cr.aliyuncs.com/liaozk_test/liaozk_test_docker:001
imagePullSecrets:
- name: my-secret
kubectl apply -f deployment.yaml
ok 成功启动了3个pods
因为使用了K3d来创建的集群,所以特殊处理了下service
apiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
type: LoadBalancer
selector:
app: myapp
ports:
- protocol: TCP
port: 80 # 外部访问的端口(通过 80 映射)
targetPort: 8089 # Pod 容器内的端口
kubectl apply -f service.yaml
done: 成功 http://localhost/api/getMessageCount 可以成功访问!
Q1:在k3d创建的这个集群中,流量是怎么走的?
Q2:我有3个pod,为什么请求返回的count有一个的是0?如何排查是哪一个?how?why?
18:51:极饿无比,回去了,今天的一鼓作气没了。剩下云效整合?如何实现更新?(无感发布)
next day:
1.先解决Q2
kubectl logs myapp-7ccbb7f8d8-fqlh9
查看日志,发现三个pod都在生产,确只有一个pod在消费,故应该有两个pod的count=0。因为我的kafka只有一个topic,一个分区,一个消费者组。故只能消费者组的一个消费者消费分区。
2.Q1
- 宿主机80 映射的serverlb80
- serverlb 匹配service,serverlb 依据匹配的service 将流量转发到对应NodePort
- Node 上的 kube-proxy 捕获 NodePort 请求
- 将流量转发到 Service 的 ClusterIP:80
- 虚拟 IP(ClusterIP)根据负载均衡策略,选择一个 Pod,并转发到Pod 所在 Node 的 kube-proxy
- kube-proxy 将流量转发到 Pod 的 IP:8089
重点是要理解service是LoadBalancer 包含NodePort,NodePort包含ClusterIP
20.40 至此结束,不想再去云效上部署kube了,我只感到一种无尽空虚🥹🥹