实验记录
Project
bomb
这里将会详细记录下解决bomb项目的过程,原因很简单,当我把相关文件下载下来后,完全不知道如何开始,所以很有必要记录下来。
Bomb 实验的原始文件只有三个:bomb.o + bomb.c + readme
目标文件,没发打开,readme没有什么信息,唯一能看的就是bomb.c ,包含了bomb的基本结构,读入字符串,运行phase1~6.那么主要的工作基本就是反汇编,理解各个phase的实现,然后求解。
https://csapp.cs.cmu.edu/3e/bomblab.pdf 提供了诸多有用的信息:
1.阅读汇编,静态求解。
2.调试
工具:
gdb
objdump -t
objdump -d
strings
Don’t forget, the commands apropos, man,and info are your friends. In particular, man ascii might come in useful. info gas will give you more than you ever wanted to know about the GNU Assemble。
注意机器码基于x86-64 系解指令,so mac上是运行不了的。
apropos: 可以搜索当前计算机上所有的命令
man: 查看命令手册,man ascii 查看ascii编码
Info 类似,mac不自带
首先:反编译成汇编 & 函数表 并下载到本地电脑
#获取函数表
objdump -t bomb >table.txt
#获取汇编代码
objdump -d bomb >bomb.s
#相关文件下载到本地
rsync ali:/learn/csapp/3asm/bomb/table.txt ~/devMself/csapp/run/3asm/porject/bomb/
rsync ali:/learn/csapp/3asm/bomb/bomb.s ~/devMself/csapp/run/3asm/porject/bomb/
本地查看汇编代码:
首先寻找main函数,结合bomb.c理解
第一个答案非常简单,不必赘述
第二个有点难度,现在已经是晚上20:45分了,还是参考了答案再捋出来的,捋出来后又十分后悔参考了答案,剥夺了挑战的乐趣,一点都高兴不起来…
解题关键在于:
1.有6个参数寄存器,当参数多于6个是,会使用当前函数的stack frame 来储存额外参数
2.百度一下系统函数__isoc99_sscanf
3.然后关键点便是这个,我就卡在了第5&6 个参数,及下面这个映射😖
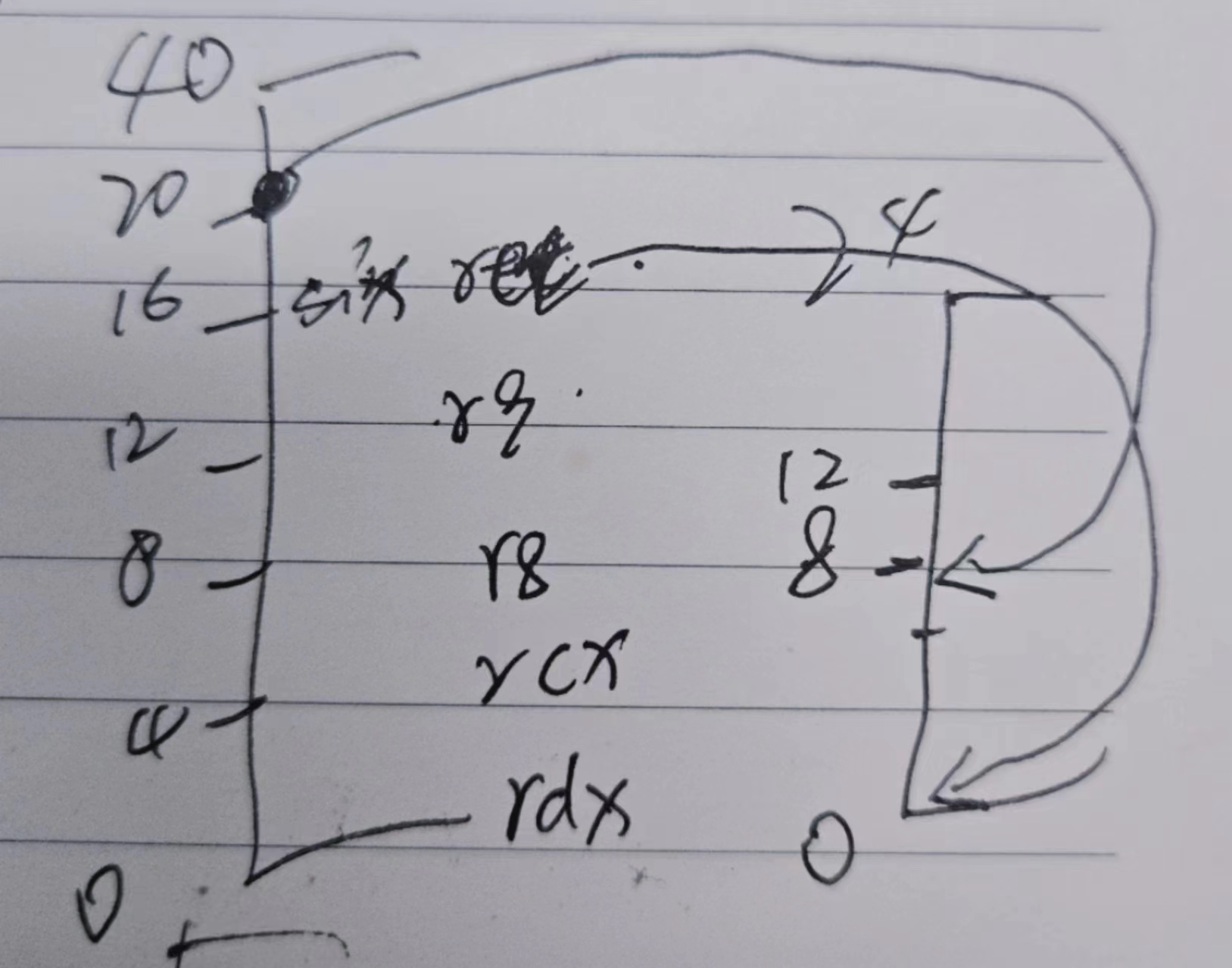
4.剩下的再去看phase2 就很简单了。
答案,让我痛失了今晚的乐趣… 明天一定要享受一下!
attack
在做完bomb的基础上,attack的就更容易上手了。
固定流程:下载数据,阅读writeup,开始上手
point:hex2raw的功能:将我们输入的十六进制数字(两两一组 空格隔开)转换为机器码。
Q1: 我们的输入新的返回地址覆盖掉stack上原来的返回地址
Q2 :更复杂一点,因为涉及到传参数,我们需要覆盖原来的返回地址,同时在新的返回地址注入我们的代码。
难点在于如何实现新的地址注入我们的代码? :stack(popq)!新的返回地址指向我们注入的代码地址。
Q3:对照ascii 转换字符串
之前,q4没做,隔了近1个月再来看,几乎忘了怎么做了… so 好的笔记太重要了。
Q4:一直没理解是什么意思,因为stack地址随机&金丝雀&内存分区,我们不能直接将代码写入stack然后修改stack top地址,执行;需要修改stack返回地址处的地址,使其跳转到我们想要的代码处(gadget),然后执行。
- 寻找gadget
- popq 将stack 内的数据弹出到寄存器
- 目标函数地址
./hex2raw < phase4 >phase4.txt
./rtarget -q< phase4.txt
archlab
鉴于attacklab的残疾,本次计划详细的记录archlab的实验步骤。
https://csapp.cs.cmu.edu/3e/labs.html 下载selfstudy-handout
阅读readme:主要与构建实验室有关,没明白,makefile 等后面用到了再了解
下载文件的目录:
archlab.pdf:实验手册writeup
simguide.pdf:模拟器手册
阅读writeup:
本次实验三部分:
- 写一点Y86指令的程序
- 拓展SEQ模拟,新增两条指令
- 优化基准程序与处理器设计
将sim文件,上传至阿里服务器
rsync -a sim.tar ali:/learn/csapp/4arch
tar xvf sim.tar
make clean;make
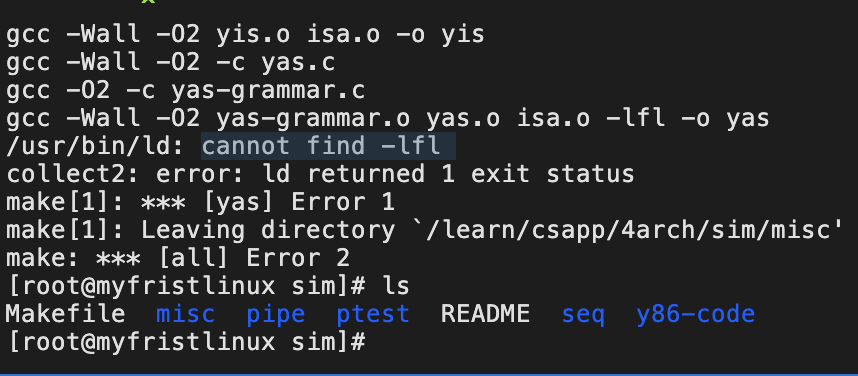
想起了readme:unix need 安装:sudo apt-get tcl tcl-dev tk tk-dev
没有apt-get ?
sudo yum install tcl tcl-devel
sudo yum install tk tk-devel
安装后再次运行还是报错…
安装 flex & bison
yum install flex bison
装完依旧报错…
初步确定提示链接无法找到 fl包,该包是flex软件的依赖包。
yum 安装后还是提示无法找到,此时locate 可以看到系统已经安装了flex软件了。单依旧搜不到libfl.a(/so),从八点多到现在22:14,终于解决了,libfl.a(/so),安装flex时并不会暗装,需要额外
yum install flex-devel
安装完flex的开发包,然后系统lib64 就有 libfl.a了。
终于make 成功了!!!!
越发觉得,学习,了解书中的内容,可能任务量的50%都没完成。不说课后习题,单这实验所耗费的时间绝对与看一个章节的内容不相上下,甚至更多!今天周三了,终于make完环境,明天可以正式开始了…
PartA:
将examples.c中的三个方法分别翻译成Y86-64。参考书中图4-7即可。main函数,sum函数。
分别新建文本sum.ys/rsum.ys/copy.ys ok,剩下的就是7.26周五的事情了。
啊哈,今天是周天:
1.sum_list
徒手将c转成汇编,对于当前的我而言过于难了。
- 将sim内y86-code文件夹下面的asum.ys 内容抄到sum.ys内
- 将example.c 编译成x86-64 汇编(提示没有main方法,需要编辑添加main)
gcc -Og -S -o examples.s examples.c - 将汇编中的x86-64 汇编,转换成y86-64汇编
- 实际上没有第三步,参考4-7,编写完成汇编。
然后就是yas编译成机器码,再然后yis模拟执行。
./yas sum.ys编译一堆的错:
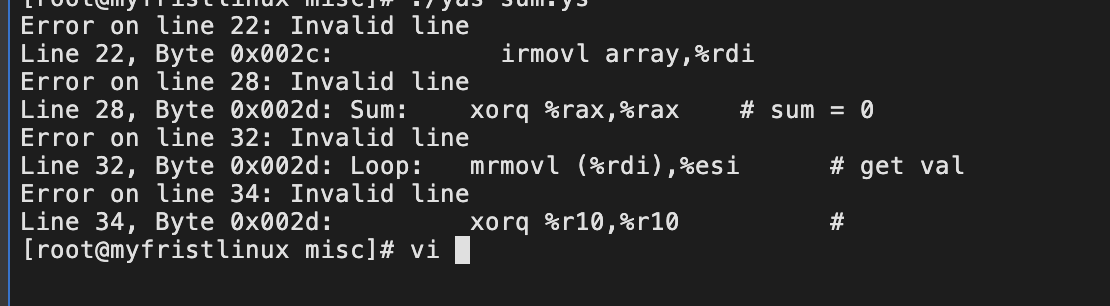
因为示例链表.align4 & long 故代码中都改成l,mrmovq 变成mrmovl;
然后最坑的便是寄存器不能随便使用,开始loop中我使用r9d来保存立即数4,一直提示无效,改成eax就编译通过
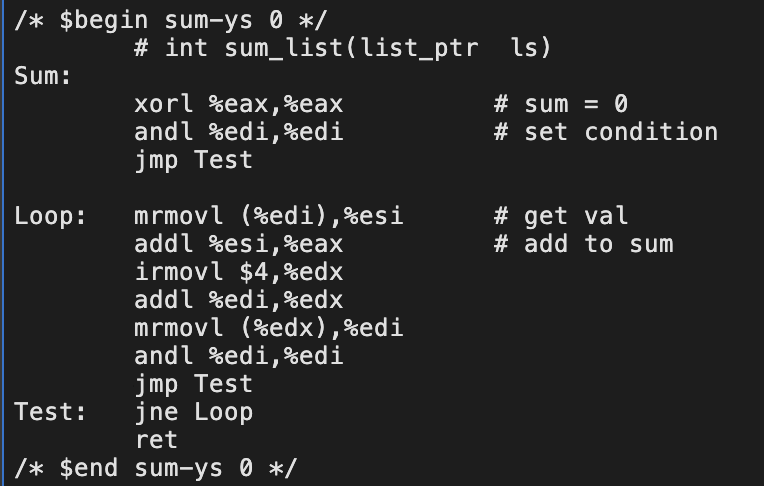
编译完后,输出了文件:sum.yo;./yis sum.yo it seems right:0xcba
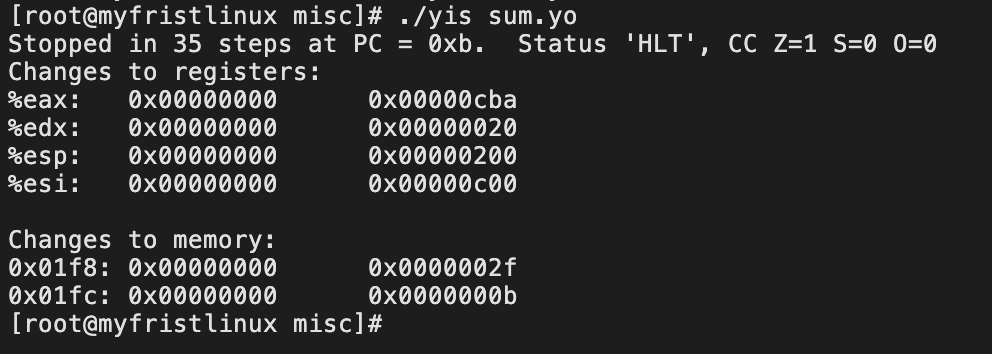
2.rsum_list
将sum.ys 复制为rsum.ys;这次得参考x86的汇编来改写了,有了前面的6个馒头,第七个就比较简单了,semms right。
3.copy.ys
又是提示%r8d,%r9d无效,why?
key point:

Ia32,并没有寄存器r8到r15,so,we need transfer param by stack!p164,3.7章!
将寄存器修改为:%ebx & %ebp (注意pop & push)(未经验证)
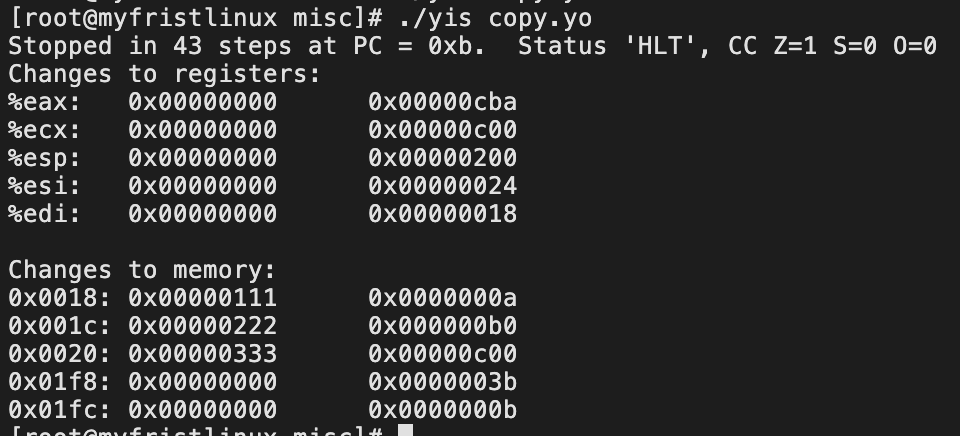
万万没想到,现在已经是17点58了,所有人描述为简单的partA,花了6个多小时,白天over了。也是打铁不趁热的结果。
PartB:
发现了一件事情,所做的parta部分其实是第二版的。partb时,iaddl与leave,完全不知道定义。
似乎摸到窍门了,回去再看看了。
– 显然回去没有再看了。
几乎可以再不了解具体明细的情况下,参考图4-18再结合已有代码即可完成。不再描述。
PartC:
1.在流水线版本的HLC文件中,实现iaddq 指令,基本也是参考partb来即可,需要注意ALU function.
2.优化ncopy.ys
两个方向:
- 指令级别优化,用本次新增的IADDQ 替代。
- 5.8节的循环展开。
首先,验证我们的pipe-full.hlc是否修改正确。
1.构建模拟器 make clean; make psim VERSION=full
2.测试模拟
The simulator recognizes the following command line arguments:
Usage: psim [-htg] [-l m] [-v n] file.yo
file.yo required in GUI mode, optional in TTY mode (default stdin)
-h Print this message
-g Run in GUI mode instead of TTY mode (default TTY mode)
-l m Set instruction limit to m [TTY mode only] (default 10000)
-v n Set verbosity level to 0 <= n <= 2 [TTY mode only] (default 2)
-t Test result against the ISA simulator (yis) [TTY model only]
#具体的测试指令
#frist some easy
./psim -t ../y86-code/asum.yo
#then std test
cd ../ptest
make SIM=../pipe/psim
然后,验证我们对ncopy.ys的优化是否正确。(当前只是用iaadq指令进行了一些优化,暂时还未涉及循环展开)
0.重新构建模拟器&驱动make VERSION=full
1.check
./psim -t sdriver.yo
./psim -t ldriver.yo
目前一切正常,后续的测试可以暂时放一下。回到循环展开的部分,修改程序,以满足循环展开。
2*1 展开:
写的很蹩脚,不过能正常运行
##################################################################
# You can modify this portion
# Loop header
xorq %rax,%rax
rrmovq %rdx,%r8
iaddq $-1, %r8
andq %r8,%r8
jle Edge
Loop: mrmovq (%rdi), %r10
mrmovq 8(%rdi),%r9
rmmovq %r10,(%rsi)
rmmovq %r9,8(%rsi)
andq %r10, %r10
jg AddOne
Next:
andq %r9,%r9
jle Npos
iaddq $1,%rax
Npos:
iaddq $-2, %rdx
iaddq $16, %rdi
iaddq $16, %rsi
rrmovq %rdx,%r8
iaddq $-1, %r8
andq %r8,%r8
jg Loop
jmp Edge
AddOne:
iaddq $1, %rax
jmp Next
Edge:
andq %r8,%r8
jl Done
mrmovq (%rdi), %r10
rmmovq %r10,(%rsi)
andq %r10,%r10
jle Done
iaddq $1,%rax
##################################################################
# Do not modify the following section of code
# Function epilogue.
Done:
ret
##################################################################
Now 接下来的测试:
fell sad:5/68 pass correctness test
Count 出错了:next 里面应该是jle 之前是 jne(上面代码已改正)…
next:进行基准测试

10.75, 0分😭
现在是2*1展开,应该可以优化下代码打进10.5
而要低于7.5,应该是需要额外设计指令
省略了几处andq 10.21:5.8分
? * ? 展开比较合适?
还有哪些优化方式?
Cache Lab
PartA
先是介绍了valgrind的文件格式,然后介绍了csim-ref的使用与结果,我们的目的就是使用c程序实现csim-ref的功能,可以说是逆向csim-ref。总结就是需要用程序模拟缓存的行为。对我而言有点难度,毕竟只是了解过c,还没写过完整的c程序。
前期准备:
1.c程序如何读取参数?
参考java,手动从字符串数组中解析。需要注意,字符串第一个参数是程序名称。
2.如何将结果输入到标准输出流?
程序中已存在:printSummary
3.c中如何读入文件?
fopen and fgets
实验:
gcc -Og -std=c99 -o prog csim-t.c cachelab.c
# 运行
./prog -s 11 -E 22 -b 33 -t traces/yi.trace

配置vscode:
task.json
"args": [
"-fdiagnostics-color=always",
"-g",
"${file}",
"${fileDirname}/cachelab.c",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
]
lunch.json的configurations
"args": [
"-s","3",
"-E","4",
"-b","5",
"-t","dir"
]
当前完整的demo
#include "cachelab.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int s, E, b;
char* t;
FILE* fp;
char row[20];
void praseParam(int argc, char* argv[]);
int main(int argc, char* argv[])
{
//解析参数
praseParam(argc, argv);
printf("%d, %d, %d, %s
",s, E, b, t);
//测试文件读取
fp = fopen(t, "r");
if (fp != NULL)
{
while (fgets(row, sizeof row, fp) != NULL)
{
printf("%s
", row);
}
}
//输出结果
printSummary(s, E, b);
return 0;
}
void praseParam(int argc, char* argv[])
{
for (int i = 1; i < argc; i++)
{
if (strcmp(argv[i], "-s") == 0)
{
s = atoi(argv[i + 1]);
i ++;
} else if (strcmp(argv[i], "-E") == 0)
{
E = atoi(argv[i + 1]);
i ++;
} else if (strcmp(argv[i], "-b") == 0)
{
b = atoi(argv[i + 1]);
i ++;
} else if (strcmp(argv[i], "-t") == 0)
{
t = argv[i + 1];
}
}
}
现在解决了输入与输出,接下来便是中间的过程,如何模拟缓存的操作?
先写下人工模拟的操作步骤:
1.依据输入参数,明确内存结构;
2.读取一条指令,判断其是 I/L/S/M :
指令:就直接忽略
加载:则需要计算应该存放的位置,并结合实际来判断是否命中,未命中则加载
保存:需要计算位置,判断是否命中,命中则替换,未命中则直接插入
修改:写回+写分配,加载进来,cpu处理,再保存
疑问:保存与修改在缓存中的处理方式?加载=1次,保存=1次,修改=加载+保存???
对2的细化便是:
2.1:解析地址,[t, s, b]
2.2:计算应该放入的缓存位置
2.3:判断是否命中,更新 miss/hit/eviction
2.3.1:如果需要eviction,需要LRU算法(Least Recently Used,如果数据最近被访问过,那么将来被访问的几率也更高)
综上所述,因为是模拟,也没有实际的数据,故我们关心的是trace文件中的 动作+地址,再结合缓存的构造(组+行+块),同时又假设数据都是对齐的没有穿越块边界的情况。所以可以使用二维数组模拟组+行,块的物理结构是[valid + tag + block],valid需要一个标记位,tag需要0~63位,因为LRU算法,还需要记录块的最近一次访问时间。
至此,数据结构与算法基本清晰;(很遗憾在寻找资料理解writeup的例子时,剽窃了别人的解题思路,尤其是数据结构,也就丧失了原本解决问题所来带来的满足感与成就感😔😔不开心。)
测试:
#include "cachelab.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include<string.h>
int s, E, b;
char* t;
FILE* fp;
int hits, misses, evictions;
typedef struct
{
char flag;
long tag;
long lastAccess;
} Data;
Data **memory;
void praseParam(int argc, char* argv[])
{
for (int i = 1; i < argc; i++)
{
if (strcmp(argv[i], "-s") == 0)
{
s = atoi(argv[i + 1]);
i ++;
} else if (strcmp(argv[i], "-E") == 0)
{
E = atoi(argv[i + 1]);
i ++;
} else if (strcmp(argv[i], "-b") == 0)
{
b = atoi(argv[i + 1]);
i ++;
} else if (strcmp(argv[i], "-t") == 0)
{
t = argv[i + 1];
}
}
}
void simulate(Data **memory, long address) {
//从地址中解析出s
long addres_s = (address >> b) & (~(-1 << s));
long address_tag = address >> (b + s);
//printf("param prase %d, %d |", s, E);
//printf("address prase %ld, %ld
", addres_s, address_tag);
Data current;
char hit;
for (int i = 0; i < E; i ++) {
current = memory[addres_s][i];
if (current.tag == address_tag && current.flag == 1) {
hit = 1;
break;
}
}
if (hit == 1) {
hits ++;
} else {
misses ++;
Data *farAccess = &memory[addres_s][0];
for (int i = 0; i < E; i ++) {
current = memory[addres_s][i];
if (current.lastAccess < farAccess -> lastAccess) {
farAccess = ¤t;
}
}
if (farAccess -> flag == 1) {
evictions ++;
}
farAccess -> flag = 1;
farAccess -> tag = address_tag;
time_t timep;
farAccess -> lastAccess = time(&timep);
}
}
int main(int argc, char* argv[])
{
//解析参数
praseParam(argc, argv);
//初始化数据结构
int S = 1 << s;
//printf("S: %d ", S);
memory = (Data **) malloc(S * sizeof(Data *));
for (int i = 0; i < S; i++) {
memory[i] = (Data *) malloc(E * sizeof(Data));
memset(memory[i], 0, E * sizeof(Data));
}
//测试文件读取
fp = fopen(t, "r");
if (fp != NULL)
{
char operation;
unsigned int address, num;
while (fscanf(fp, " %c %x,%d", &operation, &address, &num) == 3)
{
//printf("read: %c, %d |", operation, address);
switch (operation)
{
case 'I':
// do nothing
break;
case 'L':
simulate(memory, address);
break;
case 'S':
simulate(memory, address);
break;
case 'M':
simulate(memory, address);
simulate(memory, address);
break;
default:
break;
}
}
}
//关闭文件等
fclose(fp);
free(memory);
//输出结果
printSummary(hits, misses, evictions);
return 0;
}
没搞明白,为何单个文件本地测试正确,服务器运行测试程序就错误?
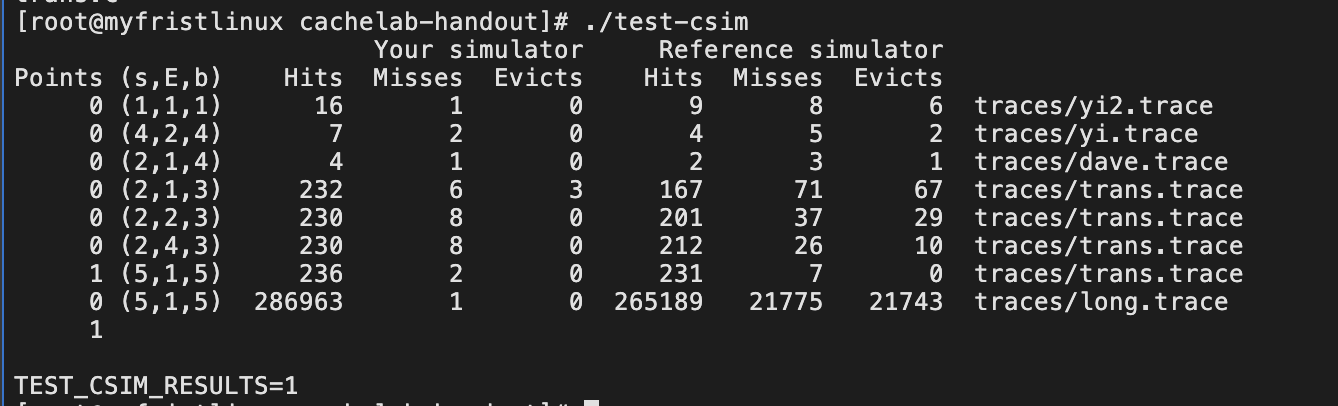

what‘s wrong?
PartB
我们需要完善trans.c的transpose_submit方法,使其尽可能的缓存友好。
restrict:
最多定义12个本地变量
不能使用递归
stack内不能同时超过12个变量,如果调用方法使用了4个参数,则只能有8个变量了。
在正式开始工作之前,先回顾下书中的内容,整理解题思路:
描述得知缓存:1024B,直接映射,block = 32B,即32组,int 4B,1block = 8item,缓存最多256item;
预设(没有理解原因):a b 矩阵,相同索引,占用相同位置的缓存。
思路1:将大的矩阵转换成多个小的矩阵,哪里出了点错误(32 * 32)逆优化了😅,
示例:TEST_TRANS_RESULTS=1:1183
第一版:TEST_TRANS_RESULTS=1:3488
3232
采用88一组,缓存中同时容纳a的64个元素,b的64个元素,缓存占满。
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i, j, inneri;
int tmp, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7;
for (i = 0; i < N; i+= 8) {
for (j = 0; j < M; j+= 8) {
for (inneri = 0; inneri < 8; inneri ++) {
tmp = A[i + inneri][j + 0];
tmp1 = A[i + inneri][j + 1];
tmp2 = A[i + inneri][j + 2];
tmp3 = A[i + inneri][j + 3];
tmp4 = A[i + inneri][j + 4];
tmp5 = A[i + inneri][j + 5];
tmp6 = A[i + inneri][j + 6];
tmp7 = A[i + inneri][j + 7];
B[j + 0][i + inneri] = tmp;
B[j + 1][i + inneri] = tmp1;
B[j + 2][i + inneri] = tmp2;
B[j + 3][i + inneri] = tmp3;
B[j + 4][i + inneri] = tmp4;
B[j + 5][i + inneri] = tmp5;
B[j + 6][i + inneri] = tmp6;
B[j + 7][i + inneri] = tmp7;
}
}
}
}
不错:降到了1300一下;
88之后,如果不使用变量,miss=343,使用变量miss=287;这里的关键点便是对角线的那四个组。a00与b00占用同的缓存位置,写b00会替换掉a00,读a01miss,后续读完a10,写b01时又是miss;故对角线导致多两次miss。
6464
很遗憾,没有想到好的解决办法,84一组1651,没有想到更进一步的方法了…
参考别人资料,提出,在88中继续划分。如何理解?
44 有效条目=a 16 + b 16 = 32
84 有效条目=a 16 + b 32 = 48
缓存允许放256个,如何更有效的利用呢,完全无思路。
https://billc.io/blog/csapp-cachelab 看了一个答案的,有点巧妙。
https://andreww1219.github.io/2024/02/18/%E3%80%90CMU%2015-213%20CSAPP%E3%80%91%E8%AF%A6%E8%A7%A3cachelab%E2%80%94%E2%80%94%E6%A8%A1%E6%8B%9F%E7%BC%93%E5%AD%98%E3%80%81%E7%BC%96%E5%86%99%E7%BC%93%E5%AD%98%E5%8F%8B%E5%A5%BD%E4%BB%A3%E7%A0%81/
有点数学上的技巧,我转不过来。似乎有点明白,但实践怎么做?
an other day. 首先删掉原来的代码,放空大脑,从0开始。
已知:
1.缓存结构为5、1、5,32组,每行1行,每行8个int,最多存放256个int。
2.因为5-1-5的结构,决定了连续256个int后,第257个的存放位置将会与第一个重复。
3.矩阵是64*64,意味第5行将会与第一行占用相同的缓存位置。
4.又因为矩阵AB是定义在连续内存上的,故AB,相同的下标,占用相同的缓存空间。(忽略)
思路:
这里如何高效利用缓存在思维上与排序算法有一定相似。排序算法的思想核心在于有效的利用已知的信息,每过一遍数据,利用已知信息尽可能的让元素向最终正确的位置靠拢。这里的解决思路大致是,一但我们将数据加载进了缓存中,如何高效的利用已存在于缓存中的数据呢?
先模拟下44的缓存占用:
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i, j, inneri, innerj;
int tmp;
for (i = 0; i < M; i +=4) {
for (j = 0; j < N; j += 4) {
for (inneri = i; inneri < i + 4 && inneri < M; inneri ++) {
for (innerj = j; innerj < j + 4 && innerj < N; innerj ++) {
tmp = A[inneri][innerj];
B[innerj][inneri] = tmp;
}
}
}
}
}
简单的4*4:miss = 1891
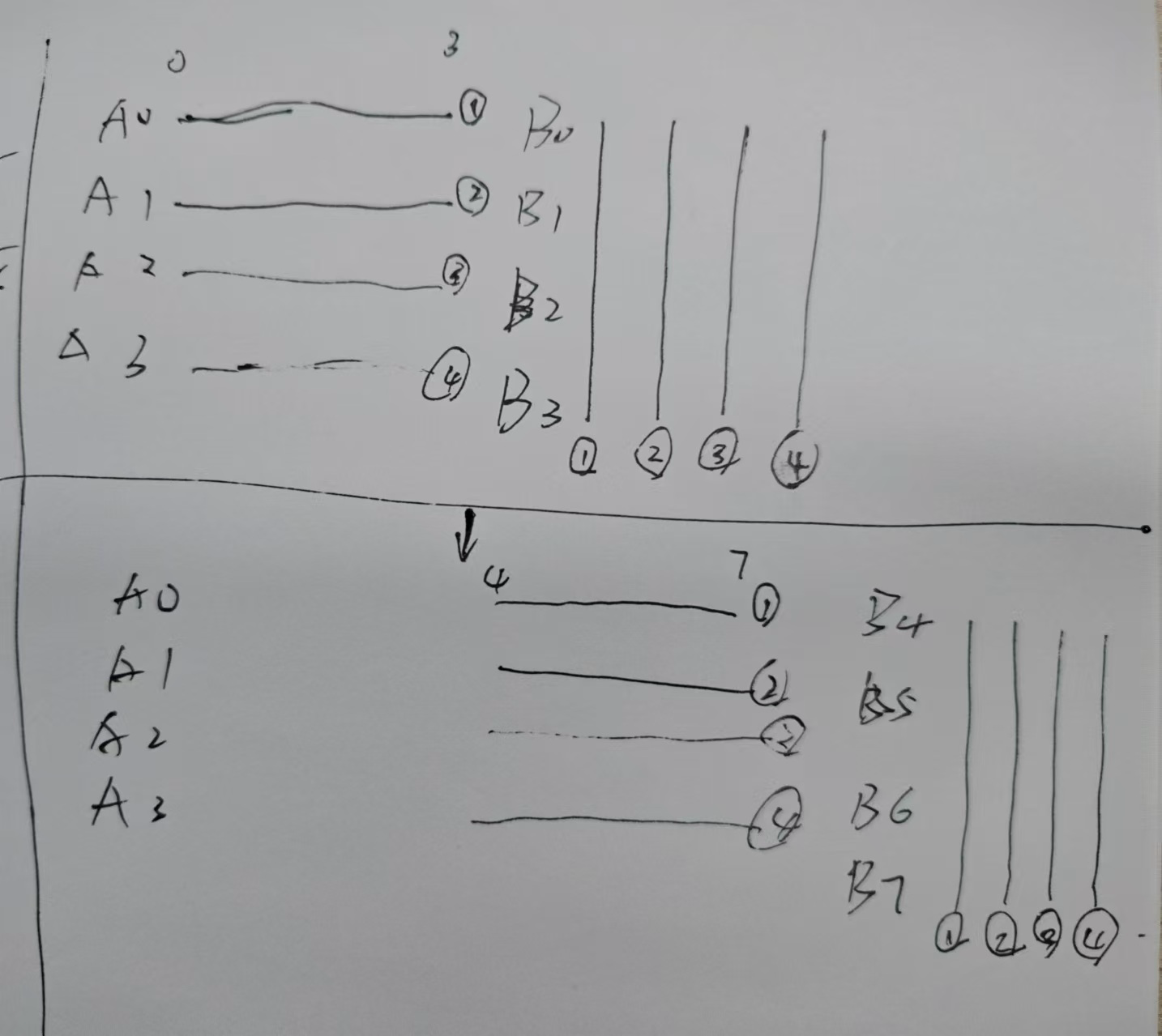
在整个4x4的循环当中,其实a每次读入进来的4行8列可以有效被利用,a0~3的前4列对应b0~3的前4列,a0~3的后四列对应b4~7的前4列。即我们浪费了b中每次读进来4行的后4列。如何有效利用呢?
要想利用b0~3的后4列,需要a4~7的前4列,而此时a0~3的后四列还没使用,读取a4~7会替换掉a0~3.
1.要利用a0~3的后4列,需要b4~7替换b0~3
2.要利用b0~3的后4列,需要a4~7替换a0~3
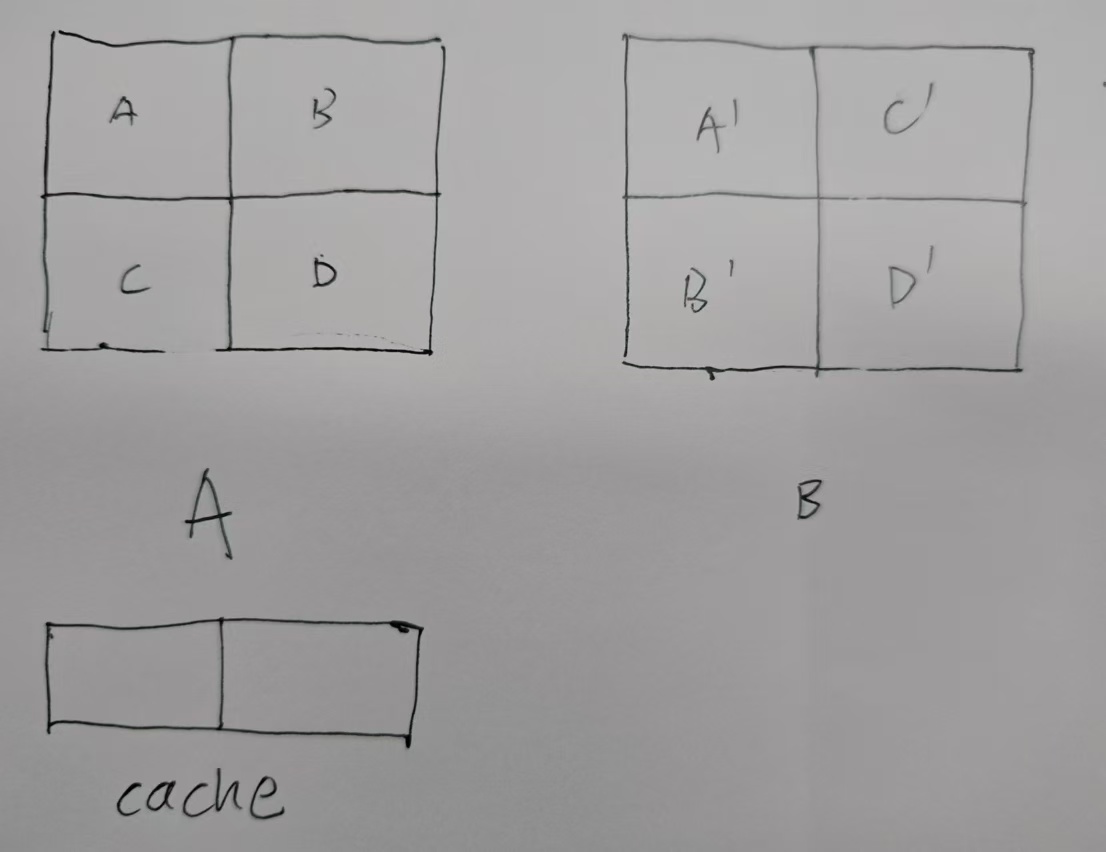
一种可行的方式,也即上面链接里的答案,细节是否一致未深究。
1.缓存中读入a0~3 & b0~3,即上图a,b 与 a‘,c’
2.将b中的数据放入c‘(注意,c‘中一行存放的是b中一列)
3.读入a4~7(c & d),此时缓存中有a4~7,b0~3,同时a已转制到a’,b存放在c‘,c,d也都在缓存中
4.key point(一定要按行为单位处理,因为缓存替换)
4.1将c’中的1行,读取到变量中
4.2将c中的数据读入变量,并写入c‘
4.3读入b’中的一行,替换掉c‘中的一行
4.4将4.1中的变量写入新读入的b’一行,至此,我们通过变量,成功将b弄到b‘,c弄到c’
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i, j, inneri, innerj;
int tmp, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7;
for (i = 0; i < M; i +=8) {
for (j = 0; j < N; j += 8) {
//先处理 a -> a'
for (inneri = i; inneri < i + 4 && inneri < M; inneri ++) {
for (innerj = j; innerj < j + 4 && innerj < N; innerj ++) {
tmp = A[inneri][innerj];
B[innerj][inneri] = tmp;
}
}
//再处理 b -> c' c'中的一行存储的是b的一列
for (inneri = i; inneri < i + 4 && inneri < M; inneri ++) {
tmp = A[inneri][j + 4];
tmp1 = A[inneri][j + 5];
tmp2 = A[inneri][j + 6];
tmp3 = A[inneri][j + 7];
B[j][inneri + 4] = tmp;
B[j + 1][inneri + 4] = tmp1;
B[j + 2][inneri + 4] = tmp2;
B[j + 3][inneri + 4] = tmp3;
}
//key point
for (inneri = 0 ; inneri < 4; inneri ++) {
//1.将c‘中的一行暂存到变量
tmp = B[j + inneri][i + 4];
tmp1 = B[j + inneri][i + 5];
tmp2 = B[j + inneri][i + 6];
tmp3 = B[j + inneri][i + 7];
//2.从c中读取1列
tmp4 = A[i + 4][j + inneri];
tmp5 = A[i + 5][j + inneri];
tmp6 = A[i + 6][j + inneri];
tmp7 = A[i + 7][j + inneri];
//3.将c的那一列放到c‘的对应行
B[j + inneri][i + 4] = tmp4;
B[j + inneri][i + 5] = tmp5;
B[j + inneri][i + 6] = tmp6;
B[j + inneri][i + 7] = tmp7;
//4.将1中从c’中读出的数据(实际来自b)读入b‘
B[j + 4 + inneri][i] = tmp;
B[j + 4 + inneri][i + 1] = tmp1;
B[j + 4 + inneri][i + 2] = tmp2;
B[j + 4 + inneri][i + 3] = tmp3;
}
//最后的最后处理d -> d'
for (inneri = i + 4; inneri < i + 8 && inneri < M; inneri ++) {
for (innerj = j + 4; innerj < j + 8 && innerj < N; innerj ++) {
tmp = A[inneri][innerj];
B[innerj][inneri] = tmp;
}
}
}
}
}
Damed wrong! easy,典型的i,j 混乱了!修改后如上。
miss = 1387;1651 到1387,i can see sunshine!
试着将a->a’ 与 d -> d’也用变量替换,减少第一个问题中的对角线碰撞再试试。
Miss = 1291; yes!
Finally version:
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i, j, inneri;
int tmp, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7;
for (i = 0; i < M; i +=8) {
for (j = 0; j < N; j += 8) {
//先处理 a -> a'
for (inneri = i; inneri < i + 4 ; inneri ++) {
tmp = A[inneri][j];
tmp1 = A[inneri][j + 1];
tmp2 = A[inneri][j + 2];
tmp3 = A[inneri][j + 3];
B[j][inneri] = tmp;
B[j + 1][inneri] = tmp1;
B[j + 2][inneri] = tmp2;
B[j + 3][inneri] = tmp3;
}
//再处理 b -> c' c'中的一行存储的是b的一列
for (inneri = i; inneri < i + 4 ; inneri ++) {
tmp = A[inneri][j + 4];
tmp1 = A[inneri][j + 5];
tmp2 = A[inneri][j + 6];
tmp3 = A[inneri][j + 7];
B[j][inneri + 4] = tmp;
B[j + 1][inneri + 4] = tmp1;
B[j + 2][inneri + 4] = tmp2;
B[j + 3][inneri + 4] = tmp3;
}
//key point
for (inneri = 0 ; inneri < 4; inneri ++) {
//1.将c‘中的一行暂存到变量
tmp = B[j + inneri][i + 4];
tmp1 = B[j + inneri][i + 5];
tmp2 = B[j + inneri][i + 6];
tmp3 = B[j + inneri][i + 7];
//2.从c中读取1列
tmp4 = A[i + 4][j + inneri];
tmp5 = A[i + 5][j + inneri];
tmp6 = A[i + 6][j + inneri];
tmp7 = A[i + 7][j + inneri];
//3.将c的那一列放到c‘的对应行
B[j + inneri][i + 4] = tmp4;
B[j + inneri][i + 5] = tmp5;
B[j + inneri][i + 6] = tmp6;
B[j + inneri][i + 7] = tmp7;
//4.将1中从c’中读出的数据(实际来自b)读入b‘
B[j + 4 + inneri][i] = tmp;
B[j + 4 + inneri][i + 1] = tmp1;
B[j + 4 + inneri][i + 2] = tmp2;
B[j + 4 + inneri][i + 3] = tmp3;
}
//最后的最后处理d -> d'
for (inneri = i + 4; inneri < i + 8 ; inneri ++) {
tmp = A[inneri][j + 4];
tmp1 = A[inneri][j + 5];
tmp2 = A[inneri][j + 6];
tmp3 = A[inneri][j + 7];
B[j + 4][inneri] = tmp;
B[j + 5][inneri] = tmp1;
B[j + 6][inneri] = tmp2;
B[j + 7][inneri] = tmp3;
}
}
}
}
i fell peaceful, thank god! i can beate every thing! 20240806
61*67
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i, j, inneri, innerj;
int tmp;
for (i = 0; i < N; i+= 16) {
for (j = 0; j < M; j+= 16) {
for (inneri = i; inneri < i + 16 && inneri < N; inneri ++) {
for (innerj = j; innerj <j + 16 && innerj < M; innerj ++) {
tmp = A[inneri][innerj];
B[innerj][inneri] = tmp;
}
}
}
}
}
越发感觉培根的论金钱的意义了,因为cache lab完成的相当糟糕,完全没有成就感!似乎一切都要崩盘了似的。很糟心!碎片化的杀伤!20240805
Shellab
常规操作:下载文件后,解压到工作目录
then:阅读writeup,大致思路便是,过一下第八章节的部分,然后参考tshref的行为,完成trace01~16
summarize:
1.异常的概念 & 4种异常
2.进程的相关概念 & 对进程的操作
3.信号 & 并发示例
4.非本地跳转
Trace01
内容:
#
# trace01.txt - Properly terminate on EOF.
#
CLOSE
WAIT
查看对比:

没懂,eof时正确的终止?close & wait 也不是tsh的内部命令。应该是只是简单的测试。
pass
Trace02
内容:
#
# trace02.txt - Process builtin quit command.
#
quit
WAIT
需要我们实现tsh的内部命令:quit
对比:

差异:
参考程序正确的退出了,回到了主界面;而tsh没有正确的退出。
简单看了一部分程序源码,因为ai的出现,关于源码部分就不再示例了,同时我们应该看一下书中8.4.6节的shell实现,tsh的思路与其基本一致。
不再过多描述,基本书中已经将其实现了。
Trace03
内容:
#
# trace03.txt - Run a foreground job.
#
/bin/echo tsh> quit
quit
对比:

tsh已经正确的离开了,但没有实现 /bin/echo tsh> quit 该命令。
目的:
实现一个跑在前台的任务。
这里需要回顾一下writeup中shell的设计思想:
1.内部命令立即执行,其余默认为可执行文件,需要fork一个子进程进行执行
2.job跑在后台,则shell不需要等待其终止后再运行,job跑在前台则需要等待子进程终止
回到这里,我们需要开一个子进程,调用execve,同时判断是前台运行,需要shell进程,waitpid。
基本上,书中的实例就满足需求了。
Trace04
这里不介绍内容了,后台跑程序,直接拿3的版本运行对比差异:
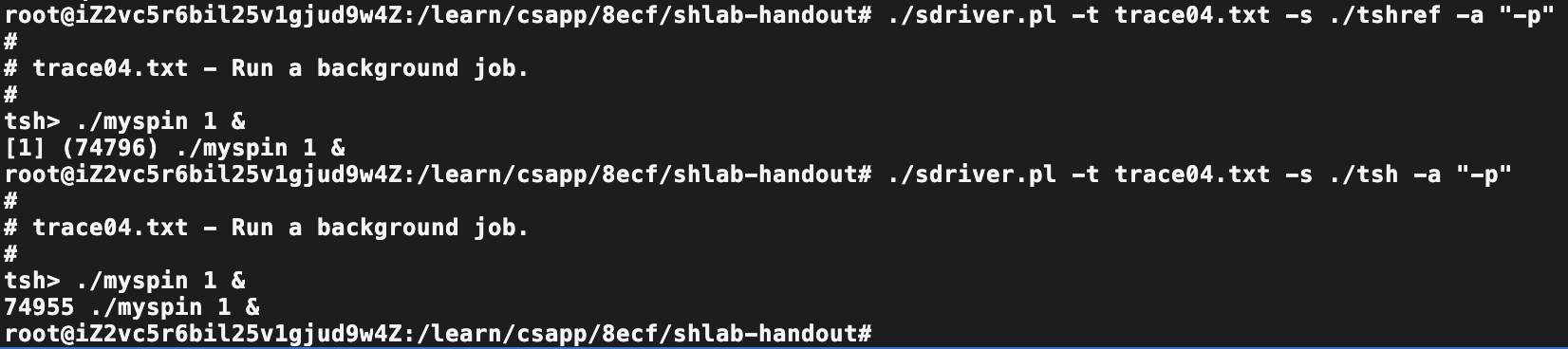
我们可以看到差异体现在执行后的输出字符串上,依次应该是 jobid,pid,执行命令行。
故此处,我们需要做一些修改,利用job来管理每一个进程。
随即遇到了一个问题:创建子进程添加job,子进程结束时如何回收job呢?不处理则jobid 显示的2.
删除job只能在父进程中处理,但是不能等后台进程结束,必须立即返回。
waitpid:pid=-1,options = wnohang|wuntraced ?
pid_t end = waitpid(-1, NULL, WNOHANG | WUNTRACED);
if (end) {
deletejob(jobs, end);
}
经过实验,依旧不行,因为上述代码,非阻塞的检查,确实没阻塞,但运行时,子进程没有结束,返回0,同时后续不会再重复检查。
so 我们要实现的是类似存在一个后台进程,一旦子进程结束,就执行一些操作。
信号!!!
SIGCHILD:一旦子进程结束,就会向父进程发送该信号,我们只需要在接收到该信号时deletejob 即可。
这里有一个比较有意思的事情,初步编写的程序中后台进程的jobid 总是2,意味第一个cmdline 执行结束后没有正确的回收。
当前代码示例:
void eval(char *cmdline)
{
char *argv[MAXARGS];
char buf[MAXLINE];
int bg;
pid_t pid;
strcpy(buf, cmdline);
//判断是否后台执行,同时解析参数
bg = parseline(buf, argv);
//开始初步处理
if (argv[0] == NULL) {
return;
}
if (!builtin_cmd(argv)) {
//是外部执行文件
if ((pid = fork()) == 0) {
printf("%s, %s", argv[0], argv[1]);
if (execve(argv[0], argv, environ) < 0) {
printf("%s:commond not found.
", argv[0]);
exit(0);
}
} else {
//创建一个job,先暂时不考虑程序运行结束后需要销毁
addjob(jobs, pid, 0, cmdline);
}
//是前台程序
if(!bg) {
waitfg(pid);
//sleep(1);
{
/* code */
}
} else {
//打印 jobid,pid,cmdline
struct job_t *curjob = getjobpid(jobs, pid);
printf("[%d] (%d) %s", curjob -> jid,curjob ->pid, curjob -> cmdline);
}
}
return;
}
void sigchld_handler(int sig)
{
pid_t pid = waitpid(-1, NULL, 0);
if (pid == -1) {
printf("errno: %s", strerror(errno));
} else {
deletejob(jobs, pid);
}
return;
}
void waitfg(pid_t pid)
{
waitpid(pid, NULL, 0);
return;
}
经过调试,如果我们将waitfg,修改为sleep(1),则程序正常,否则,基本上sigchld_handler 会报告:No child processes
此时我们需要分析一下代码的执行:
shell:1.fork,2.创建job,3.cmd是否是前台,是则waitfg,不是就打印
子1(前):1.execve,2.cmd是否是前台,是则waitfg。
子2(后):1.execve,2.cmd是否是前台,不是就打印(因为pid=0 实际不会打印)
Point1:子进程不需要执行打印与waitfg
Point2:根据writeup,对于前台程序,建议统一由信号处理程序去捕获信号并删除。无需在waitfg中waitpid,waitfg只需要sleep,结束后进程结束后再唤醒。
现在的难点在于如何从sleep中唤醒(pause&开辟共享内存)。pause的难点又在于如何区分是后台进程的结束还是前台进程的结束。
考虑用joblist 来管理这些。阻塞太久没正向反馈了,先sleep1实现效果再说。
Trace05
差异对比:
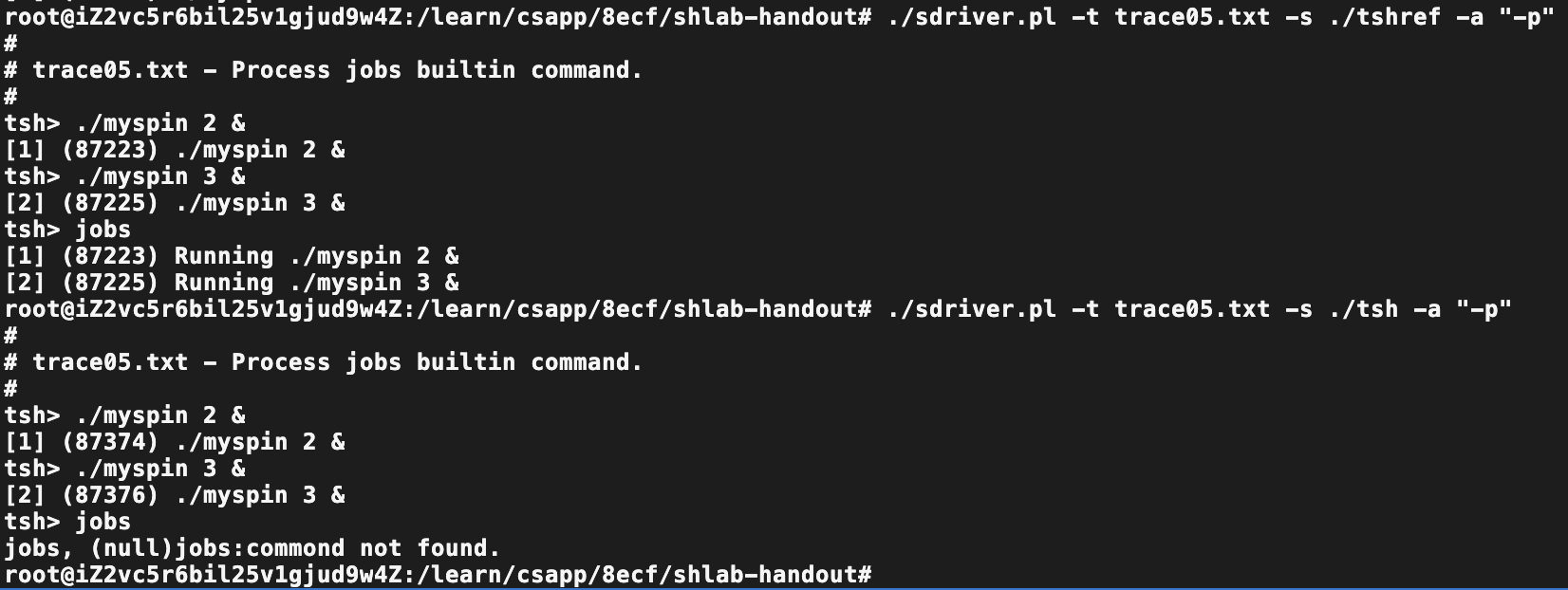
目的:实现jobs命令
已经内置了listjobs函数,现在需要额外处理状态。既然job已经存在状态了,不使用共享内存通过jobs可控制前台程序的sleep break条件了。
Trace06
对比:
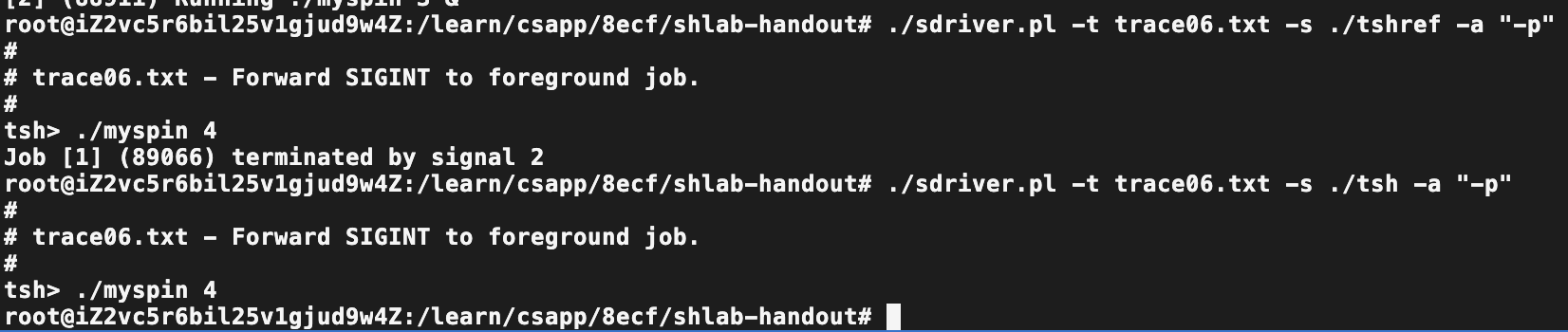
目的:前台程序响应SIGINT信号
完成sigint_handler函数即可,尤其需要注意的是,此处终止的不是tsh,而是tsh运行的前台程序。
Trace07
7是校验是否只是终止了前台程序。拿6的版本运行就ok了。
Trace08
对比差异:
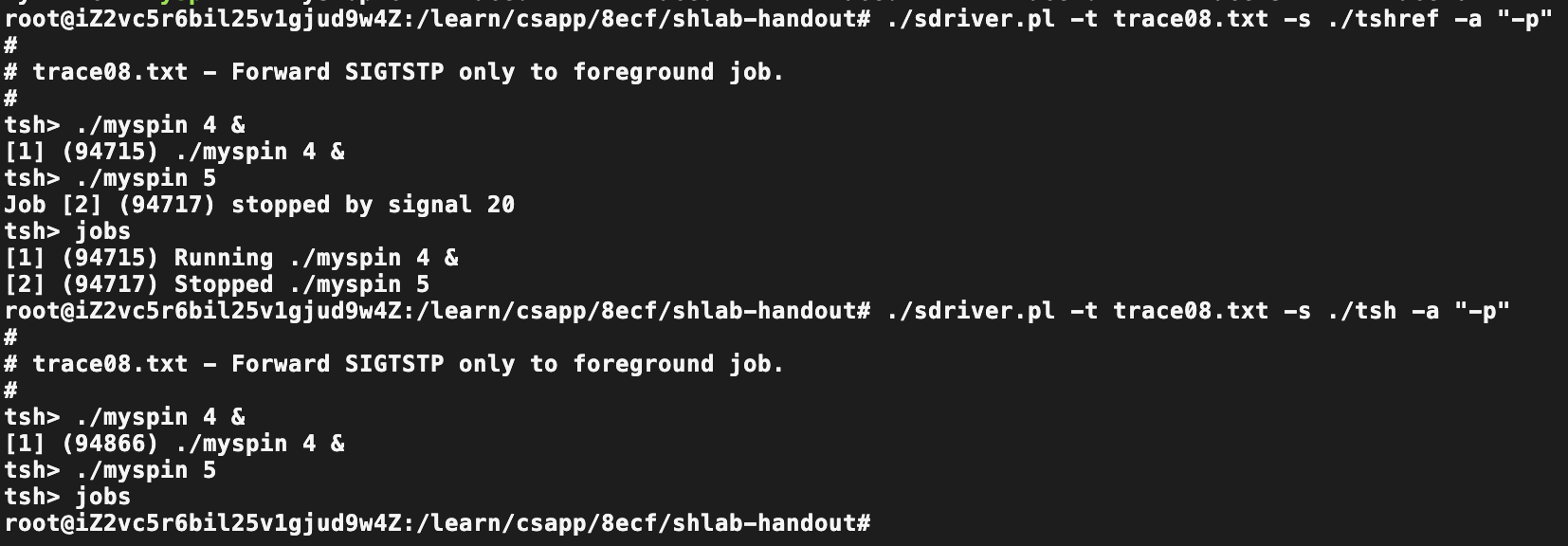
目的:前台程序响应SIGTSTP信号
单纯的仿照sigint_handler,完成了sigtstp_handler
void sigtstp_handler(int sig)
{
//1.获取前台job
pid_t fg = fgpid(jobs);
printf("stopped %d
", fg);
if (fg) {
struct job_t *fgjob = getjobpid(jobs, fg);
//2.输出相关信息
printf("Job [%d] (%d) stopped by signal 20
", fgjob->jid, fgjob->pid);
//3.向其发送终止信号
if (kill(fg, SIGTSTP) == -1) {
unix_error("kill");
} else {
printf("fgjob->state = ST :");
fgjob->state = ST;
printf("%d", fgjob->state);
}
}
return;
}
发现trace08中的jobs总是不能执行。
阅读了下书中关于信号的部分,对程序进行了如下两处优化:
1.因为信号不能排队,防止多个终止信号同时到达,将处理程序中的waitpid修改为while循环中执行。
2.因为进程执行的不可控,防止addjob之前就接收终止信号,deletejob,新增了信号的阻塞。
此时再看trace08的对比:
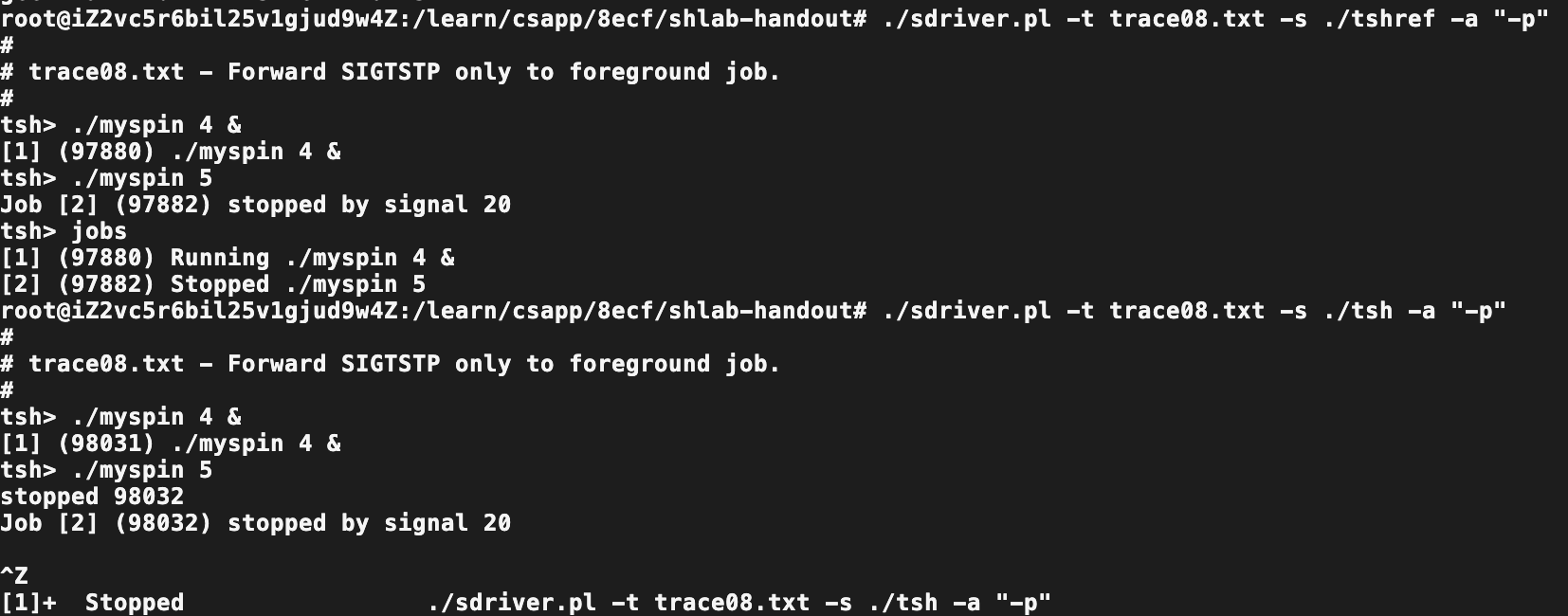
分析:
因为前台程序还存在,主程序会一直sleep下去,自然不会读取接下来的命令,而我们的前台进程又被停止了,此时程序不会有任何响应。需要再回顾一下writeup。
心都要碎了,卡了2~3个小时,结果是因为前面修改第一点的while循环,导致阻塞等待,就说为啥有fork却还是表现的像是串行😭。
将while改成单次waitpid后jobs中停止的线程被删掉了…(进程状态改变的时候就会发送sigchild信号,故此时不能阻塞等待,否则行为如上。如果将行为修改为WNOHANG | WUNTRACED则又会获取停止的线程,被卡这么久… 果然还是得实践!)
void sigchld_handler(int sig)
{
pid_t pid;
//单子进程状态发生变化的时候,父进程就会收到sigchild信号,此时进程未结束,不能阻塞等待
//因为信号不排队,这里修改为while循环
while((pid = waitpid(-1, NULL, WNOHANG)) > 0) {
deletejob(jobs, pid);
}
return;
}
仅需要修改option就ok。简直哭晕…
Trace09
对比差异
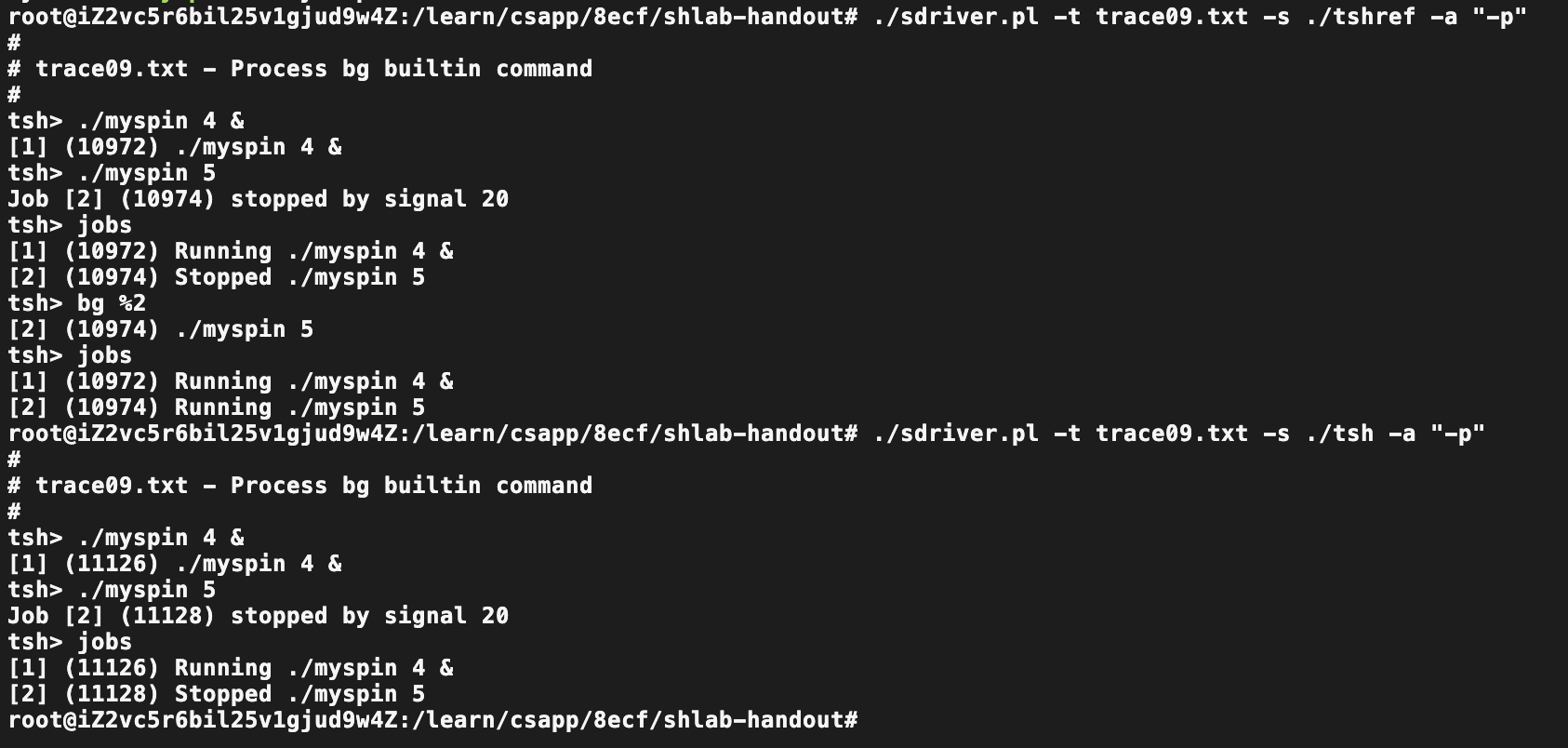
目的:实现bg命令。
先明确需求:
1.bg : Change a stopped background job to a running background job.
2.The bg command restarts by sending it a SIGCONT signal, and then runs it in the background. The argument can be either a PID or a JID.
3.Each job can be identified by either a process ID (PID) or a job ID (JID), which is a positive integer assigned by tsh. JIDs should be denoted on the command line by the prefix ’%’. For example, “%5” denotes JID 5, and “5” denotes PID 5. (We have provided you with all of the routines you need for manipulating the job list.)
strcmp函数 指针数组&字符串 printf等 还是有点欠缺,代码写的有点靠直觉。
Trace10
完成9的时候,顺便就把10给做了。测试完输出结果一致,pass。
Trace11
十一想强调的是命令是发给进程组的,而非某个单独的进程。
关联的要素:
1.kill 发送的对象是进程组
2.cmdline 每次执行外部文件fork的子进程,需要重新设置pid&pgid
由于前面已经处理,此处输出与tshref一致。
Trace12
同上 pass
Trace13
一致 pass
Trace14
还以为是程序的完全体了,剩下的都不需要处理了呢.
因为命令太多,就不截图了,此处只需要我们根据输出结果晚上相关异常场景。
Trace15
胜利的曙光就在眼前!准备迎接奖赏! pass
Trace16
God i try,i arrived!
calm, wrong!!!
完全没有任何思路。
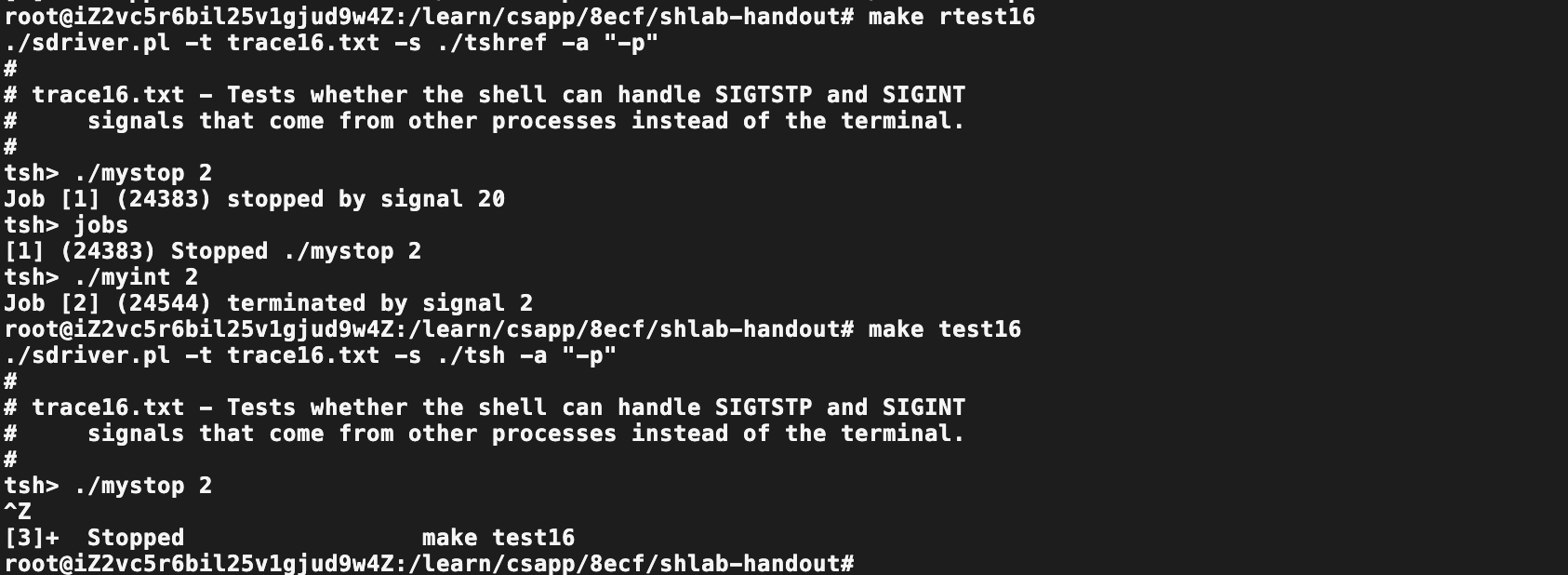
查看mystop.c源码,可以得知,其运行后,
1.sleep 几秒
2.向自己发送SIGTSTP
debug发现,子进程对自己发送了SIGTSTP后,只有父进程的sigchild处理函数有反应,tstp处理函数没有响应。
进一步查询得知信号处理函数的设置,对子进程无效,子进程可以继承父进程的blocking & pending向量,但无法继承处理函数的设置。
在子进程中设置了信号处理函数,依旧还是没有生效。
额 参考了别人的实现,奖赏减半…
对waitpid的option作出修正,可以接受暂停 或终止的信号,其中再通过status 进一步判断是否是是否是暂停。暂停就进行相关状态修改,终止才deletejob。
Question:
为什么在子进程中设置信号处理程序没有生效呢?如果信号处理程序不会被继承,我在子进程中重新设置就可以呀,没什么没有生效?最后必须通过对child信号细化,来进行进一步的处理。
Over !
Malloclab
One of our favorite labs. When students finish this one, they really understand pointers!
在每次开始新的任务之前,我们需要调整一下自己的心态,我们不是为了学分或者某个其他什么数字,十分痛苦的去干某件事情,甚至也不是为了更高的收入,改善工作中的被动局面而行动。而是为了解前人们智慧的结晶,人类智力探索的结果,而行动。些许增加一点点生命的厚度,何须题桥柱呢!接下来开始伟大的智力之旅,隐藏在一切程序运行背后的抽象-虚拟内存!
这一个中秋的目的:
1.回顾&总结一下书中虚拟内存部分的内容。
2.完成malloclab
预备知识:
- 我们将heap初始化为一系列块的数组。整个heap由已分配+空闲 两种状态的块组成。
- 我们对块的利用:组织空闲块、放置、分割、合并
- 我们将块组织成链表,并在头&尾添加相同信息(1字32位,3位标识,29位块大小)
- sbrk函数获取额外的堆内存。
构造一个分配器是一件富有挑战的任务,当你完成时,你应该值得为自己感到骄傲!加油!相信你能完成!
块格式、链表格式、放置分割合并的策略均是可以调整的。
在理解了书中的实例及简单的了解了隐式空闲链表、显式空闲链表、分离式空闲链表后,读完lab的writeup,这个实验麻烦的一个点在于其开放性,无论书中的例子还是下发的案例中的例子,均是实现了其基本功能的,而我们要做的是设计一个更优秀的实现方案,意味着实验的目的不再像之前在于程序的正确性,开放性意味着创意,意味着更多的思考,更多的智力投入,我们应该更加兴奋,同时坚决不能参考网上的任何答案。
• Start early! It is possible to write an efficient malloc package with a few pages of code. However, we can guarantee that it will be some of the most difficult and sophisticated code you have written so far in your career. So start early, and good luck!
目的:
实现下列方案,以完成heap的动态分配
int mm_init(void);
void *mm_malloc(size_t size);
void mm_free(void *ptr);
void *mm_realloc(void *ptr, size_t size);
mm_check function
前置:
init方法需要我们明确,如何组织整个heap。
malloc&free 则需要我们明确如何组织与管理这整个heap的分配。
realloc则基于上面两个问题的解答进行处理。
后置:
基于对block的定义,编写check function
书中已经给出了,显示的空闲链表与分离式的空闲链表,显然可以基于这两个方向稍作优化,不过鉴于当前能力与表现,最终还是决定,以书中例子为基本思想实现相关功能。优化? 也许以后会有,也许以后…
1.将heap视为一个巨大的数组,同时在里面添加开始与结尾标记。
2.将块用相同信息的头尾进行包装。
3.遵循8字节对齐
测试结果:
第一版实现后,简单测试,没有trace文件,网上搜索下载即可。
make
./mdriver -f short1-bal.rep -V
输出:
Measuring performance with gettimeofday().
Testing mm malloc
Reading tracefile: short1-bal.rep
便不再有任何消息sad。
排查:
1.利用原始mm.c文件,检查初始化配置是否正确。
./mdriver -f short1-bal.rep -V
结果正常,显然我们的程序有问题…
2.只能debug
#1.objdump -d mdriver > mdriver.s
#2.gdb --args mdriver -f short1-bal.rep -V
直接代码里printf 万事大吉。最终确定问题为:init 时的heap_listp 没有正确初始化。
同时对序言块的理解错误,find_fit 方法,初始化bp错误。造成无限循环。…
result:
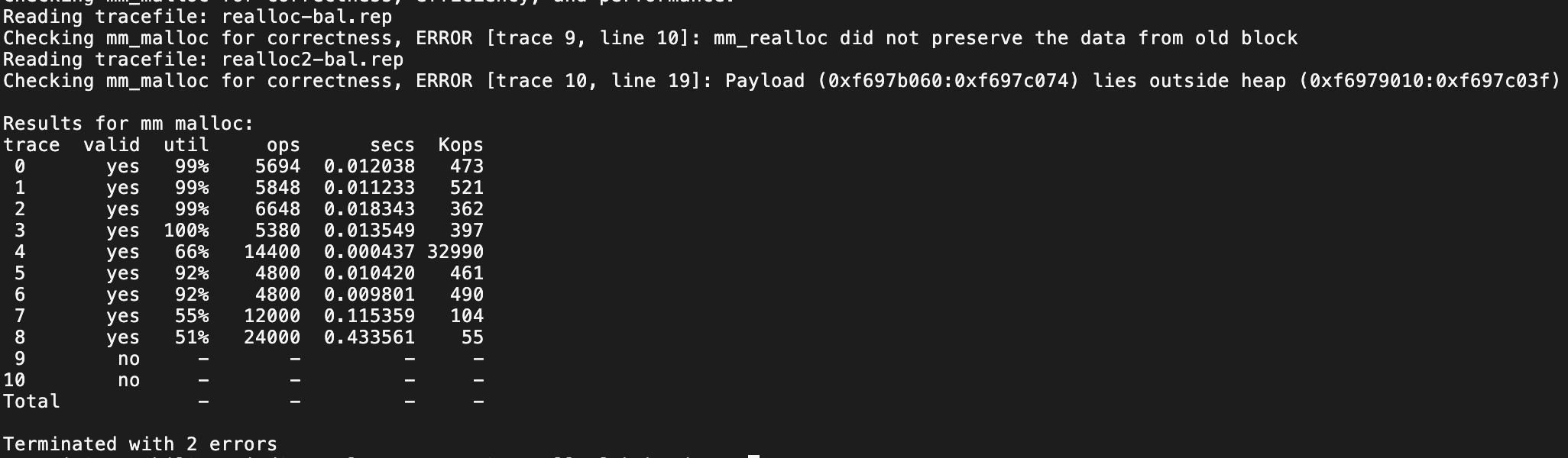
额 , re_malloc 错误…
20240918:很沮丧,我以为我懂了,唯一自己全新设计的方法,mm_realloc 一直报错,或超出界限,或没有正确的保存旧数据。为了不至于进度严重失误,也许要暂缓一下。
Proxy Lab
也许这不是一个很好的开始,毕竟malloc lab 还剩下一点没有完成,志在完美,重在完成!
首先阅读writeup
本次lab中,我们要实现的是一个web的代理服务。
Part1:基本的代理功能
Part2:实现并发功能
Part3:实现缓存功能
在文档描述中,代理似乎很简单,监听端口,建立连接,接受客户端的请求,解析完整的请求,校验请求的有效性,与服务器建立连接,请求服务器,将结果再发送给客户端。
这里我们遇到的第一个问题便是,客户端如何请求代理?将代理放在url,那真正的服务器信息又将放在哪里?按照我们常规的方式请求,则问题又在于如何连接代理? – ai 极大化了效率提升。
简单ai问答后可知:可以在http请求中指定代理的ip与端口。
hints:
1.RIO代替标准IO
2.发生错误时,不应该终止。
3.可以新增/修改任意文件
4.向已关闭的socket写数据会触发SIGPIPE信号,导致进程终止,我们需要处理该信号。EPIPE error
5.ECONNRESET error处理
6.需要注意传输的内容,ascii 与 binary
ok,how to start ?
Part1
服务器监听-解析-请求-返回
详细的逻辑,就不在此处介绍了,没有什么能比代码更直观的了。参考11章的tiny server。
第一版,简直溃不成军,最简单的5个测试全挂了…
测试:
tiny:port = 12714
proxy listen:12716
curl -v --proxy http://localhost:12716 http://localhost:12714/home.html
调试了一晚上,上了sprintf的当了,被覆盖了…
#include <stdio.h>
#include "csapp.h"
/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400
/* You won't lose style points for including this long line in your code */
static const char *user_agent_hdr = "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r
";
//function
void processProxy(int fd);
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg);
void read_requesthdrs(rio_t *rp, char *header_from_origin);
void get_proxy_request(char *port, char *method, char *domain, char *path, rio_t *rp, char *proxy_request);
void parse_url(char *url, char *domain, char *port, char *path);
void proxy_request_server(char *request_content, int ori_client, char *domain, char *port);
void sigpipe_handler(int sig);
<br>
void sigpipe_handler(int sig)
{
printf("sigpipe handled %d
", sig);
return;
}
int main(int argc, char **argv)
{
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
Signal(SIGPIPE, sigpipe_handler);
//获取监听描述符
printf("proxy listen port %s
", argv[1]);
listenfd = Open_listenfd(argv[1]);
while(1) {
clientlen = sizeof(clientaddr);
//获取已连接描述符号
connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen);
Getnameinfo((SA*)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("proxy server accept: (%s, %s)
", hostname, port);
//业务处理 doSomeThing
processProxy(connfd);
//always a good habit
Close(connfd);
}
printf("proxy server shut down!");
return 0;
}
void processProxy(int fd)
{
char buf[MAXLINE], method[MAXLINE], url[MAXLINE], version[MAXLINE];
rio_t rio;
char proxy_request[MAXBUF];
char domain[MAXLINE], port[MAXLINE], path[MAXLINE];
//初始化rio
Rio_readinitb(&rio, fd);
//将fd中的内容,读取一行到buf中
Rio_readlineb(&rio, buf, MAXLINE);
printf("request header:
");
printf("%s", buf);
sscanf(buf,"%s %s %s", method, url, version);
if(strcasecmp(method, "GET")) {
clienterror(fd, method, "501", "Not Implemented","Tiny does not implement this method");
return;
}
//解析url
parse_url(url, domain, port, path);
printf("parse_url result: %s, %s, %s
", domain, port, path);
//重新构建请求
get_proxy_request(port, method, domain, path, &rio, proxy_request);
//发起新的连接,并将结果传送给原始客户端
printf("proxy request header: len = %zu, %s
", strlen(proxy_request), proxy_request);
proxy_request_server(proxy_request, fd, domain, port);
//释放内存
//方法内的变量,创建在stack 无需额外释放。
}
void proxy_request_server(char *request_content, int ori_client, char *domain, char *port)
{
int client_fd;
rio_t rio;
char buf[MAXLINE];
client_fd = Open_clientfd(domain, port);
Rio_readinitb(&rio, client_fd);
//将内容发送给目标服务器
Rio_writen(client_fd, request_content, strlen(request_content));
//将返回结果读取到
size_t sucess = 0;
while ((sucess = Rio_readlineb(&rio, buf, MAXLINE)) != 0 ) {
Rio_writen(ori_client, buf, sucess);
}
//close
Close(client_fd);
}
void parse_url(char *url, char *domain, char *port, char *path)
{
char socket_addr[MAXLINE];
char *domain_start = strstr(url, "://");
if (domain_start) {
domain_start += 3;
char *domain_end = strchr(domain_start, '/');
if (domain_end) {
strncpy(socket_addr, domain_start, domain_end - domain_start);
char *port_start = strchr(socket_addr, ':');
if (port_start) {
strncpy(domain, socket_addr, port_start - socket_addr);
strcpy(port, port_start + 1);
}
domain[port_start - domain_start] = '\0';//添加字符串结尾
strcpy(path, domain_end);
} else {
strcpy(domain, domain_start);
path[0] = '\0';
}
}
}
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg)
{
char buf[MAXLINE];
/* Print the HTTP response headers */
sprintf(buf, "HTTP/1.0 %s %s\r
", errnum, shortmsg);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-type: text/html\r
\r
");
Rio_writen(fd, buf, strlen(buf));
/* Print the HTTP response body */
sprintf(buf, "<html><title>Tiny Error</title>");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "<body bgcolor=""ffffff"">\r
");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "%s: %s\r
", errnum, shortmsg);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "<p>%s: %s\r
", longmsg, cause);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "<hr><em>The Tiny Web server</em>\r
");
Rio_writen(fd, buf, strlen(buf));
}
void get_proxy_request(char *port, char *method, char *domain, char *path, rio_t *rp, char *proxy_request)
{
//首行
sprintf(proxy_request, "%s %s %s\r
", method, path, "HTTP/1.0");
printf("get_proxy_request frist line = %s
", proxy_request);
//固定头
sprintf(proxy_request + strlen(proxy_request), "Host: %s:%s\r
", domain, port);
sprintf(proxy_request + strlen(proxy_request), "%s", "Connection: close\r
");
sprintf(proxy_request + strlen(proxy_request), "%s", "Proxy-Connection: close\r
");
sprintf(proxy_request + strlen(proxy_request), "%s", user_agent_hdr);
//原请求中需要带去服务器中的部分
read_requesthdrs(rp, proxy_request);
//结束符
sprintf(proxy_request + strlen(proxy_request), "\r
");
}
void read_requesthdrs(rio_t *rp, char *header_from_origin)
{
char buf[MAXLINE];
char head[MAXLINE];
char content[MAXLINE];
Rio_readlineb(rp, buf, MAXLINE);
while(strcmp(buf, "\r
")) {
sscanf(buf,"%s: %s", head, content);
if (strcmp(head, "Host:") == 0) {
Rio_readlineb(rp, buf, MAXLINE);
continue;
}
if (strcmp(head, "User-Agent:") == 0) {
Rio_readlineb(rp, buf, MAXLINE);
continue;
}
if (strcmp(head, "Connection:") == 0) {
Rio_readlineb(rp, buf, MAXLINE);
continue;
}
if (strcmp(head, "Proxy-Connection:") == 0) {
Rio_readlineb(rp, buf, MAXLINE);
continue;
}
sprintf(header_from_origin + strlen(header_from_origin), "%s", buf);
Rio_readlineb(rp, buf, MAXLINE);
}
}
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include "csapp.h"
/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400
#define MAX_CACHE 10
/* You won't lose style points for including this long line in your code */
static const char *user_agent_hdr = "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r
";
/*关于读写者锁的结构体*/
struct rwlock_t{
sem_t lock; //基本锁
sem_t writelock; //写者所
int readers; //读者个数
};
/*关于近似LRU缓存的结构体*/
struct Cache{
int used; //最近被使用过则为 1,否则为 0
char key[MAXLINE]; //URL索引
char value[MAX_OBJECT_SIZE]; //URL所对应的缓存
};
/*关于url信息的结构体*/
struct UrlData{
char host[MAXLINE]; //hostname
char port[MAXLINE]; //端口
char path[MAXLINE]; //路径
};
struct Cache cache[MAX_CACHE]; //定义缓存对象,最多允许存在MAX_CACHE个
struct rwlock_t* rw; //定义读写者锁指针
int nowpointer; //LRU当前指针
void doit(int fd);
void parse_url(char* url, struct UrlData* u); //解析URL
void change_httpdata(rio_t* rio, struct UrlData* u, char* new_httpdata); //修改http数据
void thread(void* v); //线程函数
void rwlock_init(); //初始化读写者锁指针
int readcache(int fd, char* key); //读缓存
void writecache(char* buf, char* key); //写缓存
/*main函数大体与书上一致*/
int main(int argc, char** argv){
rw = Malloc(sizeof(struct rwlock_t));
printf("%s", user_agent_hdr);
pthread_t tid;
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
rwlock_init();
if (argc != 2){
fprintf(stderr, "usage: %s <port>
", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]);
while (1){
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen);
Getnameinfo((SA*)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s %s)
", hostname, port);
doit(connfd);
}
return 0;
}
void rwlock_init(){
rw->readers = 0; //没有读者
sem_init(&rw->lock, 0, 1);
sem_init(&rw->writelock, 0, 1);
}
void thread(void* v){
int fd = *(int*)v; //这一步是必要的,v是main中connfd的地址,后续可能被改变,所以必须要得到一个副本
//还要注意不能锁住,因为允许多个一起读
Pthread_detach(pthread_self()); //设置线程,结束后自动释放资源
doit(fd);
close(fd);
}
void doit(int fd){
char buf[MAXLINE], method[MAXLINE], url[MAXLINE], version[MAXLINE];
char new_httpdata[MAXLINE], urltemp[MAXLINE];
struct UrlData u;
rio_t rio, server_rio;
Rio_readinitb(&rio, fd);
Rio_readlineb(&rio, buf, MAXLINE);
sscanf(buf, "%s %s %s", method, url, version);
strcpy(urltemp, url); //赋值url副本以供读者写者使用,因为在解析url中,url可能改变
/*只接受GEI请求*/
if (strcmp(method, "GET") != 0){
printf ("The proxy can not handle this method: %s
", method);
return;
}
// if (readcache(fd, urltemp) != 0) //如果读者读取缓存成功的话,直接返回
// return;
parse_url(url, &u); //解析url
change_httpdata(&rio, &u, new_httpdata); //修改http数据,存入 new_httpdata中
int server_fd = Open_clientfd(u.host, u.port);
size_t n;
Rio_readinitb(&server_rio, server_fd);
Rio_writen(server_fd, new_httpdata, strlen(new_httpdata));
int sum = 0;
while((n = Rio_readlineb(&server_rio, buf, MAXLINE)) != 0){
Rio_writen(fd, buf, n);
}
close(server_fd);
return;
}
void writecache(char* buf, char* key){
sem_wait(&rw->writelock); //需要等待获得写者锁
int index;
/*利用时钟算法,当前指针依次增加,寻找used字段为0的对象*/
/*如果当前used为1,则设置为0,最坏情况下需要O(N)时间复杂度*/
while (cache[nowpointer].used != 0){
cache[nowpointer].used = 0;
nowpointer = (nowpointer + 1) % MAX_CACHE;
}
index = nowpointer;
cache[index].used = 1;
strcpy(cache[index].key, key);
strcpy(cache[index].value, buf);
sem_post(&rw->writelock); //释放锁
return;
}
int readcache(int fd, char* url){
sem_wait(&rw->lock); //读者等待并获取锁(因为要修改全局变量,可能是线程不安全的,所以要锁)
if (rw->readers == 0) //如果没有读者的话,说明可能有写者在写,必须等待并获取写者锁
sem_wait(&rw->writelock); //读者再读时,不允许有写着
rw->readers++;
sem_post(&rw->lock); //全局变量修改完毕,接下来不会进入临界区,释放锁给更多读者使用
int i, flag = 0;
/*依次遍历找到缓存,成功则设置返回值为 1*/
for (i = 0; i < MAX_CACHE; i++){
//printf ("Yes! %d
",cache[i].usecnt);
if (strcmp(url, cache[i].key) == 0){
Rio_writen(fd, cache[i].value, strlen(cache[i].value));
printf("proxy send %d bytes to client
", strlen(cache[i].value));
cache[i].used = 1;
flag = 1;
break;
}
}
sem_wait(&rw->lock); /*进入临界区,等待并获得锁*/
rw->readers--;
if (rw->readers == 0) /*如果没有读者了,释放写者锁*/
sem_post(&rw->writelock);
sem_post(&rw->lock); /*释放锁*/
return flag;
}
/*解析url,解析为host, port, path*/
/*可能的情况:
url: /home.html 这是目前大部分的形式,仅由路径构成,而host在Host首部字段中,端口默认80
url: http://www.xy.com:8080/home.html 这种情况下,Host首部字段为空,我们需要解析域名:www.xy.com,端口:8080,路径:/home.html*/
//该函数没有考虑参数等其他复杂情况
void parse_url(char* url, struct UrlData* u){
char* hostpose = strstr(url, "//");
if (hostpose == NULL){
char* pathpose = strstr(url, "/");
if (pathpose != NULL)
strcpy(u->path, pathpose);
strcpy(u->port, "80");
return;
} else{
char* portpose = strstr(hostpose + 2, ":");
if (portpose != NULL){
int tmp;
sscanf(portpose + 1, "%d%s", &tmp, u->path);
sprintf(u->port, "%d", tmp);
*portpose = '\0';
} else{
char* pathpose = strstr(hostpose + 2, "/");
if (pathpose != NULL){
strcpy(u->path, pathpose);
strcpy(u->port, "80");
*pathpose = '\0';
}
}
strcpy(u->host, hostpose + 2);
}
return;
}
void change_httpdata(rio_t* rio, struct UrlData* u, char* new_httpdata){
static const char* Con_hdr = "Connection: close\r
";
static const char* Pcon_hdr = "Proxy-Connection: close\r
";
char buf[MAXLINE];
char Reqline[MAXLINE], Host_hdr[MAXLINE], Cdata[MAXLINE];//分别为请求行,Host首部字段,和其他不东的数据信息
sprintf(Reqline, "GET %s HTTP/1.0\r
", u->path); //获取请求行
while (Rio_readlineb(rio, buf, MAXLINE) > 0){
/*读到空行就算结束,GET请求没有实体体*/
if (strcmp(buf, "\r
") == 0){
strcat(Cdata, "\r
");
break;
}
else if (strncasecmp(buf, "Host:", 5) == 0){
strcpy(Host_hdr, buf);
}
else if (!strncasecmp(buf, "Connection:", 11) && !strncasecmp(buf, "Proxy_Connection:", 17) &&!strncasecmp(buf, "User-agent:", 11)){
strcat(Cdata, buf);
}
}
if (!strlen(Host_hdr)){
/*如果Host_hdr为空,说明该host被加载进请求行的URL中,我们格式读从URL中解析的host*/
sprintf(Host_hdr, "Host: %s\r
", u->host);
}
sprintf(new_httpdata, "%s%s%s%s%s%s", Reqline, Host_hdr, Con_hdr, Pcon_hdr, user_agent_hdr, Cdata);
return;
}
#include <stdio.h>
#include "csapp.h"
/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400
/* You won't lose style points for including this long line in your code */
static const char *user_agent_hdr = "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r
";
struct UrlData{
char host[MAXLINE]; //hostname
char port[MAXLINE]; //端口
char path[MAXLINE]; //路径
};
//function
void processProxy(int fd);
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg);
void read_requesthdrs(rio_t *rp, char *header_from_origin);
void get_proxy_request(char *method, char *domain, char *path, rio_t *rp, char *proxy_request);
void parse_url(char *url, char *domain, char *port, char *path);
void proxy_request_server(char *request_content, int ori_client, char *domain, char *port);
void sigpipe_handler(int sig);
void change_httpdata(rio_t* rio, struct UrlData* u, char* new_httpdata);
void parse_url_o(char* url, struct UrlData* u);
void sigpipe_handler(int sig)
{
printf("sigpipe handled %d
", sig);
return;
}
int main(int argc, char **argv)
{
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
Signal(SIGPIPE, sigpipe_handler);
//获取监听描述符
printf("proxy listen port %s
", argv[1]);
listenfd = Open_listenfd(argv[1]);
while(1) {
clientlen = sizeof(clientaddr);
//获取已连接描述符号
connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen);
Getnameinfo((SA*)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("proxy server accept: (%s, %s)
", hostname, port);
//业务处理 doSomeThing
processProxy(connfd);
//always a good habit
Close(connfd);
}
printf("proxy server shut down!");
return 0;
}
void processProxy(int fd)
{
char buf[MAXLINE], method[MAXLINE], url[MAXLINE], version[MAXLINE];
rio_t rio;
char proxy_request[MAXBUF], new_httpdata[MAXLINE];
char domain[MAXLINE], port[MAXLINE], path[MAXLINE];
struct UrlData u;
//初始化rio
Rio_readinitb(&rio, fd);
//将fd中的内容,读取一行到buf中
Rio_readlineb(&rio, buf, MAXLINE);
printf("request header:
");
printf("%s", buf);
sscanf(buf,"%s %s %s", method, url, version);
if(strcasecmp(method, "GET")) {
clienterror(fd, method, "501", "Not Implemented","Tiny does not implement this method");
return;
}
//解析url
//parse_url(url, domain, port, path);
//printf("parse_url result: %s, %s, %s
", domain, port, path);
parse_url_o(url, &u);
//重新构建请求
//get_proxy_request(method, domain, path, &rio, proxy_request);
change_httpdata(&rio, &u, new_httpdata);
//发起新的连接,并将结果传送给原始客户端
printf("proxy request header: len = %zu, %s
", strlen(new_httpdata), new_httpdata);
proxy_request_server(new_httpdata, fd, u.host, u.port);
//释放内存
//方法内的变量,创建在stack 无需额外释放。
}
void proxy_request_server(char *request_content, int ori_client, char *domain, char *port)
{
rio_t server_rio;
char buf[MAXLINE];
int server_fd = Open_clientfd(domain, port);
size_t n;
Rio_readinitb(&server_rio, server_fd);
Rio_writen(server_fd, request_content, strlen(request_content));
int sum = 0;
while((n = Rio_readlineb(&server_rio, buf, MAXLINE)) != 0){
Rio_writen(ori_client, buf, n);
}
//close
Close(server_fd);
}
void parse_url(char *url, char *domain, char *port, char *path)
{
char socket_addr[MAXLINE];
char *domain_start = strstr(url, "://");
if (domain_start) {
domain_start += 3;
char *domain_end = strchr(domain_start, '/');
if (domain_end) {
strncpy(socket_addr, domain_start, domain_end - domain_start);
char *port_start = strchr(socket_addr, ':');
if (port_start) {
strncpy(domain, socket_addr, port_start - socket_addr);
strcpy(port, port_start + 1);
}
domain[port_start - domain_start] = '\0';//添加字符串结尾
strcpy(path, domain_end);
} else {
strcpy(domain, domain_start);
path[0] = '\0';
}
}
}
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg)
{
char buf[MAXLINE];
/* Print the HTTP response headers */
sprintf(buf, "HTTP/1.0 %s %s\r
", errnum, shortmsg);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-type: text/html\r
\r
");
Rio_writen(fd, buf, strlen(buf));
/* Print the HTTP response body */
sprintf(buf, "<html><title>Tiny Error</title>");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "<body bgcolor=""ffffff"">\r
");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "%s: %s\r
", errnum, shortmsg);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "<p>%s: %s\r
", longmsg, cause);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "<hr><em>The Tiny Web server</em>\r
");
Rio_writen(fd, buf, strlen(buf));
}
void get_proxy_request(char *method, char *domain, char *path, rio_t *rp, char *proxy_request)
{
//首行
sprintf(proxy_request, "%s %s %s\r
", method, path, "HTTP/1.0");
printf("get_proxy_request frist line = %s
", proxy_request);
//固定头
sprintf(proxy_request + strlen(proxy_request), "Host: %s\r
", domain);
sprintf(proxy_request + strlen(proxy_request), "User-Agent: %s\r
", user_agent_hdr);
sprintf(proxy_request + strlen(proxy_request), "Connection: close\r
");
sprintf(proxy_request + strlen(proxy_request), "Proxy-Connection: close\r
");
//原请求中需要带去服务器中的部分
read_requesthdrs(rp, proxy_request);
//结束符
sprintf(proxy_request + strlen(proxy_request), "\r
");
}
void read_requesthdrs(rio_t *rp, char *header_from_origin)
{
char buf[MAXLINE];
char head[MAXLINE];
char content[MAXLINE];
Rio_readlineb(rp, buf, MAXLINE);
while(strcmp(buf, "\r
")) {
sscanf(buf,"%s: %s", head, content);
if (strcmp(head, "Host") == 0) {
continue;
}
if (strcmp(head, "User-Agent") == 0) {
continue;
}
if (strcmp(head, "Connection") == 0) {
continue;
}
if (strcmp(head, "Proxy-Connection") == 0) {
continue;
}
sprintf(header_from_origin + strlen(header_from_origin), "%s", buf);
Rio_readlineb(rp, buf, MAXLINE);
}
}
void change_httpdata(rio_t* rio, struct UrlData* u, char* new_httpdata){
static const char* Con_hdr = "Connection: close\r
";
static const char* Pcon_hdr = "Proxy-Connection: close\r
";
char buf[MAXLINE];
char Reqline[MAXLINE], Host_hdr[MAXLINE], Cdata[MAXLINE];//分别为请求行,Host首部字段,和其他不东的数据信息
sprintf(Reqline, "GET %s HTTP/1.0\r
", u->path); //获取请求行
while (Rio_readlineb(rio, buf, MAXLINE) > 0){
/*读到空行就算结束,GET请求没有实体体*/
if (strcmp(buf, "\r
") == 0){
strcat(Cdata, "\r
");
break;
}
else if (strncasecmp(buf, "Host:", 5) == 0){
strcpy(Host_hdr, buf);
}
else if (!strncasecmp(buf, "Connection:", 11) && !strncasecmp(buf, "Proxy_Connection:", 17) &&!strncasecmp(buf, "User-agent:", 11)){
strcat(Cdata, buf);
}
}
if (!strlen(Host_hdr)){
/*如果Host_hdr为空,说明该host被加载进请求行的URL中,我们格式读从URL中解析的host*/
sprintf(Host_hdr, "Host: %s\r
", u->host);
}
sprintf(new_httpdata, "%s%s%s%s%s%s", Reqline, Host_hdr, Con_hdr, Pcon_hdr, user_agent_hdr, Cdata);
return;
}
void parse_url_o(char* url, struct UrlData* u){
char* hostpose = strstr(url, "//");
if (hostpose == NULL){
char* pathpose = strstr(url, "/");
if (pathpose != NULL)
strcpy(u->path, pathpose);
strcpy(u->port, "80");
return;
} else{
char* portpose = strstr(hostpose + 2, ":");
if (portpose != NULL){
int tmp;
sscanf(portpose + 1, "%d%s", &tmp, u->path);
sprintf(u->port, "%d", tmp);
*portpose = '\0';
} else{
char* pathpose = strstr(hostpose + 2, "/");
if (pathpose != NULL){
strcpy(u->path, pathpose);
strcpy(u->port, "80");
*pathpose = '\0';
}
}
strcpy(u->host, hostpose + 2);
}
return;
}