程序结构和执行
Hello.c 的一生
#include <stdio.h>
int main()
{
printf("hello, world
");
return 0;
}
hello.c ascii 码组成的文本文件,01构成的一串比特
从源文件到目标可执行文件:编译器驱动程序
有四个阶段,共同构成了编译系统
- 预处理器:处理宏等
- 编译器:编译成汇编代码
- 汇编器:汇编转变为二进制目标文件
- 链接器:解析符号/重定位 变成可执行文件
系统硬件简单组成
- 总线:字(32位机器 4个字节,64位8个字节)为单位,在各个部件之间传递信息
- I/O:io设备通过控制器/适配器与io总线连接
- 主存:临时存储设备DRAM,线性的字节数组。
- 处理器:CPU
- 大小为一个字的寄存器,程序计数器
- 寄存器
- ALU
- cpu:加载、存储、操作、跳转
在人体发育的第三周开始出现心肌细胞,第四周开始形成心脏,此后直至生命的终结她将一直不停的跳动。从系统通电开始,cpu将会一直执行pc指向的指令,并更新pc指向,直至系统断电。
运行简述:
1.键盘(./hello):键盘-寄存器-内存
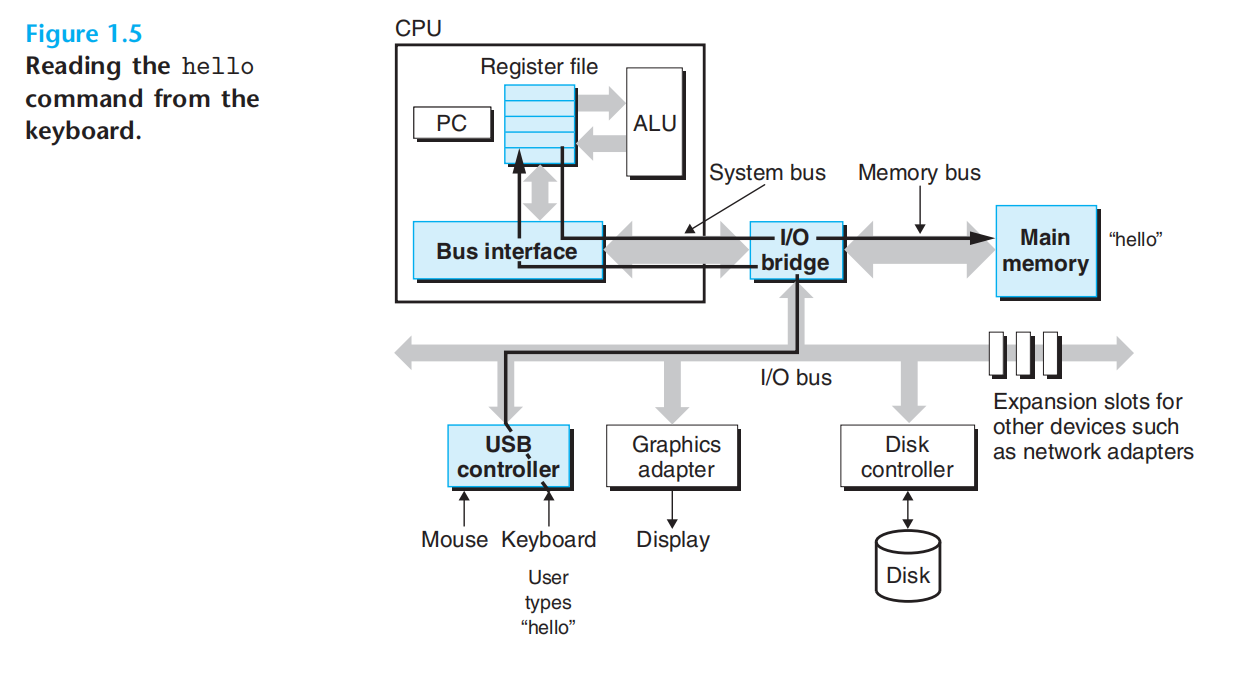
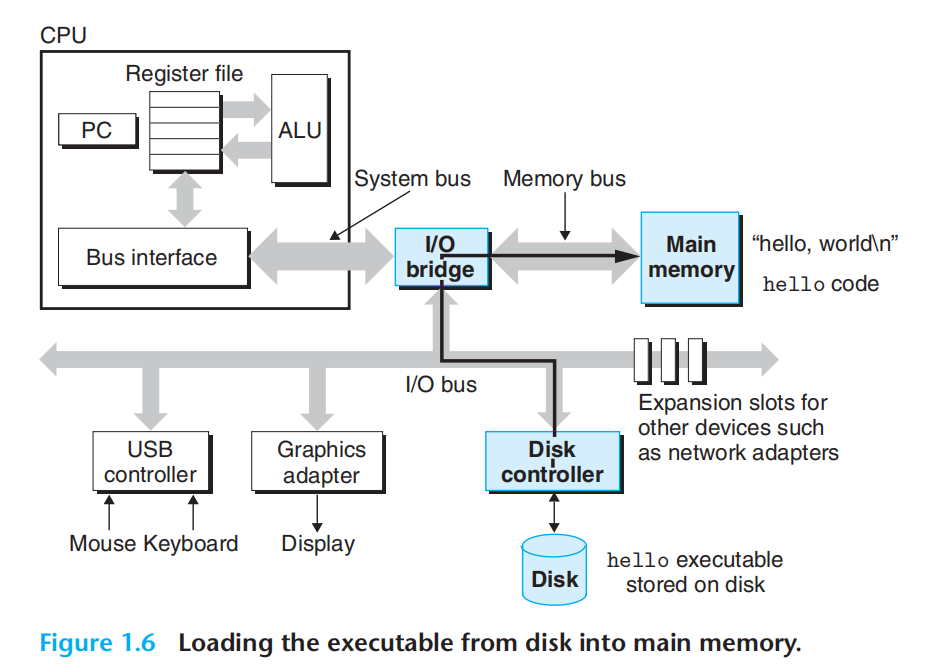
2.回车,代码文本:磁盘-内存(下图):
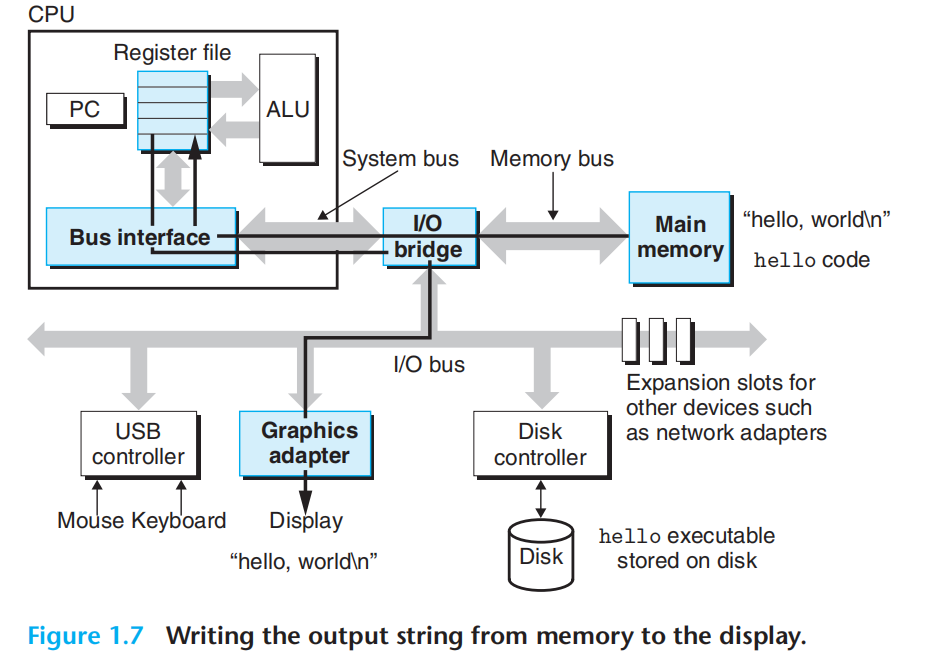
3.开始执行机器指令:内存-寄存器-显示设备
为了平衡容量与速度,在内存与寄存器之间,又引入了高速缓存(cache,L1,L2,L3)。
在处理器与较大较慢的存储设备之间,插入更小更快的存储设备,构成了存储器层次结构:
common:
- L0 寄存器
- L1
- L2
- L3
- L4 主存
- L5 磁盘
- L6 文件服务器
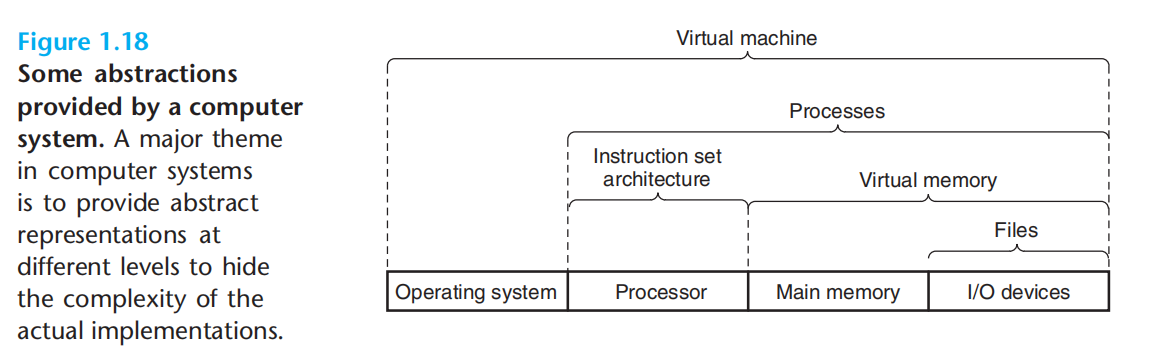
操作系统管理硬件:
程序运行时,并不会直接访问硬件,而是依靠操作系统提供的服务。操作系统是应用程序和硬件之间插入的一层软件。
- 防止硬件被失控的软件滥用
- 提供统一的机制来控制繁杂的硬件
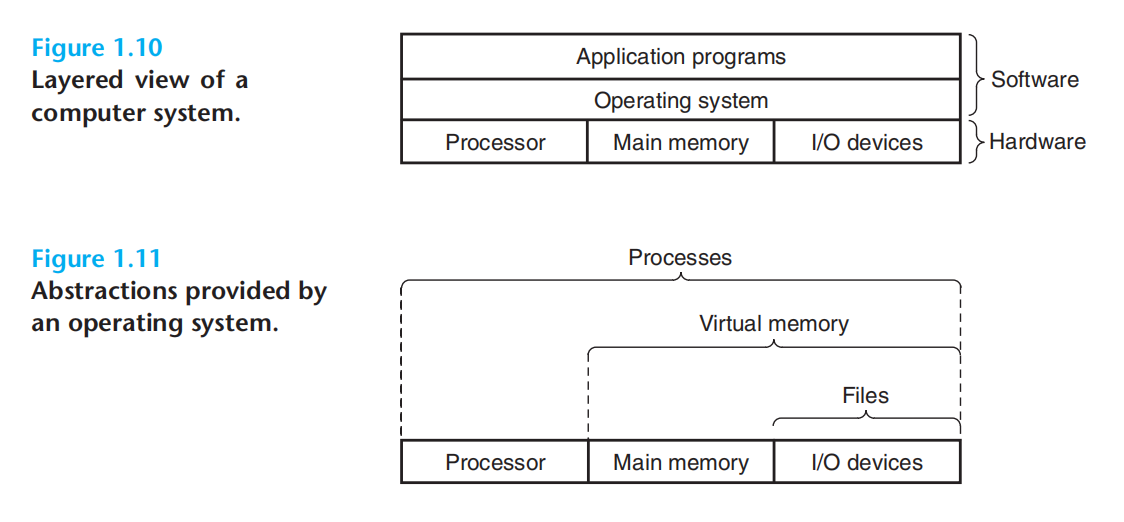
上述基本功能的实现则来自于:进程、虚拟内存、文件
文件:io设备的抽象
虚拟内存:主存&io设备的抽象
进程:处理器&主存&io设备的抽象
进程:该抽象,提供的假象:好像程序独占地使用 主存、处理器、io设备。是计算机科学中最重要,最成功的概念之一(很遗憾,与之并行的其他概念并不能简单搜索得到…)。是操作系统对正在运行的程序的一种抽象。
上下文切换:让一个cpu看上去在并发的执行多个进程
上下文:进程运行所需要的所有状态信息
内核kernel:应用程序需要操作系统某些操作时,执行特殊的系统调用(system call)指令,将控制权交给内 核,内核执行操作,并返回应用程序。内核不是一个独立的进程 Instead, it is a collection of code and data structures that the system uses to manage all the processes. 操作系统常驻主存的部分。
线程:运行在进程的上下文中,共享同样的代码和全局数据结构
虚拟内存:该抽象,提供的假象:每个进程都在独占的使用主存。
虚拟地址空间: Each process has the same uniform view of memory, which is known as its virtual address space
文件:字节序列,仅此而已。
amdahl定律
1/(1-a)+ a/k
并发&并行
do more & run faster
并发:通用概念,a system with multiple, simultaneous activities
并行:the use of concurrency to make a system run faster
线程级并发:
多核处理器:多个cpu集成到一个集成芯片,共享主存。
超线程(同时多线程):cpu某些硬件有多个备份(例如,多个程序计数器,多个寄存器),允许一个cpu执行多个控制流。
指令级并行:
指令级并行:同时执行多条指令。
超标量处理器:达到比一个周期一条指令更快的执行速率。
单指令,多数据并行:
特殊硬件,允许一条指令产生多个并行执行的操作。
信息的表示与处理
如前面所言,计算机系统中我们所有的信息载体,都是比特序列。比特序列需要依赖上下文才能具有意义。人类社会中信息的载体之一则是语言文字,在诸多纷繁复杂的格式中本章主要探讨,比特序列到文字之间的映射。主要是到字符与数字之间的映射。
单个的位,通常没有太多的含义,将位组合起来,加上某种解释,通常能表示有限集合中的任意元素。
引子 神奇数字:-884901888
#include <stdio.h>
int main(void)
{
int a = 200*300*400*500;
printf("%d",a); //-884901888
printf("%f
",((3.14 + 1e20) - 1e20)); //0.000000
printf("%f",(3.14 +(1e20 - 1e20)));//3.140000
return 0;
}
计算机没有产生期望的结果,至少她是一致的 😂
无符号
补码
浮点数
编码定义 - 表示范围 、位级表示、算术运算
java语言的数字表示与运算标准 与 c语言有不同:
todo:
信息存储
机器级程序(程序的机器码级别,一系列的字节序列):
指令集体系结构:后面再说
虚拟内存:将内存视为巨大的字节数组,每个字节都有唯一的数字(地址)标识
虚拟地址空间:所有可能地址的集合
编译器和运行时系统,如何将程序划分为可管理的单元?来存放不同的程序对象(程序数据(变量、指针、数组、函数、类、结构体….)、指令、控制信息)
c的指针(类型 & 值)有类型,但在机器级程序里面,不包含数据类型信息,每个程序对象视为一个字节块。
字长(word size):限定了虚拟地址的范围,32位机器,虚拟地址空间约为4GB,64位机器,虚拟地址空间约为16EB。指针数据的nominal size。
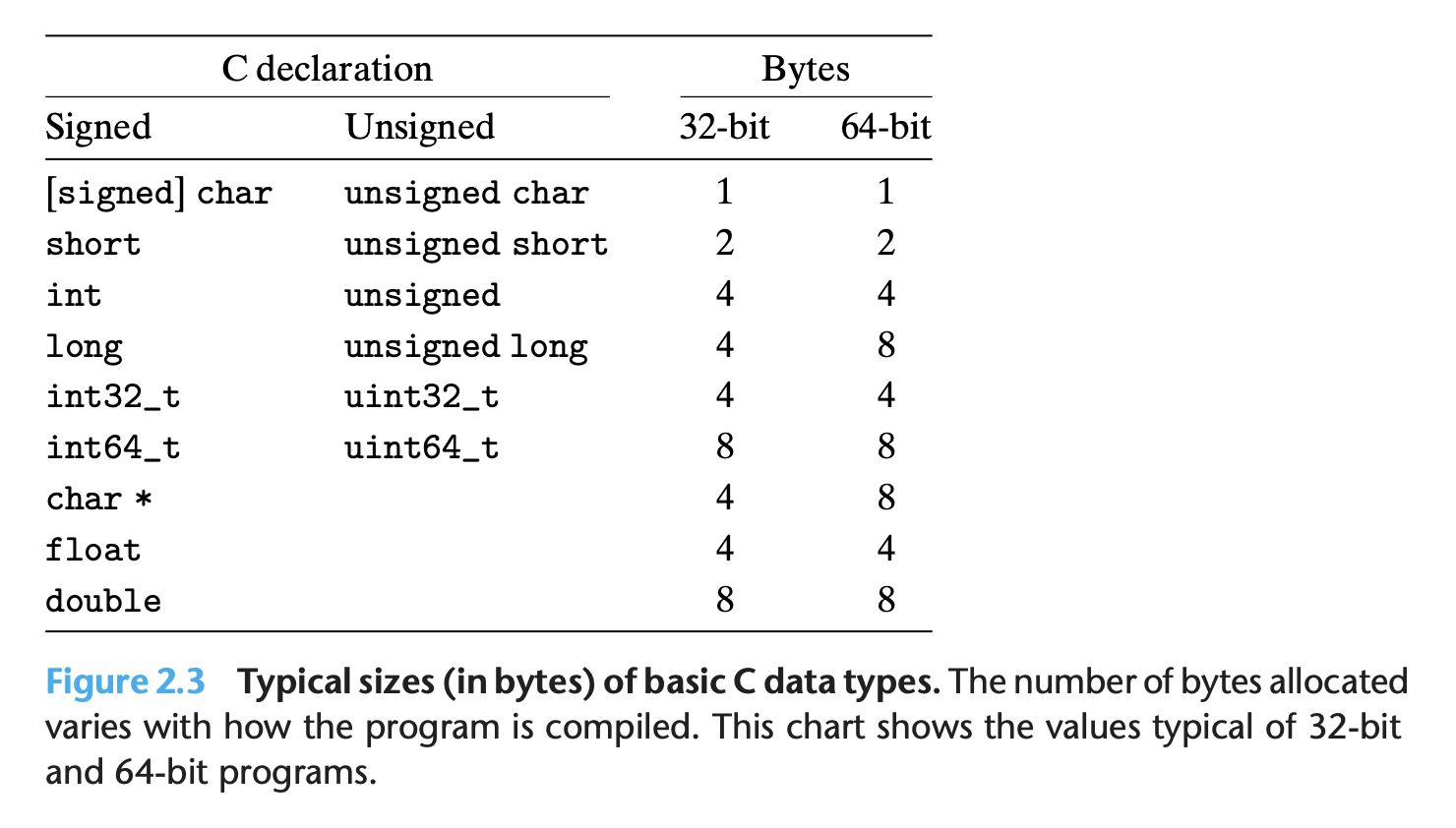
c语言类型在不同机器上占用的位数不一致。
32位机器上,int类型的程序对象可以被用来存储指针,64位则不行
寻址与字节顺序:
对象的地址是什么?
多字节对象被存储为连续的字节序列,所使用字节最小的那个字节地址就是对象地址。
在内存中如何排列这些字节?
小端法:最低有效字节在前面,(0x1234567,67在前12最后)一个字节8位,可以表示两个16进制数字
大端法:最高有效字节在前面
无所谓优劣,不过当大端法表示的机器将数据传递给小端法表示的机器时需要建立统一的网络标准。
上面介绍了一些基本类型在机器码中的二进制表示
字符串的表示:
c语言中字符串是char数组末尾跟上null(0x00)
而char的表示则又与编码集有关
代码的表示:
不同的机器与操作系统组合,二进制代码的表示是不一样的。
布尔代数:
二进制中如何处理布尔逻辑运算:非、与、或、异或
位向量(长度为w由0&1组成的串),可以表示有限集合
c语言中的位运算:
//没有任何性能优势
void inplace_swap(int *x, int *y){
*y = *x ^ *y;
*x = *x ^ *y;
*y = *x ^ *y;
}
掩码运算:
从字中选出指定的位
逻辑运算:
!、||、&& 规则同布尔,只不过入参与出参只有true or false
移位运算:
左移:低位补0
右移:
逻辑右移:高位补0(无符号)
算术右移:高位补原数据最高位(有符号)
java中:x»k(算术右移) x»>k(逻辑右移)
为了防止过量位移,一般要mod 计算k
整数的表示
c中,无符号/有符号,各种类型的长度
java中,各类型数据范围是非常明确的
c中char 一个字节,java中char 2个字节
无符号数的表示:
双射函数
有符号数的表示:
补码
除了补码表示还可以:
反码:最高有效位 表示:-(2的w-1次方 - 1),其余与补码相同。
原码:最高有效位是符号位
目前机器普遍采用补码。
有符号与无符号之间的转换
强制类型转换的结果就是将 二进制 以另一种方式去解释。位模式不变,数值可能会变。
有转无:负数:+2的w次方,-1 + 16 = 15
因为:补码中,我们最高位解释为负数,1000解释为-8+0,而无符号数中应该解释为8+0,转换意味我们需要将-8处理为8,高位右移一位。
无转有:大于2的w-1 次方的值:9 - 16 = -7
一个负数的有符号会变成较大的无符号,隐式转换需要特别小心。c默认有符号转为无符号。
将一个数字变成一个更大的类型
无符号:直接前面加0,零拓展
有符号:符号拓展,添加最高有效位的值
注意:大小转换 再叠加 有符号/无符号 转换,相对顺序也会影响一个值。
short x = -12345;
unsigned y = x;
// (unsigned) (int) x
//而不是(unsigned) (unsigned short) x
截断
无符号:
剔除高位:x’ = x mod 2^k
有符号(补码):
将剔除高位的结果,再转变为补码形式
无符号数的一个特别的用处在于将将其当作没有数学意义的位向量。
整数运算
x<y & x - y < 0 = false 及 正数相加得到负数。
无符号加法
发生溢出时,去掉高位。
检测:sum < x | sum < y
阿贝尔群,加法逆元
补码加法
砍掉高位,再把结果当作补码去解释
检测:正数相加便成负数 | 负数相加变成正数
011+011= 110
补码
110+110=1100=100right,要溢出必须 101+101=1010=010 wrong
无符号乘法
乘完后丢掉超出的位:(x*y)mod 2^w
补码乘法:
当作无符号,乘积截断为w位,再转换为补码
乘以整数
12 = 2^3+2^2
x*12 = (x«3)+(x«2)
除以2的幂
无符号:直接右移,向下取整(3.14=3,-3.14=-4)。
有符号: 负数 (x + (1 « k) -1 ) » k
浮点数的表示
十进制小数,二进制小数。
IEEE浮点数:【SEM】
(-1)^a * M *2^E
a:正负数
E:阶
M:二进制小数
正规:E != 全0 & E != 全1;E取值:二进制-bais,M取值:1+二进制
非正规:E全0;E = 1 -bais;M取值:二进制
无穷:E全1,M全0
NaN:E全1,M非全0
全0表示0;
32位单精度:
64位双精度:
编码:隐匿在计算机背后的语言
《继电器和开关电路的符号分析》
《通信的数学原理》
香农信息论
程序的机器级表示
我们拥有的是一串二进制比特序列,通过上下文,将其进行转换,边具有了具体的意义。上一章便讲了信息的表示。本章主要讲述,将源文件转换为二进制目标文件后,物理机器如何进行具体的动作,以将代码中蕴含的意义实现。
汇编-简介
#gcc 完整编译
gcc -Og -o pog p1.c p2.c
p1.c & p2.c [stpe1编译器转汇编] p1.s & p2.s [step2汇编器转二进制目标代码] p1.o & p2.o [step3 链接器] 最终可执行文件
目标代码(二进制): 目标代码是机器代码的一种形式,包含了所有指令的二进制表示,但没有填入全局值的地址。
整个计算机系统中处处充满了:使用不同形式的抽象,利用更简单的抽象模型来隐藏具体的实现细节。
对于机器级编程而言:
- 指令集架构(instruction set architecture ISA):defining the processor state, the format of the instructions, and the effect each of these instructions will have on the state。(状态机)
- 虚拟地址(virtual addresses):providing a memory model that appears to be a very large byte array
- 机器代码与c代码差别比较大,一些对c程序隐藏的处理器状态都是可见的:
- 程序计数器(program counter PC):indicates the address in memory of the next instruction to be executed
- 整数寄存器文件(integer register file):contains 16 named locations storing 64-bit values。可以存储地址(指针)/数据,常被用来保存,参数/局部变量/返回值等
- 条件寄存器(condition code registers):hold status information about the most recently executed arithmetic or logical instruction;These are used to implement conditional changes in the control or data flow, such as is required to implement if and while statements
- 一组 向量寄存器(vector registers):can each hold one or more integer or floating-point values.
向量寄存器与整数寄存器的区别?
机器代码,将内存看作一个很大的,按照字节寻址的数组。不区分有符号整数与无符号整数,不区分指针的类型,甚至不区分指针与整数。
程序内存包含:
- 可执行的机器代码
- 操作系统需要的一些信息
- 用来管理过程调用与返回的运行时stack
- 用户分配的内存块
#-S 编译成汇编代码,mstore.s
gcc -Og -S mstore.c
#编译并汇编该代码,mstore.o 此时未链接
#机器执行的程序只是一个字节序列,可以分成若干组,每一组都对应一条指令
gcc -Og -c mstore.c
#输出一个完整的可执行文件:不仅生成代码,还对目标文件运行了链接器
gcc -Og -o prog main.c mstore.c
#反汇编
objdump -d mstore.o
汇编-数据格式
汇编-访问信息
操作数
可以理解为求值
三类:
- 立即数 $0x123
- 寄存器
- 内存引用
整数寄存器:

那一个是存放下一条指令的? :
操作符
1.数据传送
mov
0拓展
符号拓展
bbalabal…
push&pop
pushq %rbp = subq $8,%rsp + movq %rbp,(%rsp)
popq %rax = movq (%rsp),%rax + addq $8,%rsp
2.算术与逻辑操作
加载有效地址
lea (load effective address):类似 mov 但是mov是将内存地址对应的值移动到寄存器,lea则是将地址移动到寄存器,即并不读取地址对应的值。由此演化出了许多灵活的用法。
一元操作
二元操作
移位操作
特殊算术操作
128 位乘法,如果操作数不满足128位,特殊指令(cqto)补0
整数除法,除法如果为64位则rdx 需要填充:0/符号位
3.控制
机器代码,提供两种基本的低级机制来实现条件行为:
测试数据值,根据测试结果:
- 改变控制流
- 改变数据流
条件码寄存器
出了前面提到的整数寄存器,还有条件码寄存器
算术与逻辑操作都会设置条件码

除了算术&逻辑操作会附带设置条件码;CMP & TEST,则只设置条件码,不改变任何其他寄存器。cmp 类似sub,test类似 and。
条件码一般不会直接访问:
- 根据条件码的组合,将字节设置为0/1
- 有条件跳转到程序的其他部分
- 有条件的传送数据
针对第一点:SET 指令。

在机器代码级别,没有数据类型一说,而c语言是有明确数据类型的,机器代码实现数据类型主要是依靠具体的指令(有无符号 & 位数,例如:32位有符号 = int)
jump
jmp .L1,汇编器编译成目标代码时会修改为 jump 0x12345678 :直接跳转
jump *%rax / jmp *(%rax),跳转到rax中的值指示的代码/rax中对应的内存上的值对应的代码:间接跳转
todo:汇编器生成目标代码的时候就会填充具体的地址?链接时还会再修改地址? jmp Lable。
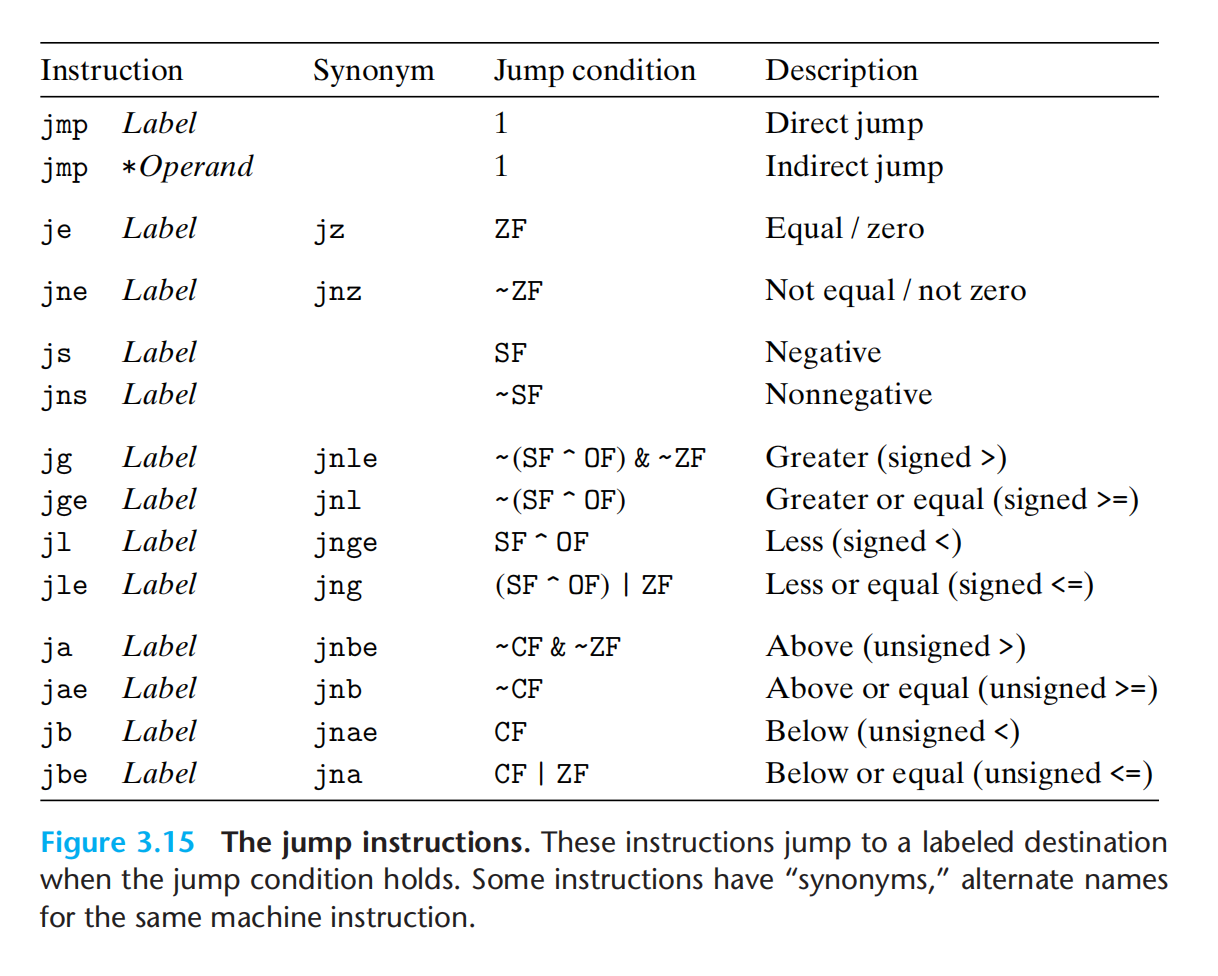
跳转指令有几种不同的编码方式:
- 相对地址(常用):当前指令的下一个指令的地址+偏移量
- 绝对地址
条件控制实现条件分支
相当于一般意义上的if else,改变控制流;
不过在现代处理器上比较低效。
条件传送实现条件分支
数据的条件转移,计算条件的两种结果,通过 「条件传送」指令来选取条件满足的那一个结果,改变数据流。
只有满足特定情况下,这种策略才能生效(1.其实就是要求该函数为pure function,无副作用,因为两个条件的代码都会得到执行,2.另一个隐含的情况便是,任意一个条件都不会产生错误ex:p ?*p:0,使用条件传送会先把 *p mov 到 rax,事实上如果 *p 未null 就会 空指针异常;3.如果分支包含大量的计算,条件传送也不会起到优化的作用)。
为何条件传送更快? 流水线作业。那什么是流水线呢? 后面的章节。
不支持单字节条件传送。条件传送指令如下(condition move):
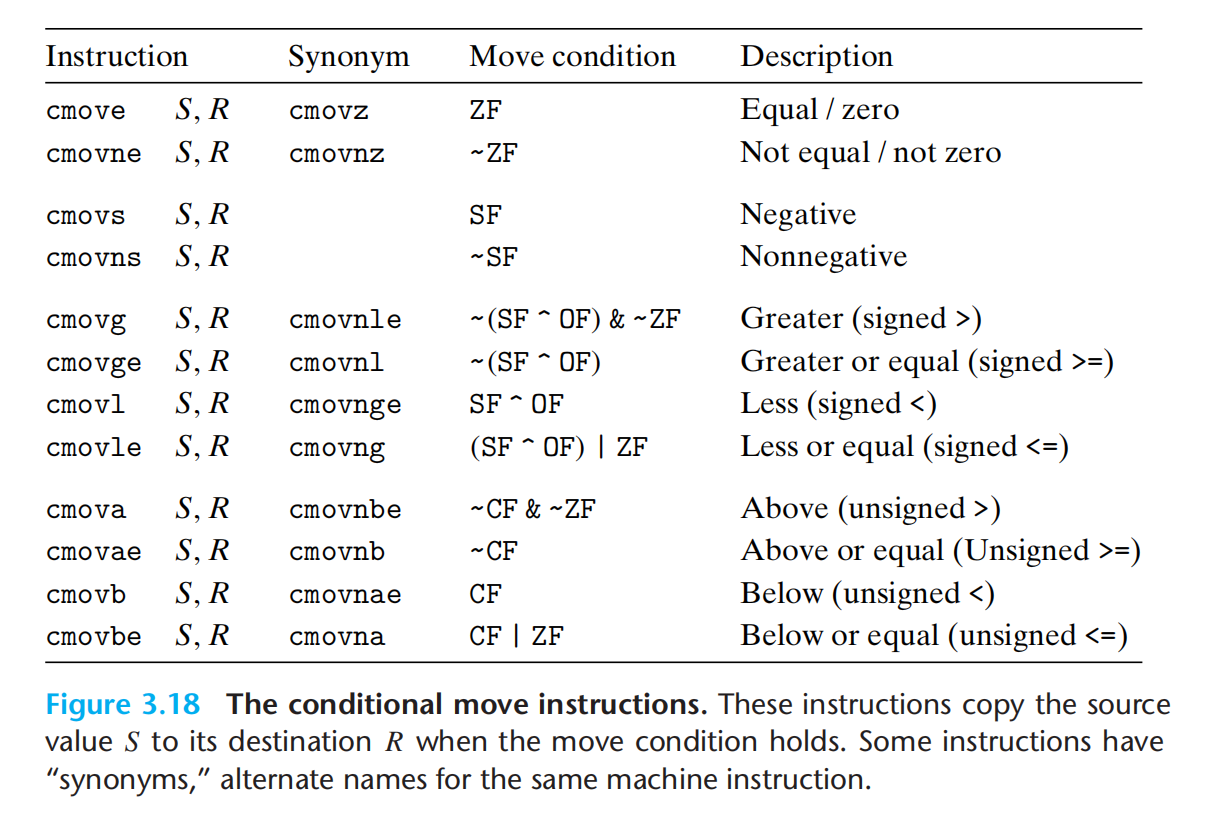
do-while
汇编中的循环,基于条件测试与跳转的组合。

while
while 循环翻译之一:

while循环翻译之二:


for
for 就是 while it’s all secret。
switch
可以通过整数索引进行多重分支:A switch statement provides a multiway branching capability based on the value of an integer index。
跳转表:A jump table is an array where entry i is the address of a code segment implementing the action the program should take when the switch index equals i.
switch的优点便是,执行开关语句的时间与case的数量无关,gcc当case数量较多且值的跨度较小时就会使用跳转表。
书中已经很精简了:p161
过程
cs61a中语言的三要素:值,函数,表达式。控制语句在这三要素中的那个位置?汇编中,控制通过跳转与条件来实现,如何与这三要素结合呢?
csapp中的过程指的是函数,实现特定功能的一组代码。
过程p调用过程q,过程q执行结束后返回过程p:
1.Passing control: The program counter must be set to the starting address of the code for Q upon entry and then set to the instruction in P following the call to Q upon return.
2.Passing data: P must be able to provide one or more parameters to Q, and Q must be able to return a value back to P.
3.Allocating and deallocating memory: Q may need to allocate space for local variables when it begins and then free that storage before it returns.
运行时stack
这里的stack是整个虚拟地址中的一部分,而整个虚拟地址,又是实际物理地址的一部分。
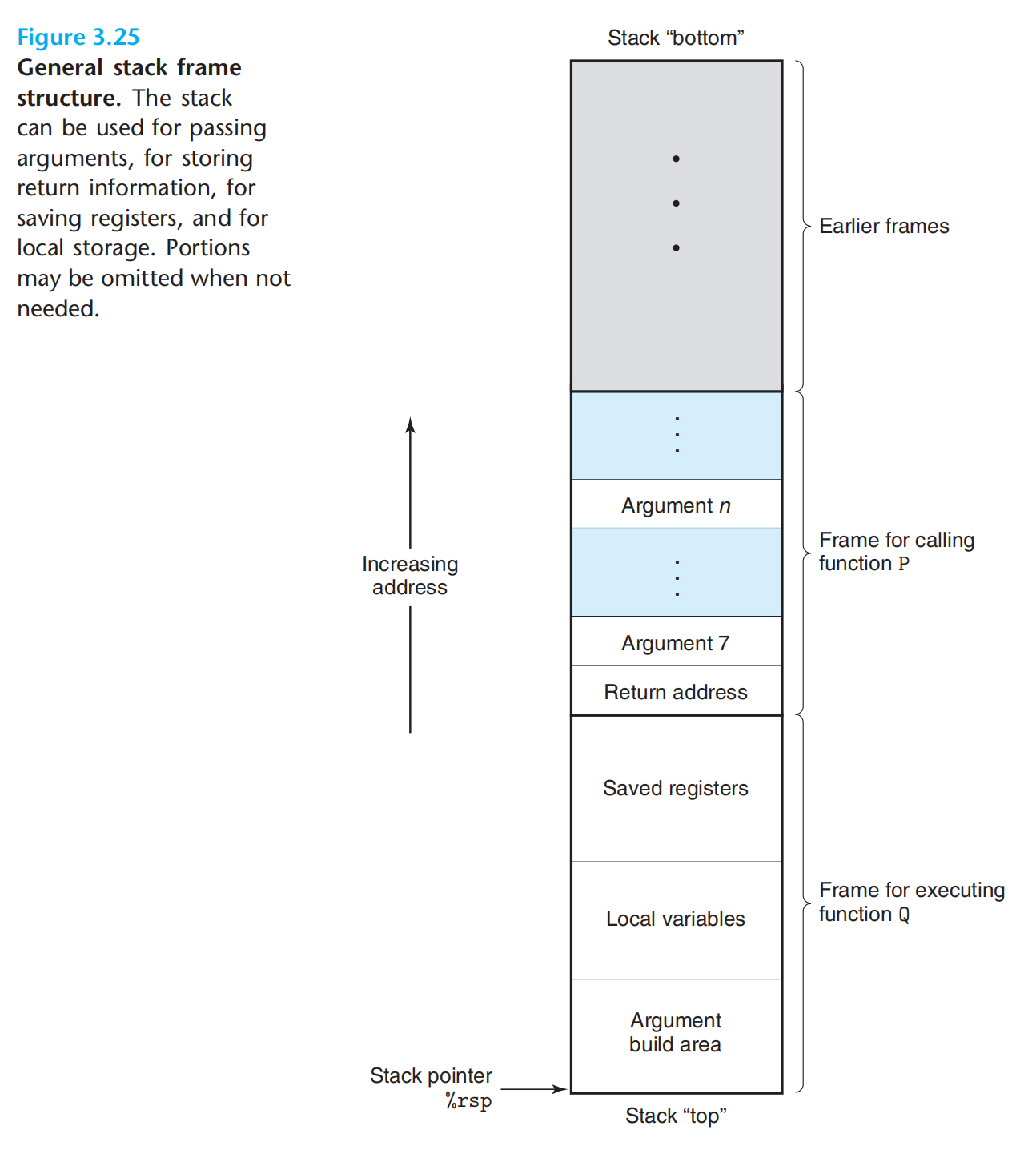
p调用q时,会在p的stack frame 中写入 p中调用q后面的那条指令的地址(返回地址)。
然后为q创建一个新的stack frame。可以存放…(上图)
如果q说需要的一切都可以用寄存器来提供,那么也是可以不需要stack frame的。
转移控制
大多数程序的标准调用与返回机制:
call & ret:
invoking procedure Q with the instruction call Q. This instruction pushes an address A onto the stack and sets the PC to the beginning of Q. The pushed address A is referred to as the return address and is computed as the address of the instruction immediately following the call instruction. The counterpart instruction ret pops an address A off the stack and sets the PC to A.
数据传送
X86-64 大部分的过程间数据传送,通过寄存器实现。
最多6个,寄存器的使用是有特殊顺序的。参数超过6个,需要stack来传递
satck上的局部变量

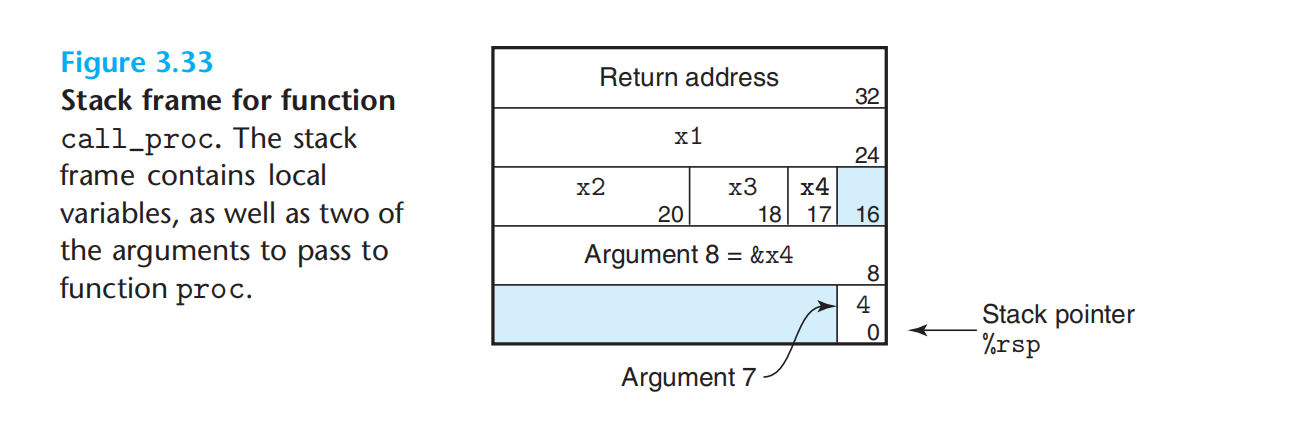
寄存器中的局部存储空间
p调用q
寄存器是唯一被所有过程共享的资源,必须保证p在调用q后还需要使用的寄存器中的值不会被q覆盖。
callee saved registers:By convention, registers %rbx, %rbp, and %r12–%r15 are classifified as
1.不去改变。
2.调用时,压入stack,返回时再弹出旧值。
递归过程
funny
todo应该思考下换零钱递归的汇编表示及执行过程中的stack 变化。
复合数据结构
数组
声明数组,名称就是起始位置的指针。
矩阵乘法,转化为指针的固定偏移相乘。
异质数据结构
struct:类似数组,结构的所有组成部分存放在一段连续的内存中。
union:
控制与数据的结合
缓冲区溢出:练习3.46;
防止缓冲区溢出攻击:(just konw 即可 skip)
1.地址空间布局随机化(Adress-Space Layout Randomization),stack位置随机化。
2.stack破坏检测:在缓冲区与保存的状态之间插入 canary值,进行标记。
3.限制可执行代码区域
变长stack frame;用表达式代替具体的stack分配数值。程序实际运行时才能知道具体的stack。
浮点数
16个YMM寄存器,专门保存浮点数。
浮点数的转移指令:p206
浮点数的转换指令:p207
浮点数的传参:
浮点数的运算:
浮点数的位级运算:
浮点数的比较运算:
这里的细节不再深究,习题也没做。
处理器体系结构
我在纠结是否需要学习第四章节,似乎作为一名转行的软件工程师,我是否有必要需要了解处理器的一些特性呢?尤其是在了解完第三章节的汇编后,所有的高级语言都会转换到汇编这一机器级别,软件开始与硬件交互了,这似乎非常适合作为软硬件的边界,是否还有必要深入了解一点点硬件的知识呢?我是转行的,在转行之前唯一接触到的一些计算机知识边只有vb与sql,相对于科班,我认为的一大短板在于对相关概念的缺失。人类在构建这一事物的诸多抽象概念,才是这一事物有价值的东西,蕴含了伟大的思想与思考,智慧的结晶。从了解概念的这一角度出发,why not?相比于哲学及社会学中极其难以理解的概念,计算机中的概念,简单的多了,只不过数量级也多了几层。所以,向处理器体系结构发起挑战吧!先提前庆幸一下,这一次没有project😊。
20241004,国庆的第四天,今天是非常重要的日子,意味着国庆假期的量变的转换。当学完之后,总结时再次回顾本章,为什么要比汇编更深入一点点,我们有了更多的理由:并发!,硬件之间的速度差异产生了并发的需求,而流水线与乱序执行则是并发的物理实现!理解了流水线也就理解了并发,凭着直觉我预测一波,这些概念对于将来理解并发的许多细节,也是非常有益的。计算机的一切都是建立在物理基础上,Powerful but not magic,祛魅!
汇编语言是一个层级而非某个具体的语言,与其处于同一抽象层次的概念便是高级语言而非高级语言的某一种,与之对应的还有一个概念:
instruction set architecture (ISA) 指令集体系结构:the ISA provides a conceptual layer of abstraction between compiler writers, who need only know what instructions are permitted and how they are encoded, and processor designers, who must build machines that execute those instructions.
The ISA model would seem to imply sequential instruction execution, where each instruction is fetched and executed to completion before the next one begins. By executing different parts of multiple instructions simultaneously, the processor can achieve higher performance than if it executed just one instruction at a time
指令集体系结构是计算机硬件与软件之间的接口规范,它定义了处理器能够执行的指令集、指令格式、寻址方式、寄存器组织等。ISA 规定了处理器的基本功能和行为。具体的汇编语言是其对应的ISA的一种实现,汇编语言中的指令与ISA中的机器指令一一对应。ISA 本身是一种硬件规范。
This idea of using clever tricks to improve performance while maintaining the functionality of a simpler and more abstract model is well known in computer science
goal:使用许多精密的技巧提升性能的同时,又维护功能上简单与抽象。
Y86-64
因为这个指令集是设计出来了解计算机处理器结构的,故没有必要深究其具体内容,书中也已描述的很简单了。
4042cdab896745230100 = rmmovq %rsp,0x123456789abcd(%rdx)
40=rmmovq
4=%rsp
2=%rdx
cdab896745230100 = 0x123456789abcd
逻辑设计与硬件控制语言HCL
逻辑门:基本计算单元,数字电路中的基本变量了。
组合电路:逻辑门遵循一些限制,组合成的一个网,(计算块)。一大特点便是会持续响应输入。
字级组合电路:通过对位级的组合电路抽象形成。
集合关系?2位控制4位 s0 = 01or11、s1 = 10 or11 ?,大概意思就是两位的二进制包含四种类型的信息量。
存储器与时钟:存储设备都是由时钟控制的,时钟是周期信号,决定了何时将新值加入到设备中。
如前所述,组合电路不存储任何信息,只响应输入。为了产生时序电路,必须引入按位存储信息的设备。
时序电路:有状态,并且在这个状态上进行计算的系统
存储设备:
- Clocked registers (or simply registers) store individual bits or words. The clock signal controls the loading of the register with the value at its input
- Random access memories (or simply memories) store multiple words, using an address to select which word should be read or written. (虚拟内存地址 & 寄存器文件)
注意:时钟寄存器(硬件寄存器)不同于前面汇编中的寄存器(程序寄存器),后者属于上面的ram。In hardware, a register is directly connected to the rest of the circuit by its input and output wires. In machine-level programming, the registers represent a small collection of addressable words in the CPU, where the addresses consist of register IDs。These words are generally stored in the register file。
Y86-64的顺序实现
一条指令的处理:
- 取指:内存中读取指令,一条指令的一部分(icode+ifun / ra+rb / valc),并计算valp
- 译码:从寄存器文件中读入最多两个操作数
- 执行:
- 访存:数据写入内存/从内存中读数据
- 写回:最多写两个结果到寄存器文件
- 更新pc:设置为下一条指令的地址(valp)
后面便是不同类型指令在六个阶段的执行。




SEQ硬件结构:
我们假设一个时钟周期,跑完所有的数字电路,PC作为唯一的时钟寄存器,按照时钟频率调整输出
硬件单元,,也遵循:取址、译码、执行、访存、写回、pc更新
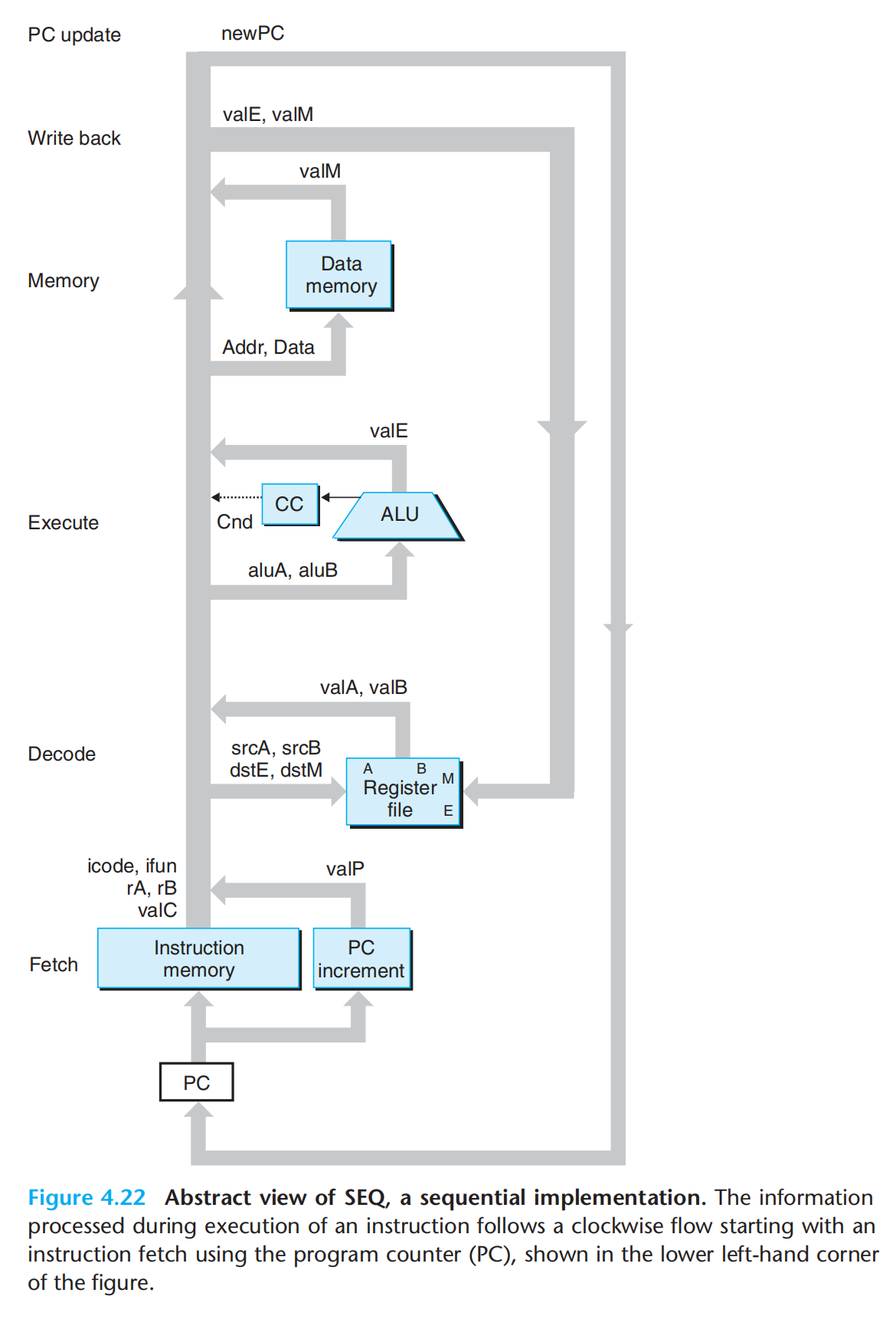
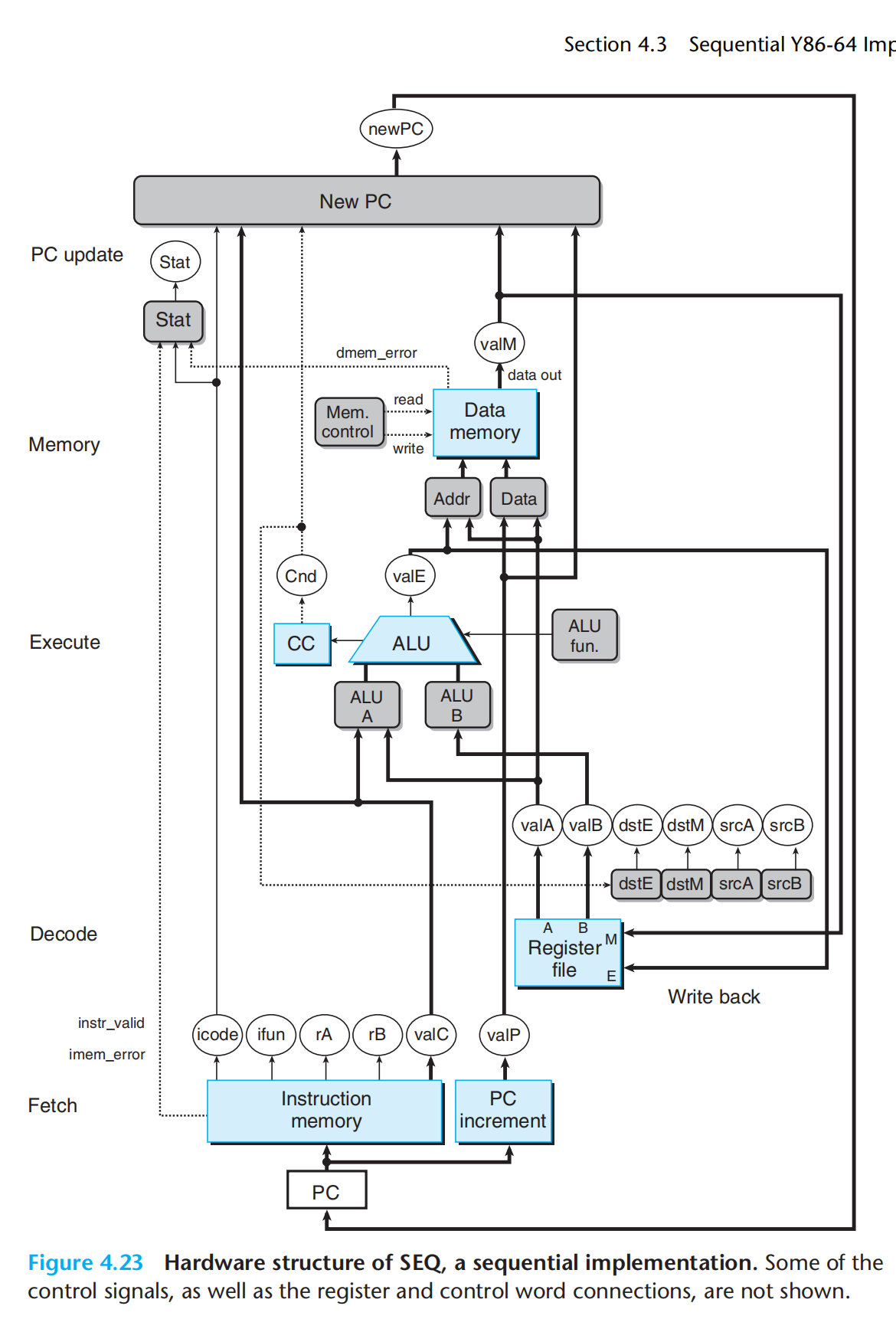
SEQ的实现:组合逻辑 + 两种存储器设备
- 时钟寄存器(程序计数器+条件码寄存器)
- 随机访问存储器(寄存器文件+内存)
如何实现在一个时钟周期,所有状态同步更新(一个时钟周期,跑完所有的逻辑电路)? 从不回读!(不会有先更新再读取的情况,即指令的语义,不需要为了完成指令而读取由改指令引起的状态变化),执行指令a,产生结果,但此时并不会写入a,执行指令b是,读取a的结果,同时将a的结果写入目标。
读操作,沿着单元传播
HLC:
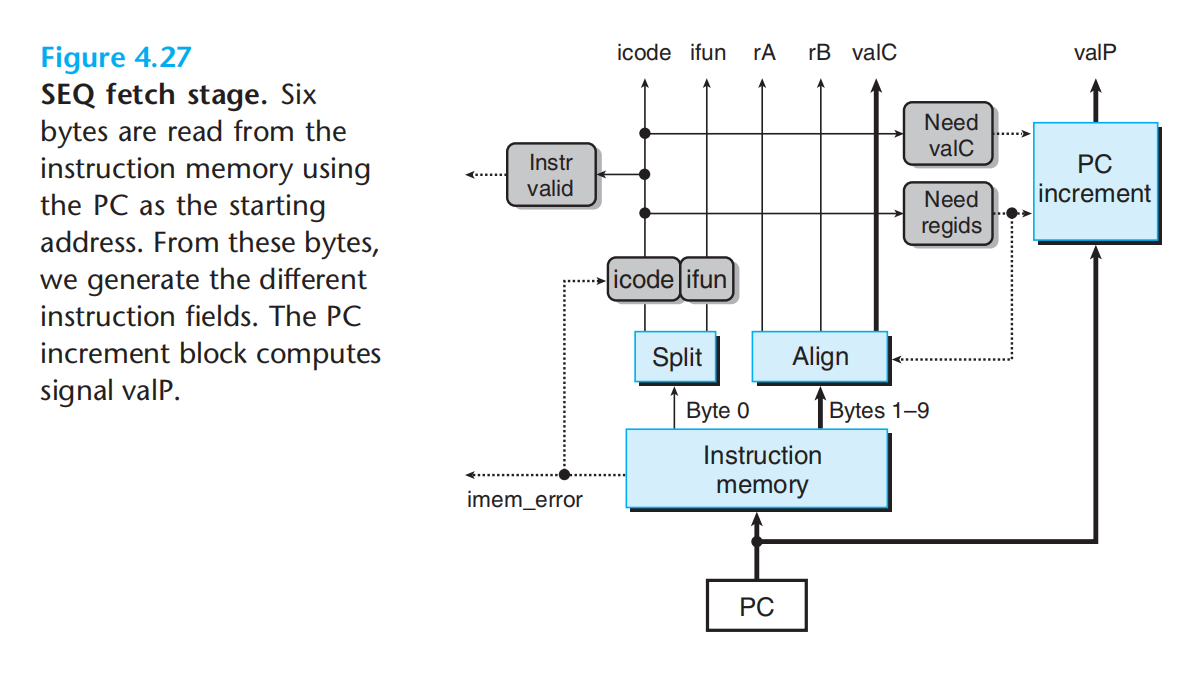
取码阶段,读取指令,通过逻辑电路将指令分解为不同的部分,同时更新一些其它部分的电路:PC部分的电路通过need valC & need regids + 原本的PC位置 判断并计算出下一个PC的位置。
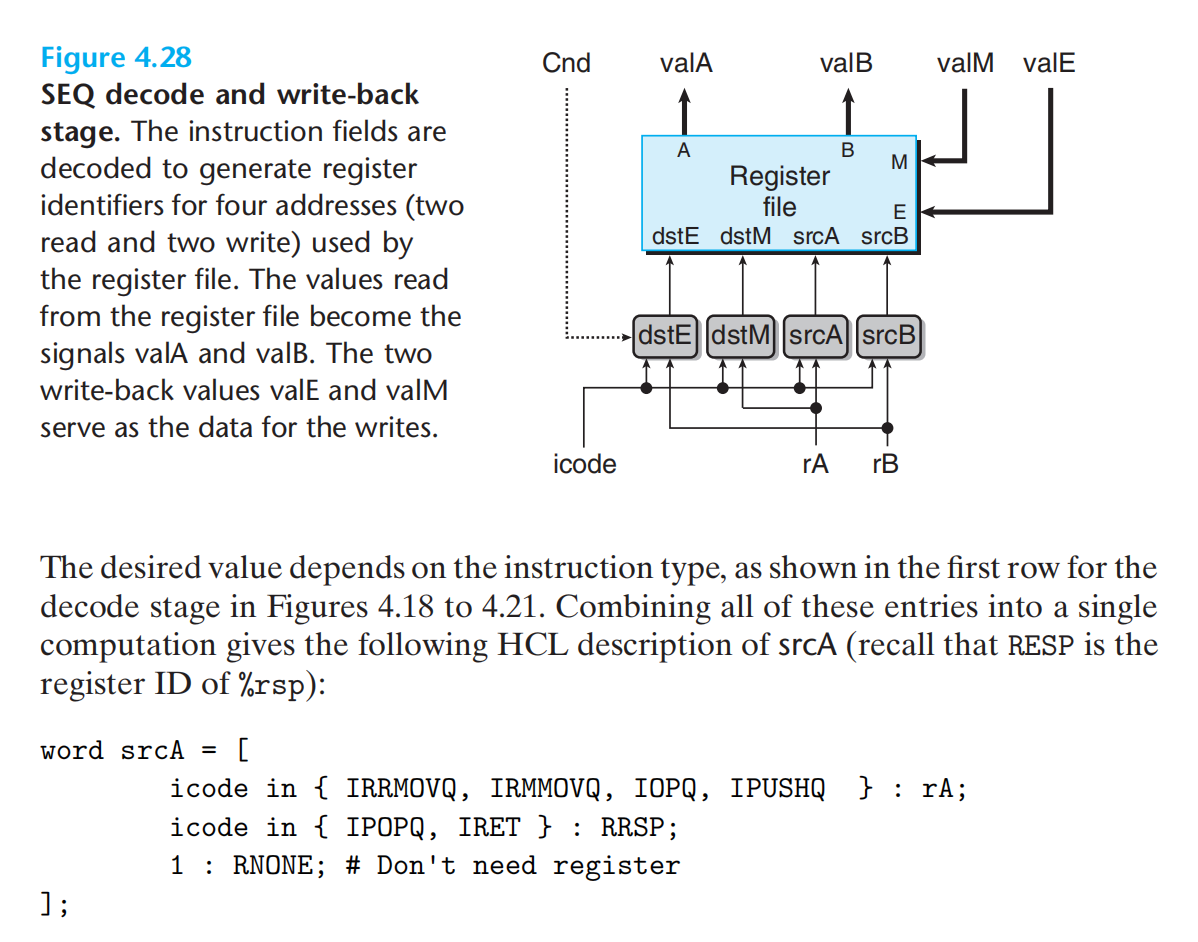
译码与写回阶段:
译码:从寄存器中读
写回:向寄存器中写
寄存器文件有四个端口,两个读(A,B)两个写(M,E)
每个端口有地址连接(srcA,srcB,destM,destE)与数据连接(valA,valB,valM,valE)
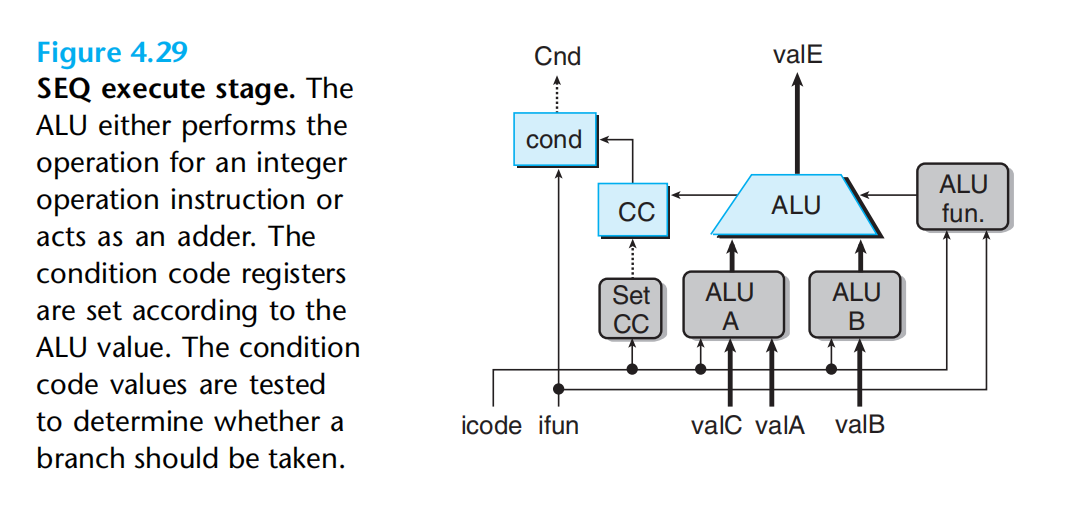
执行阶段:通过ALU fun决定,具体是哪个逻辑电路,输出valE
ALU A的值可以是valC/valA
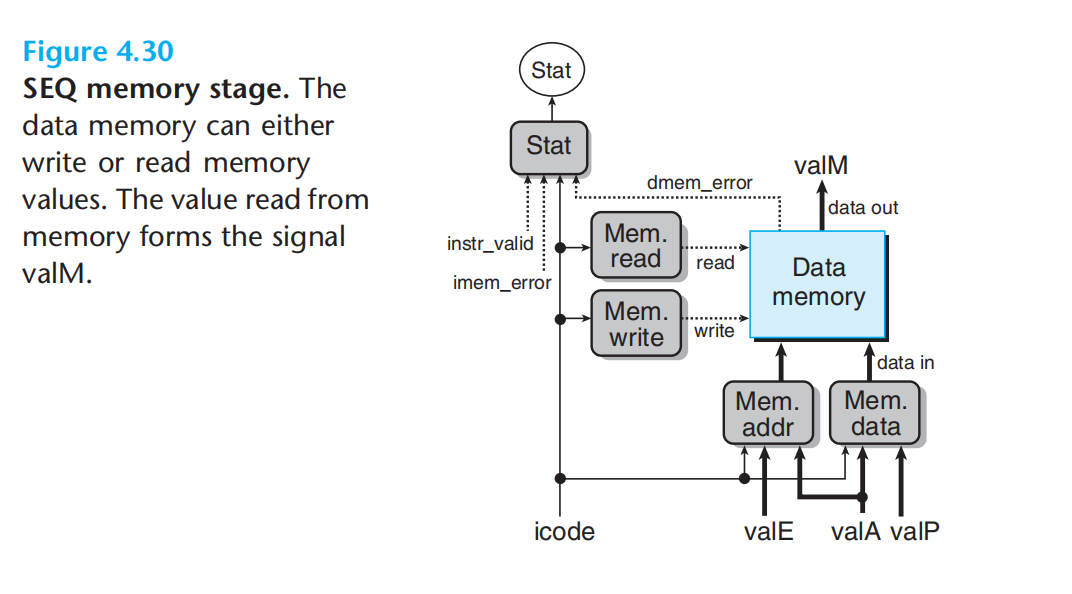
访存阶段:icode产生读/写的指令,读/写的地址永远是valE/valA
流水线处理
流水线化,提高了系统的吞吐量,但轻微的增加了系统的延迟(必须经历可能不需要的部分)。
关于流水线的一些量化:吞吐量与延迟
理想的流水线:各阶段相互独立,耗时一致。
实际流水线的局限:
1.各个阶段延迟的不一致,决定整体延迟的是最慢的那个阶段(因为每一次都需要等最慢的阶段结束才能进入下一阶段)。最慢的阶段*总阶段数量=最终延迟。
2.过深的流水线,收益递减(寄存器延迟是固定的)
实际的汇编中:
- 前后不同指令,依赖同一个寄存器(数据依赖)
- 循环中的控制指令依赖于前一次的结果(控制依赖)
设计流水线时,需要考虑反馈的影响。
Y86-64实现
SEQ+(pc):
将pc移动到最前面
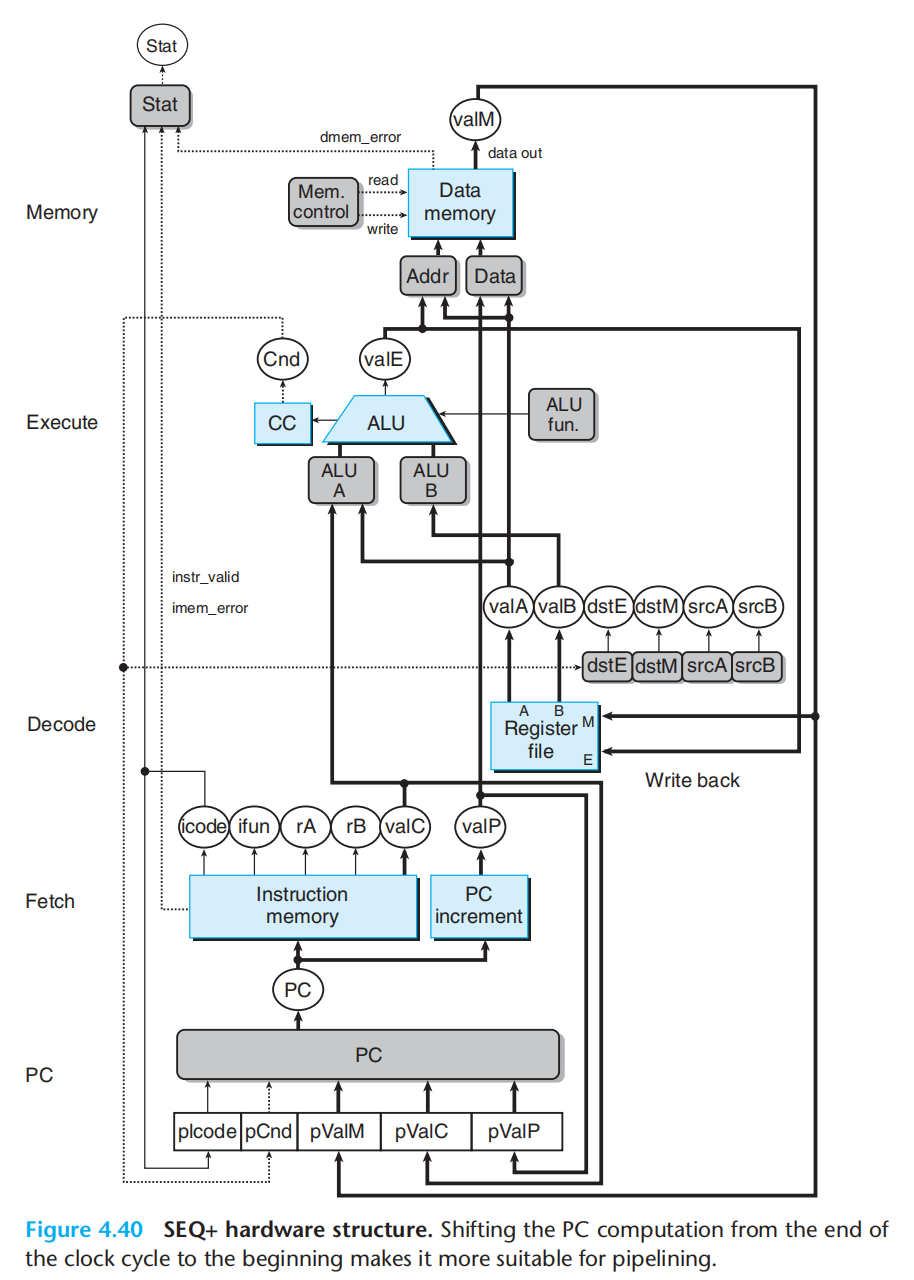
各阶段插入寄存器保存状态
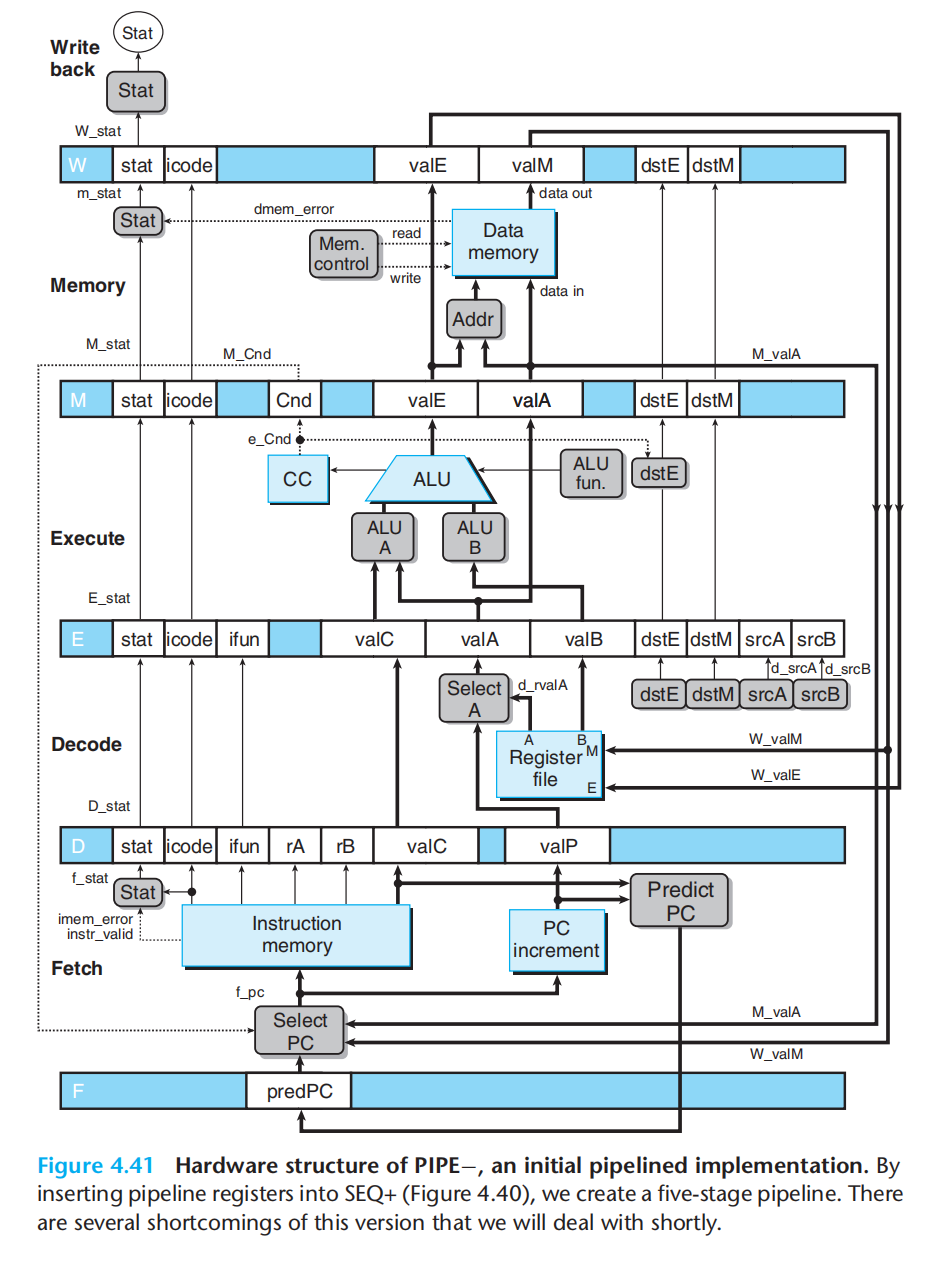
指令在上图硬件结构中的执行:
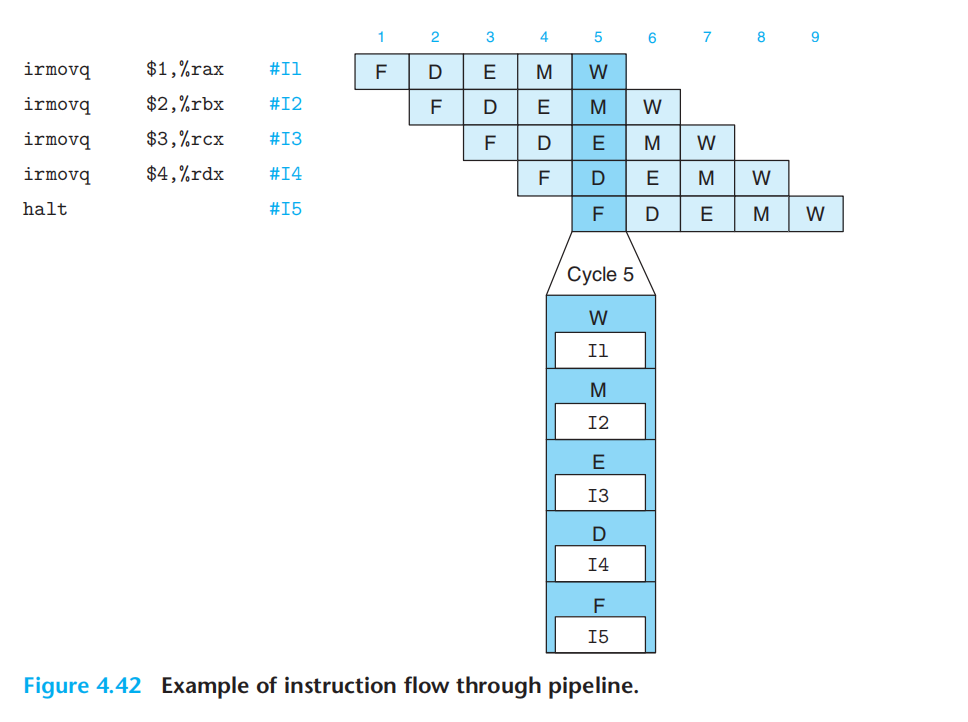
流水线寄存器
预测pc:例如条件指令中,我们总是选择走分支。
反馈有数据相关与控制相关,两种类型,不同的相关可能导致流水线计算产生错误,称之为数据冒险与控制冒险
数据冒险:
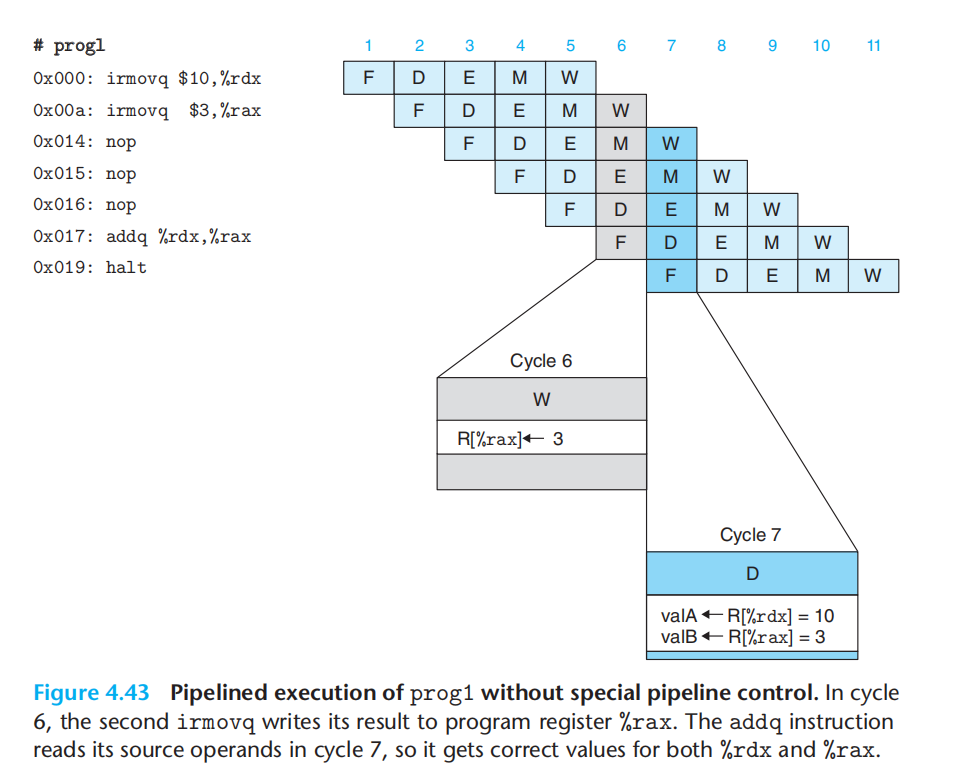
1.使用暂停,来避免数据冒险。添加nop。(执行0x17的代码时,0x00&0x0a的指令都已经结束了写回阶段)
2.数据转发,将结果直接从一个流水线阶段传到较早阶段。(此时依赖的值已经产生并保存在流水线寄存器中,但还没到写回阶段,数据还没被写回寄存器,通过增加额外电路,使之可以读取流水线寄存器中的值)
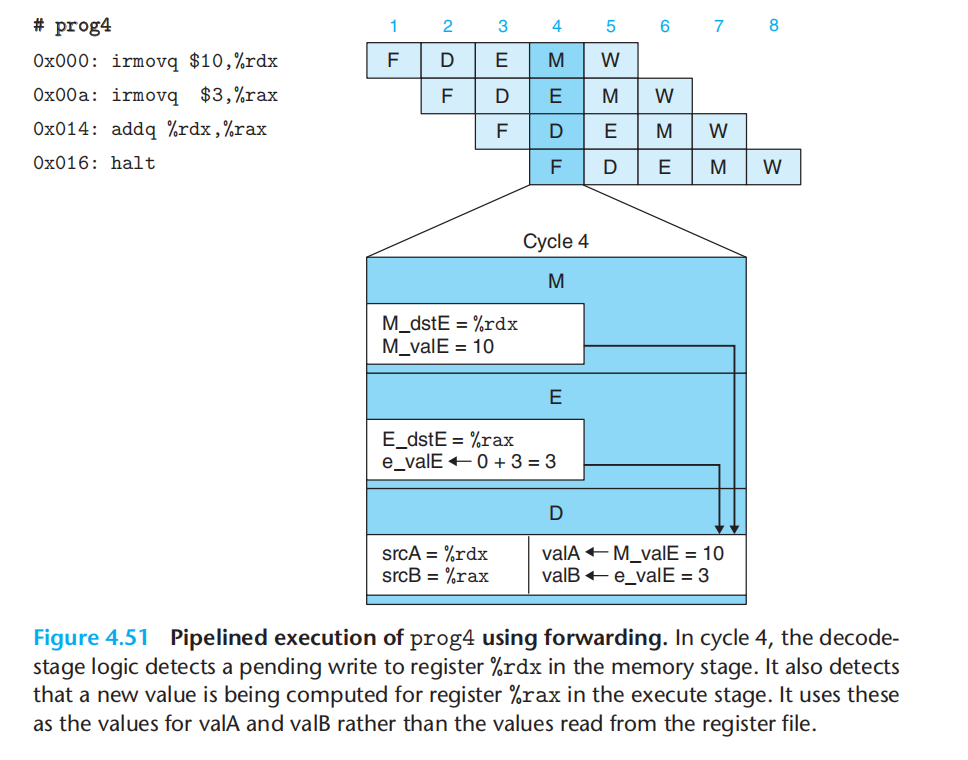
添加了转发后的流水线硬件结构:
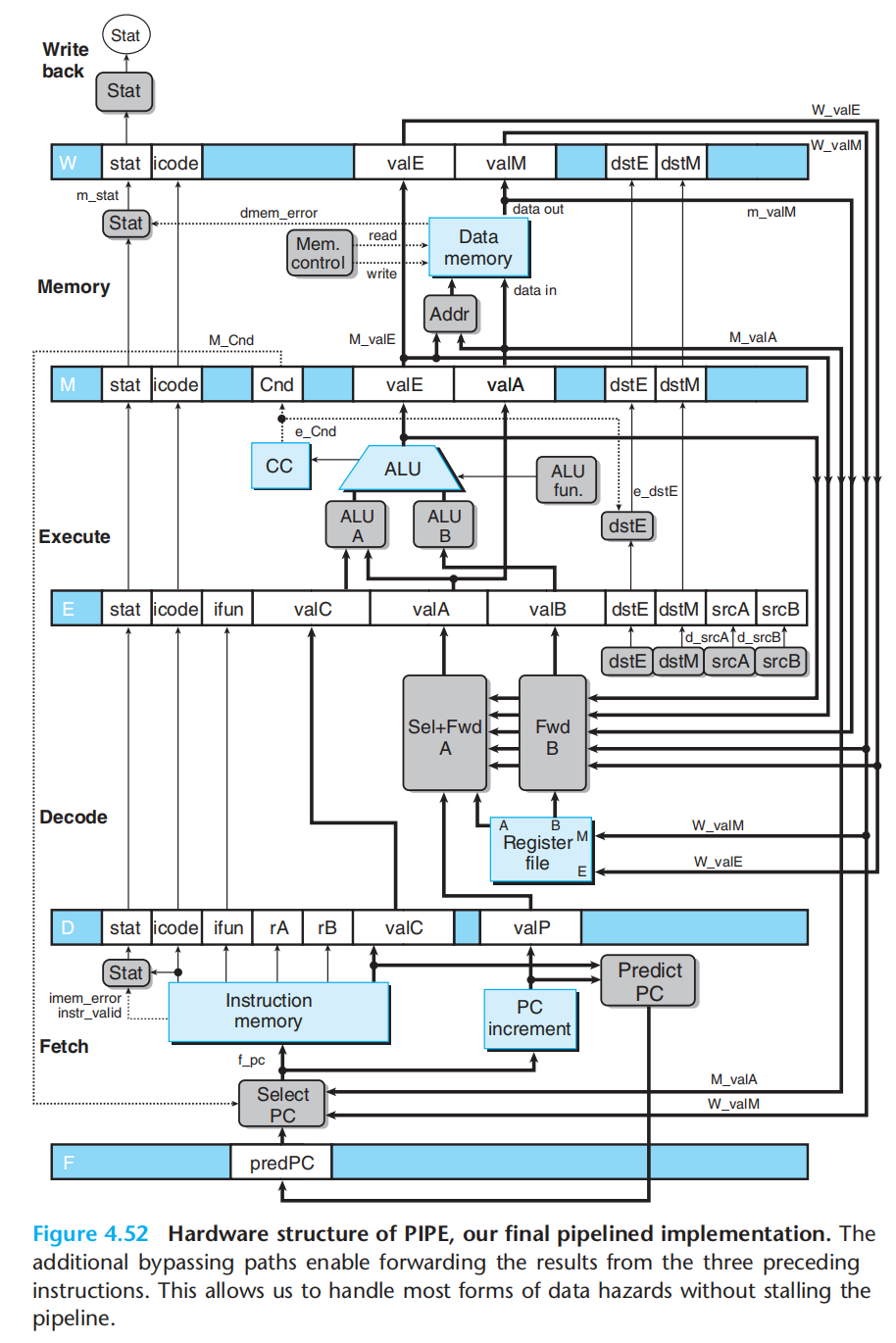
3.load/use hazard:为了解决,使用时,数据还未内存读,需要 将转发与暂停结合使用,(加载互锁)。
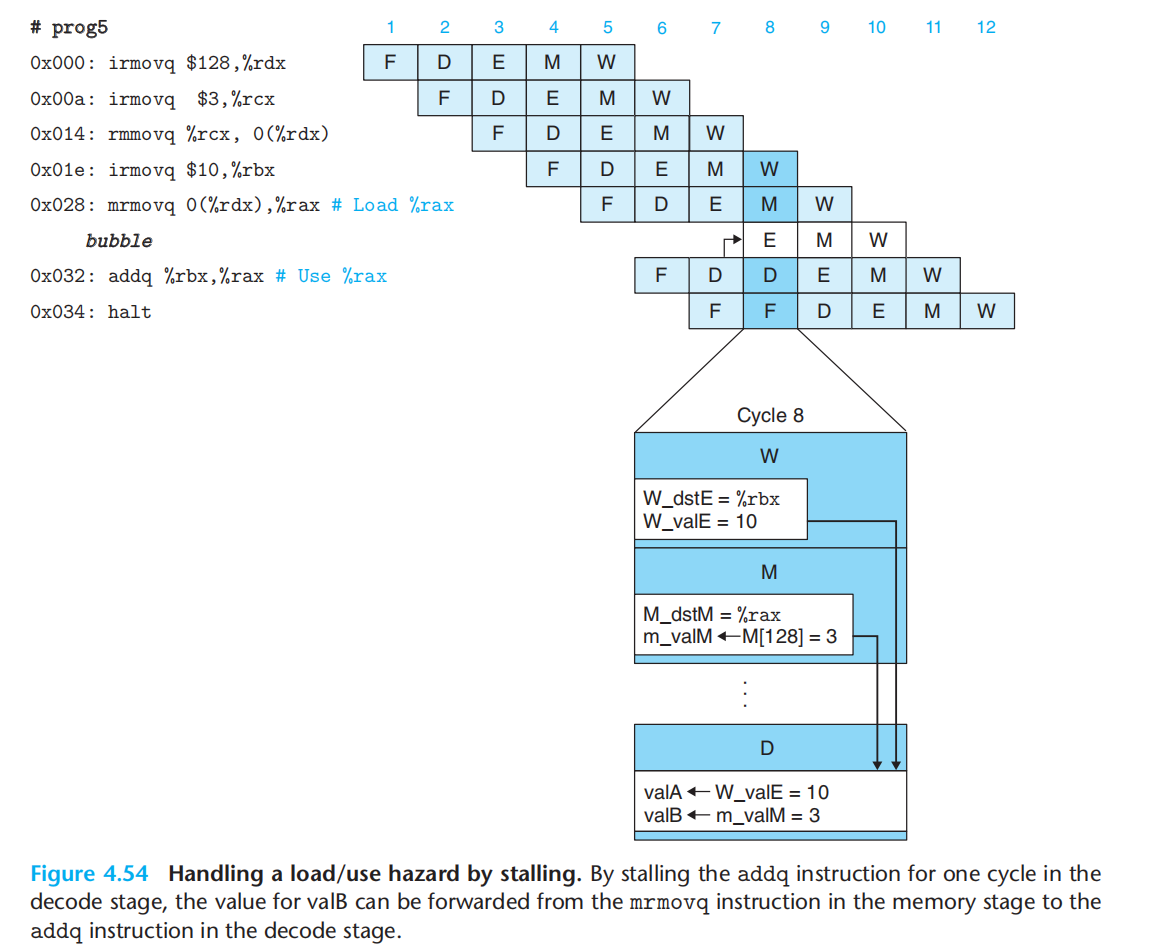
控制冒险:
此处的设计,只考虑ret 与 预测错误的跳转
ret:发现ret就暂停,直至写回阶段,才执行返回地址处的指令。
预测错误:发现错误就插入气泡,终止错误指令,执行正确的指令。
异常:
此次只考虑:halt、非法指令与功能码组合、访问非法地址
1.流水线化的系统中,可能有多条异常指令分布于不同阶段,原则:最深的指令,优先级最高。
2.预测错误的分支存在的异常,不应该被报告
3.异常指令再完成前,后面的指令不能改变系统状态。
当一条指令导致异常时,禁止后面的指令更新程序员可见的状态 & 异常指令到达写回阶段时停止执行。
处理:流水线寄存器中的状态字段
数据库与消息队列,不同流水线寄存器与不同阶段
PIPE的各阶段实现
不熟悉前面的个阶段这里是看不懂的,仅了解跳过。
流水线中的控制逻辑
不做过多介绍。
优化程序性能
这应该是程序员感兴趣的部分,但多年的业务代码写下来,长久停留在最重要的功能实现上了,至于优化,即使最简单的逻辑上的抽象,也在“不就是外包嘛,这么认真干嘛呢”的想法中渐渐消逝。
20241004:我们有了一串二进制的序列
第二章重点讲述了如何对这二进制序列赋予意义,通过字符集来表达字符,及整数(有符号二进制&无符号补码),浮点数(二进制小数到IEEE浮点数标准SEM),及这一体系下计算机的初衷:如何计算。将ISA作为一个锚点。
第三章则是软件侧对其的逼近,汇编语言完成对数据的操作,诸如,数据移动、控制转移、OP、switch;stack则是虚拟地址空间中过程的交互对象,涉及了本身的结构,各种不同类型数据结构在其中的表示,及过程执行时数据的操作如何与其交互。
第四章则是硬件侧对其的逼近,逻辑门到组合电路,再到字级组合电路,实现了物理层面的数据操作部分。再叠加时钟寄存器+RAM作为数据的存储,硬件层面实现了数据保存与数据的操作。在底层的基础抽象上面,通过取指、译码、执行、访存、写回、更新PC的基础逻辑框架设计了简单的顺序处理。通过在各逻辑组合之间插入寄存器用于保存阶段输出数据,实现了处理的独立,再叠加PC预测、数据冒险(暂停、转移、二者结合)、控制冒险(ret暂停,插入气泡)、异常处理等逻辑,我们实现了流水线处理,牺牲一点延迟的基础上,极大的提高了数据吞吐。我们程序所写的每一个字符,都有着坚实的物理基础,计算机强大,但不是魔法。
现在我们将查看基础的物理结构如何通过一层一层的抽象最终影响到程序的执行!
- 首先,最重要的永远是合适的数据结构与算法 Nothing can fix a dumb algorithm!
- 其次,便是一些技巧,产生更有效的机器码
- 最后,就是并行计算 optimization blocker:程序中哪些严重依赖于执行环境的方面。
- 消除不必要的工作
- 利用处理器提供的指令级并行能力(流水线)
编译器优化的能力与局限
正确性,是任何情况下的第一考虑要素。所以优化必须安全,实现不会改变逻辑。
编译器实现:高级语言到低级语言之间的映射(信息无损)
一些优化的挑战:
- memory aliasing 内存别名使用(多个指针,指向同一个位置)
- 函数副作用与内联函数替换(用函数体,替换掉函数调用来优化)
消除低效循环
消除循环低效:我想起了之前军哥说的,循环里面嵌套查询,那是还没入门的表现。
处理器抽象模型
CPE(Cycles Per Element):度量标准,每元素的周期数,1GHz = 10亿周期每秒。
指令级并行(instruction-level parallelism):观察到的层面是一次执行一条指令,实际处理器中是同时对多条指令求值。: they employ complex and exotic microarchitectures, in which multiple instructions can be executed in parallel, while presenting an operational view of simple sequential instruction execution.
上一章节中我们讲了顺序流水线处理,实际当前主要使用超标量处理器:一个时钟周期,多个操作;乱序执行。
现代微处理器体系:p357
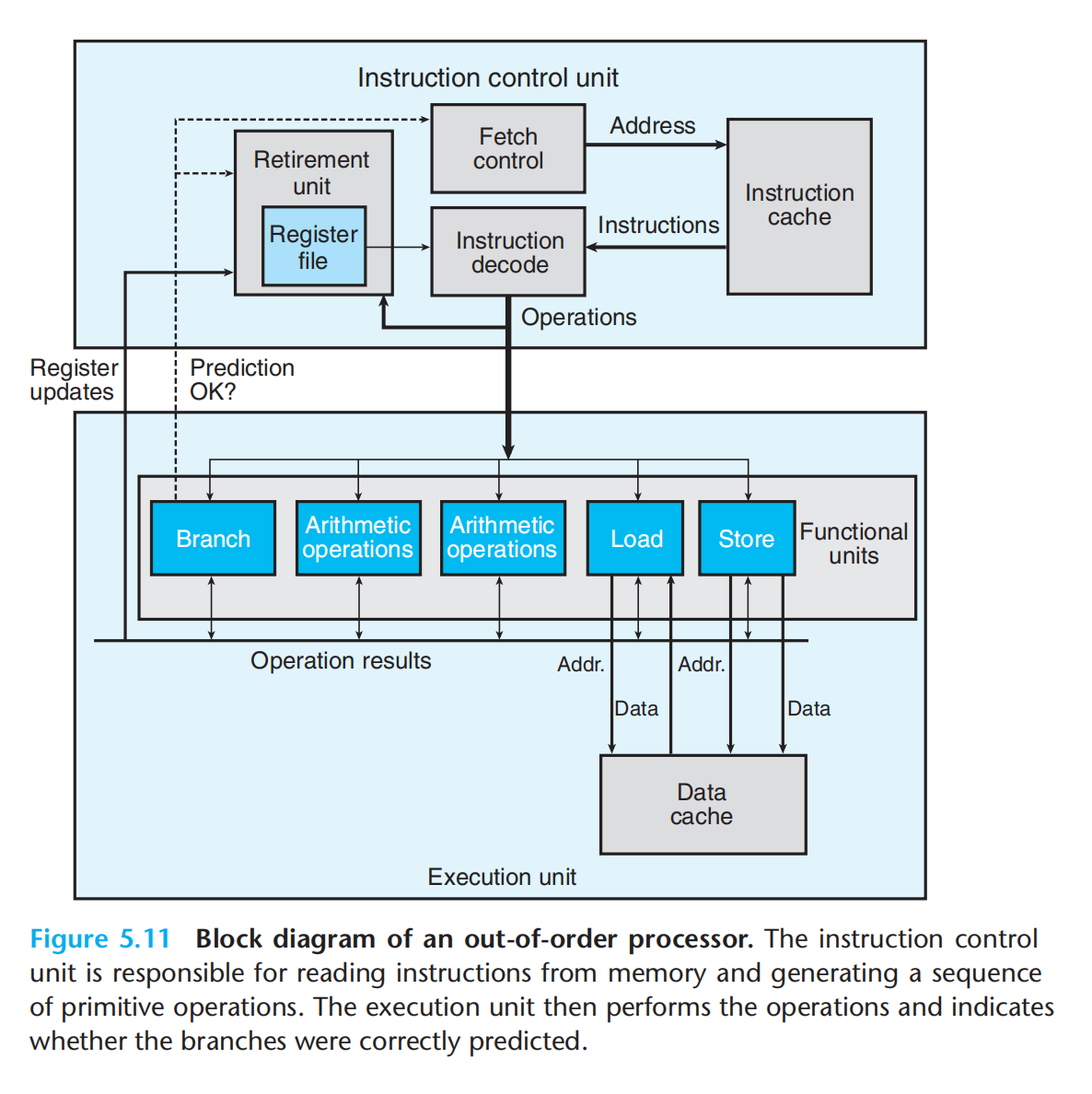
ICU:
1.取指
2.译码
3.退役:1.已验证,预测正确;2.已验证,预测错误; 会将指令及对应状态退出队列,只有预测正确并且指令退役时才会更新程序寄存器
EU:
1.多个分支处理单元:验证分支是否预测正确
2.多个计算单元
3.多个内存交互单元(加载&存储)
分支预测
投机执行
寄存器重命名(传递操作数)
指令译码 转换为 微操作
基本流程:
- 从指令缓存取指令
- 指令译码成微操作
- 被分配到一组功能单元执行(核心:运算、加载、存储)(我们所描述指令级并行结构)
- 这一组基本功能单元,相互之间可以进行数据传递功能单元的性能刻画:
- 延迟:执行操作所需总时间
- 发射:两个同类型独立操作需要的最小时钟周期(1:每个时钟周期,都可以开始一条新的运算,延迟5,发射1 是通过流水线实现)
- 容量:执行该运算的功能单元数量
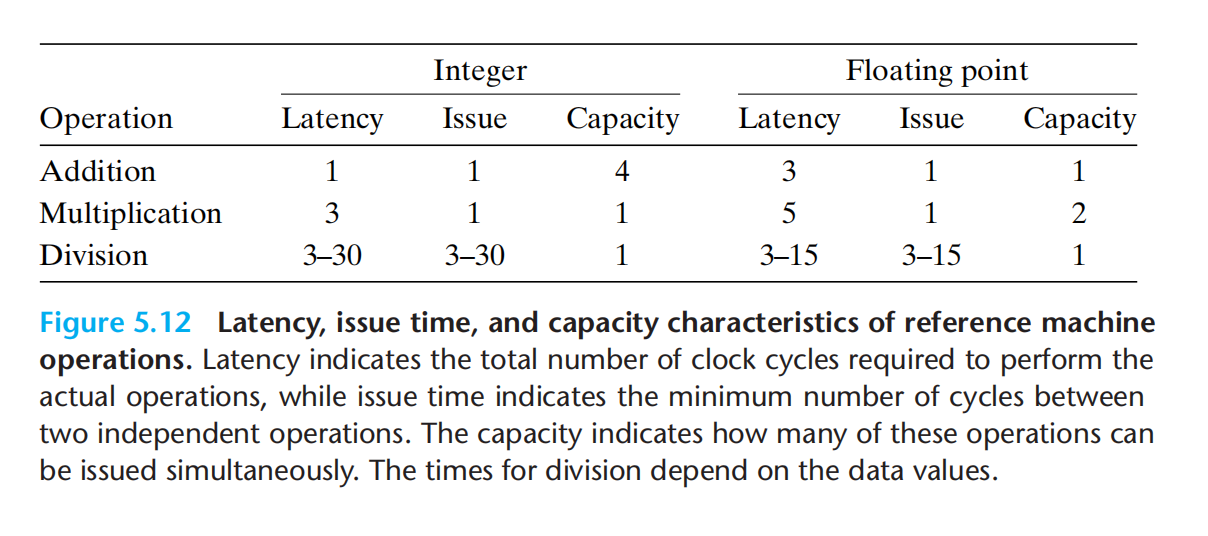
This short issue time is achieved through the use of pipelining. A pipelined function unit is implemented as a series of stages,each of which performs part of the operation.
The arithmetic operations can proceed through the stages in close succession rather than waiting for one operation to complete before the next begins. This capability can be exploited only if there are successive, logically independent operations to be performed.
之所以能实现如此短的发射时间,是因为流水线处理,流水线化后的每一个功能单元被视为完成一条指令的一系列阶段的一部分。
延迟界限(下限) latency bound :is encountered when a series of operations must be performed in strict sequence, because the result of one operation is required before the next one can begin。
吞吐量界限(上限) throughput bound: characterizes the raw computing capacity of the processor’s functional units
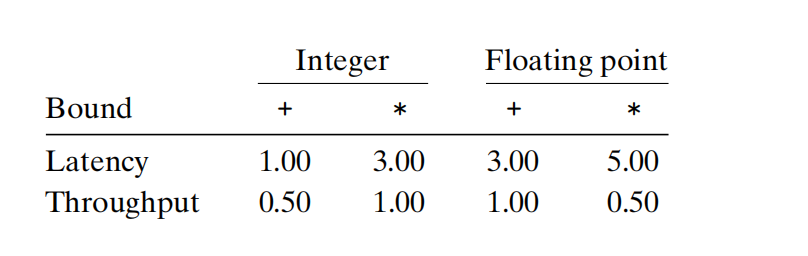
吞吐量:
整数加法:1(发射)/2(数据加载<功能单元?数据加载:功能单元)= 0.5CPE
浮点加法:1/1 = 1CPE
处理器操作的抽象模型:
形成循环的代码片段,可以将访问到的寄存器分四类:
1.只读
2.只写
3.局部(迭代内部被使用,但迭代之间不相关)
4.循环(迭代之间相关,涉及read & write)
循环寄存器之间的操作链,决定了关键路径。
每一次迭代中,由于并行,会存在关键路径,决定了整个操作的时钟周期。
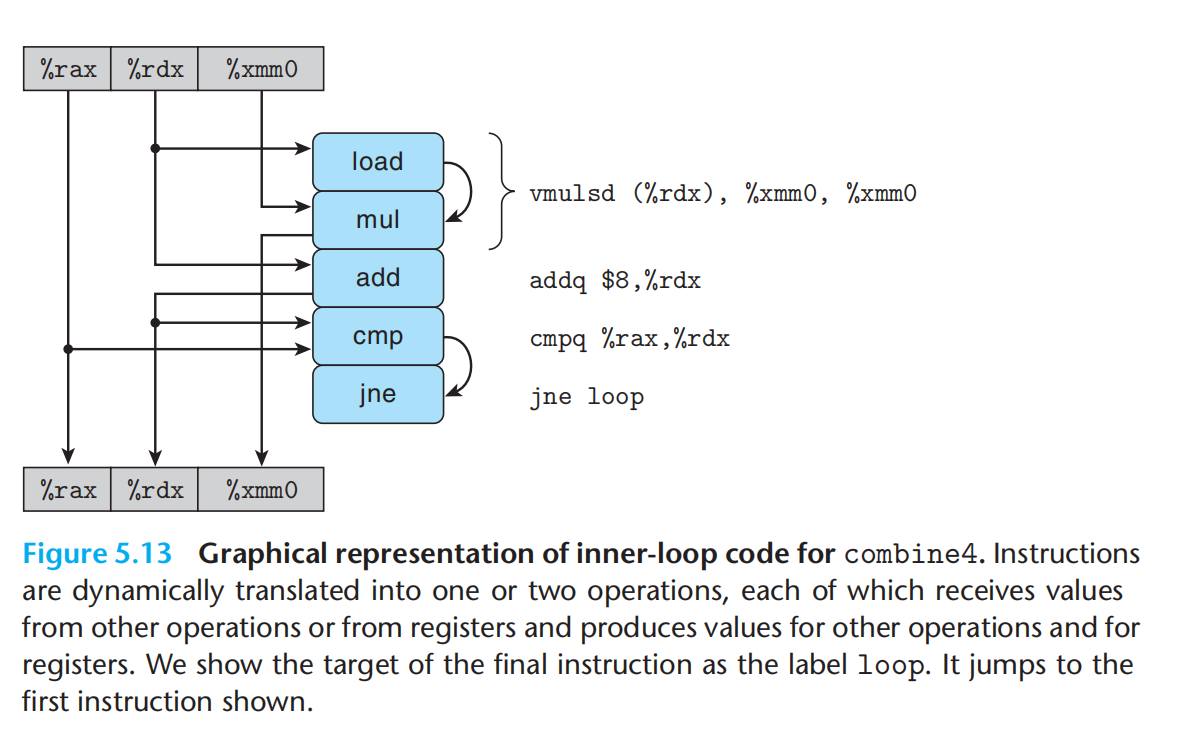
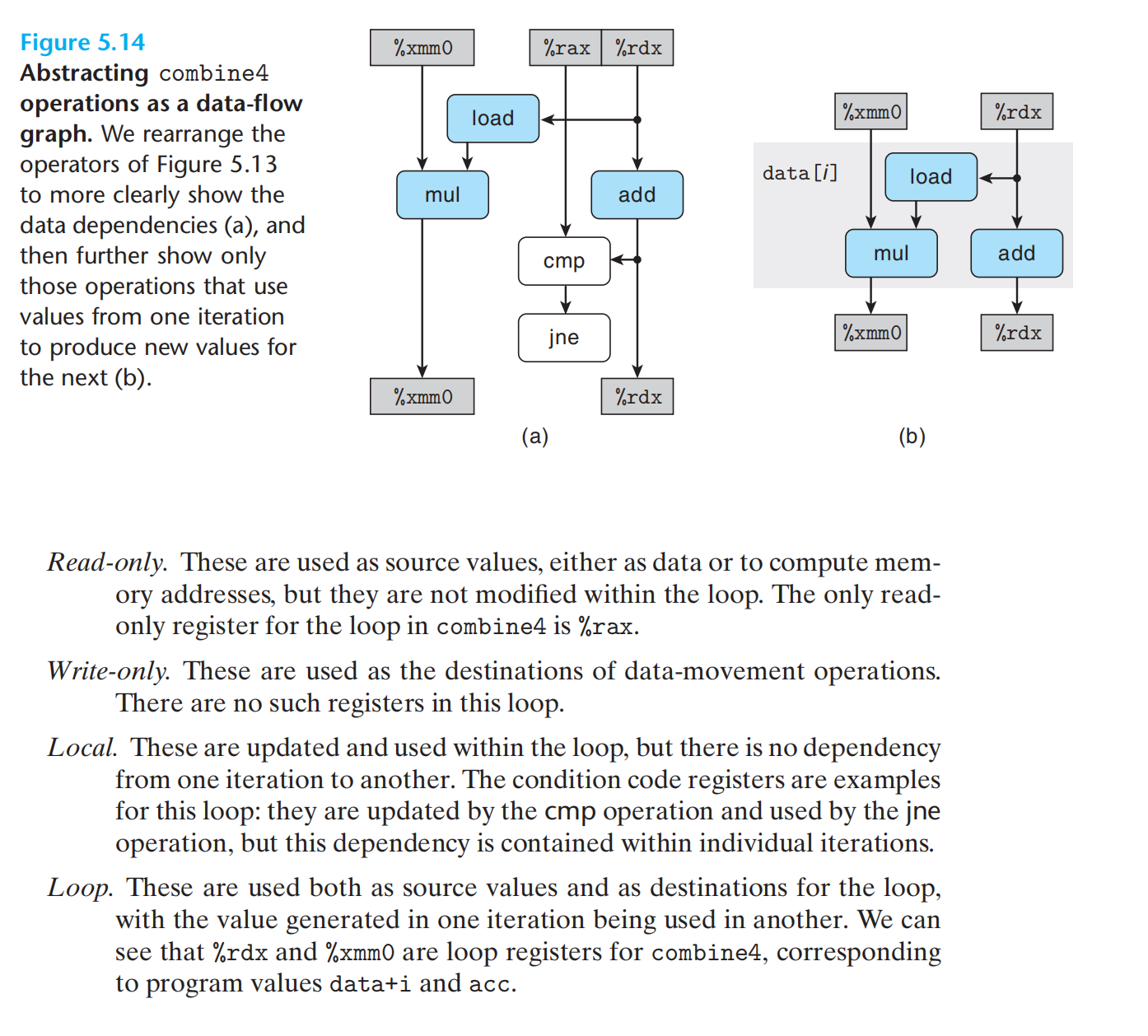
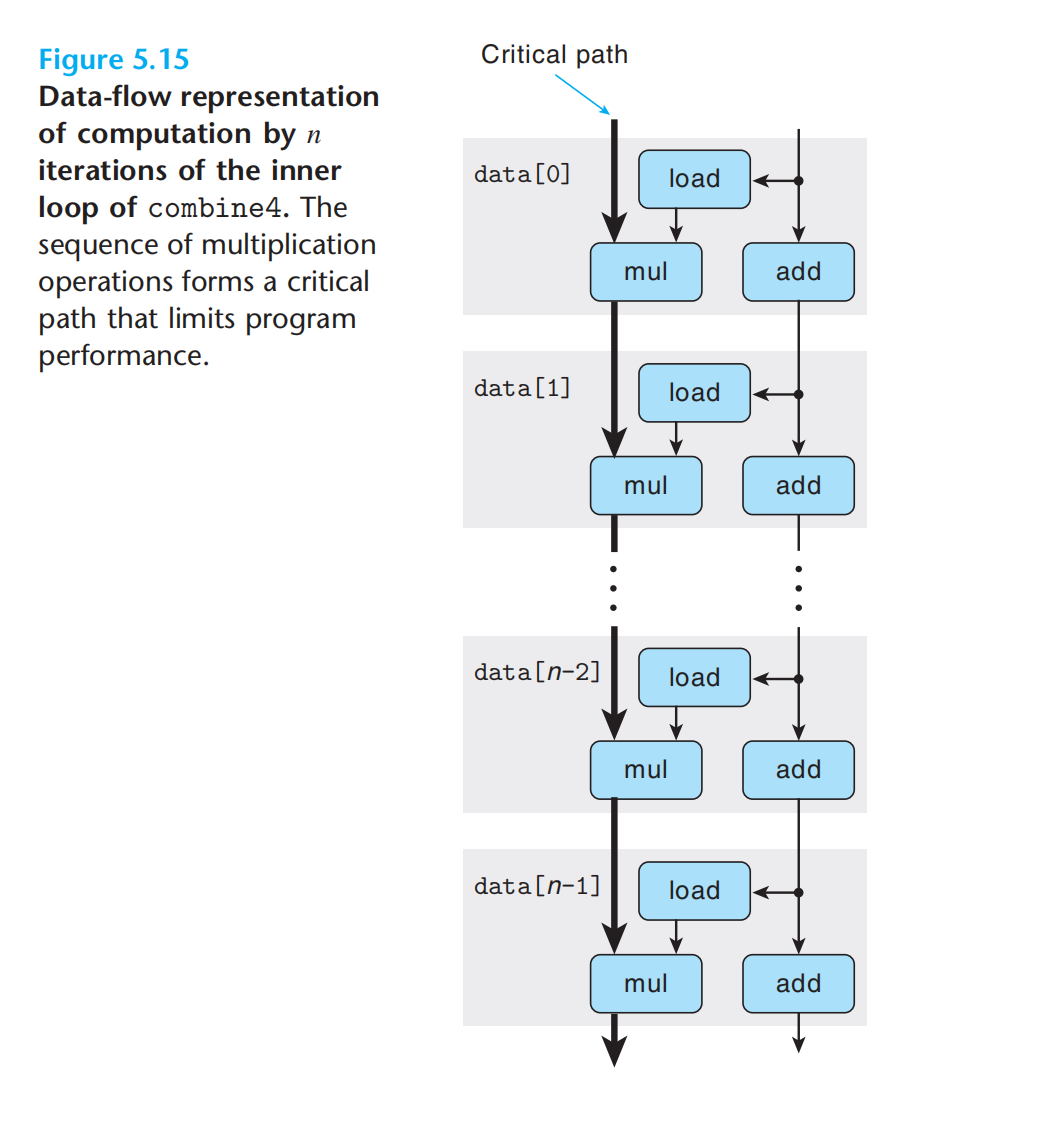
寄存器 & 迭代 = 关键路径 = 函数时钟周期
如上示意:浮点乘法器成了制约资源,循环中需要的其他操作(从内存中读取数据、指针移动等)与乘法器并行执行,每次后继acc被计算出来,它就反馈回来计算下一个值,不过要5个周期后才能完成。(重点理解:除开始外,后续的load 与 add 都会在mul开始执行前就被计算,可以理解为一次mul结束,就立马开始下一次mul,故CPE = mul延迟 = 5)
有了处理器相关知识,我们可以进一步解释循环展开如何能提高性能
- 减少了循环次数,也就减少了诸如 计算索引,比较的开销
- 可以减少关键路径上的操作数量(?内部传值?)
一般编译器就会优化这些了。
2 x 1 展开:

提高并行性
尽管流水线允许每个周期开始一个新的操作,但代码通常难以完全利用,因为值之间关联。
1.多个累积变量,将21 中的两个串行的mul,充分利用流水线,变成并行
流水线与前面的处理器抽象模型是什么关联?
延迟与容量?周期与功能单元
kk 循环需要 k>= C * L
2 x 2 展开

2.重新结合变换

amazing
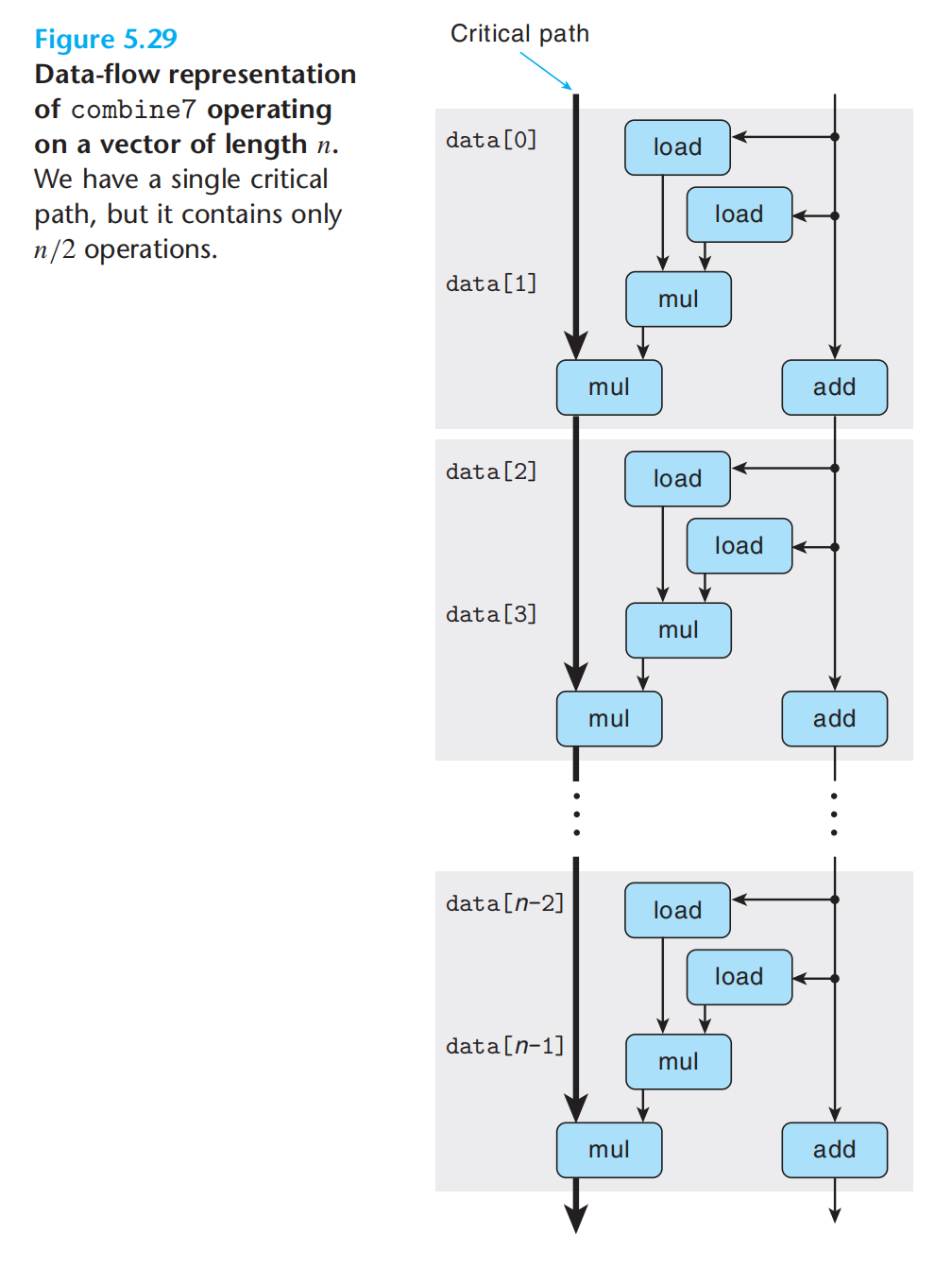
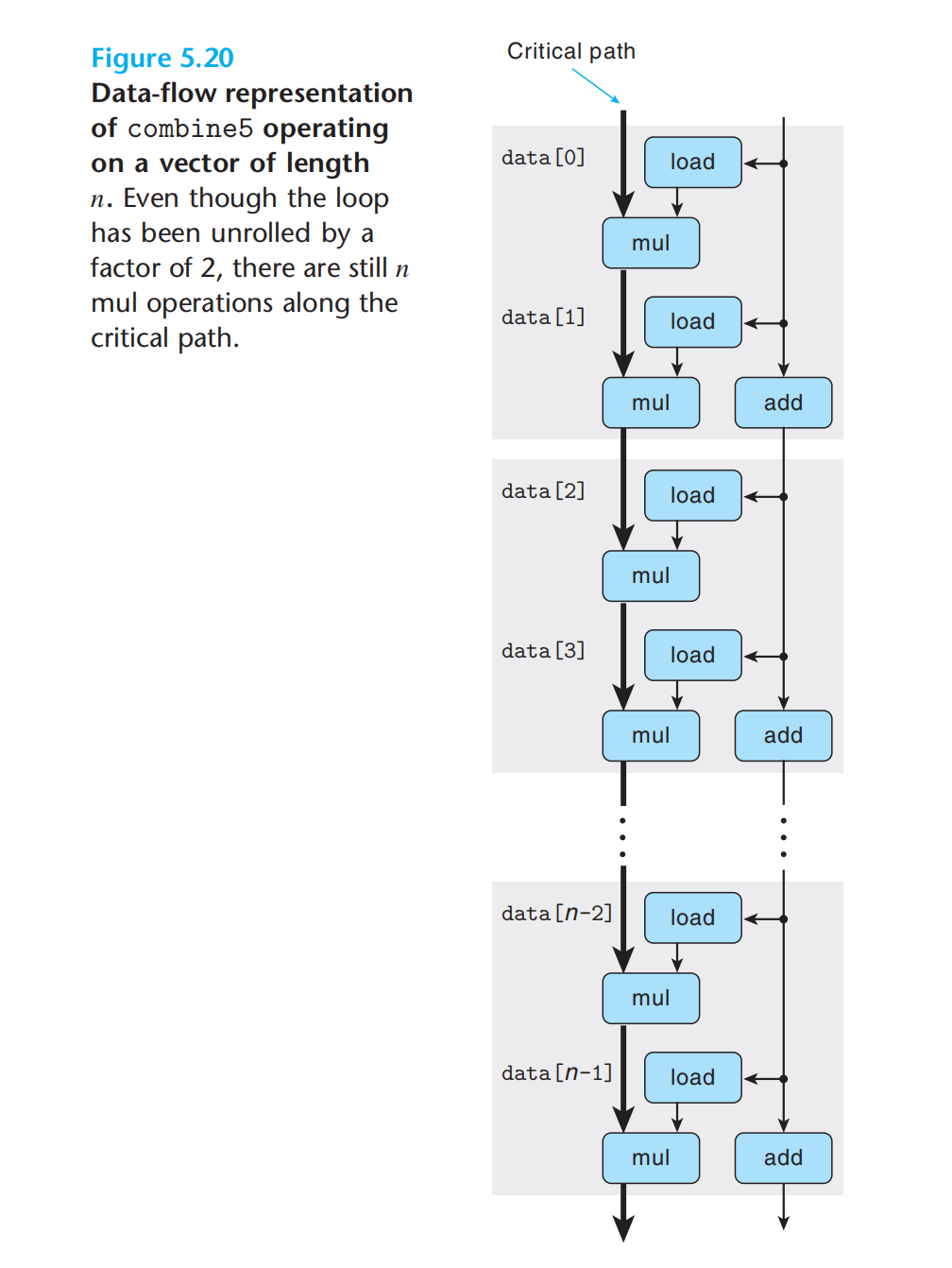
注意与5.20的区别
重新组合,使得第一个mul不需要等待前一次的累积值就可以执行了。利用流水线,串边并。
一些限制因素
1.寄存器溢出
需要存放的变量,超过寄存器的数量,将一部分放到内存堆栈中,增加了开销。
2.分支预测错误的惩罚
不必过分关注,毕竟分支预测主要是处理器硬件的事,软件层面,只能些许改变一点代码风格。分支预测只对有规律的模式可行。
理解内存性能
目前只考虑,交互对象是高速缓存的情况。
现代处理器的加载&存储功能单元。一个时钟周期可以进行一次操作。
加载,涉及寄存器
存储,一般不涉及寄存器,但当加载的结果受存储影响时,会增加CPE.
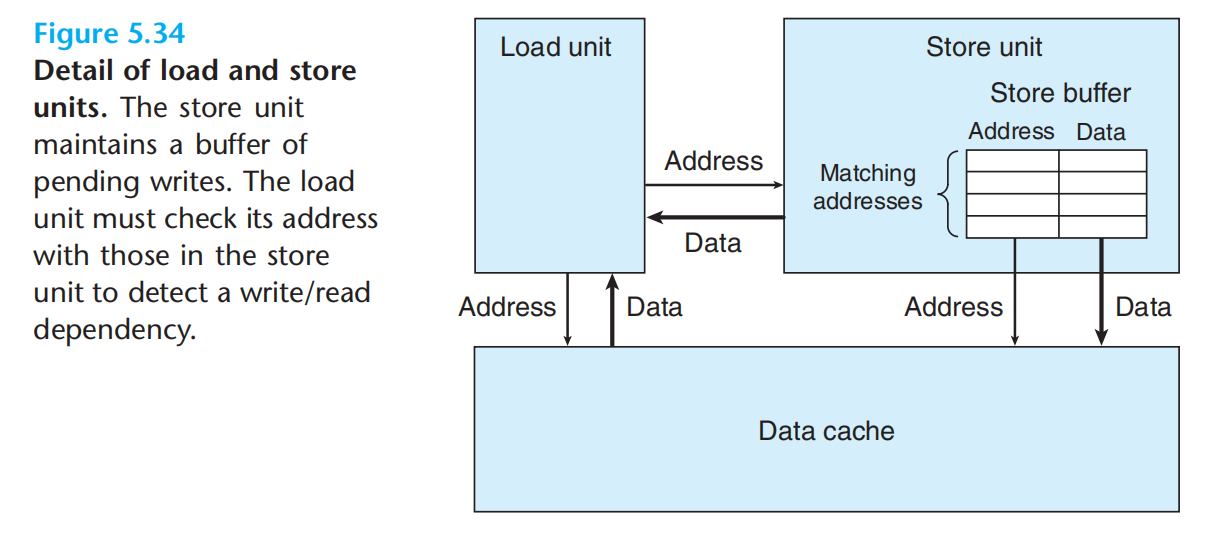
存储单元有store buffer,加载单元,优先访问store buffer,没有再访问data cache。
当迭代中存在,内存读写依赖,一次的读结果,依赖于上次的写时。加载与存储不能独立进行,关键路径变长。
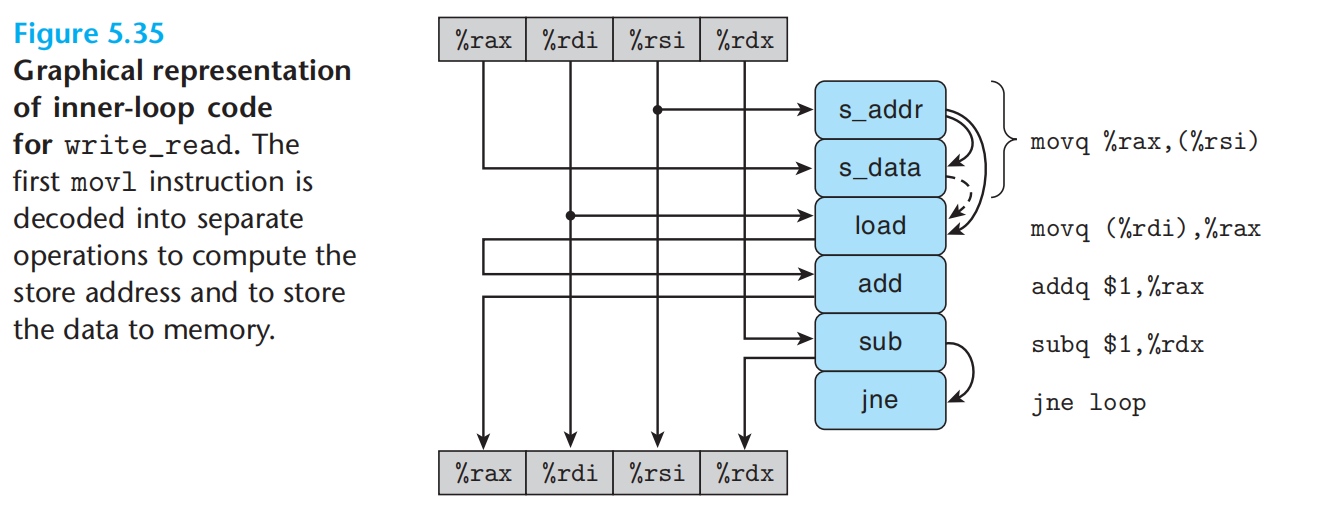
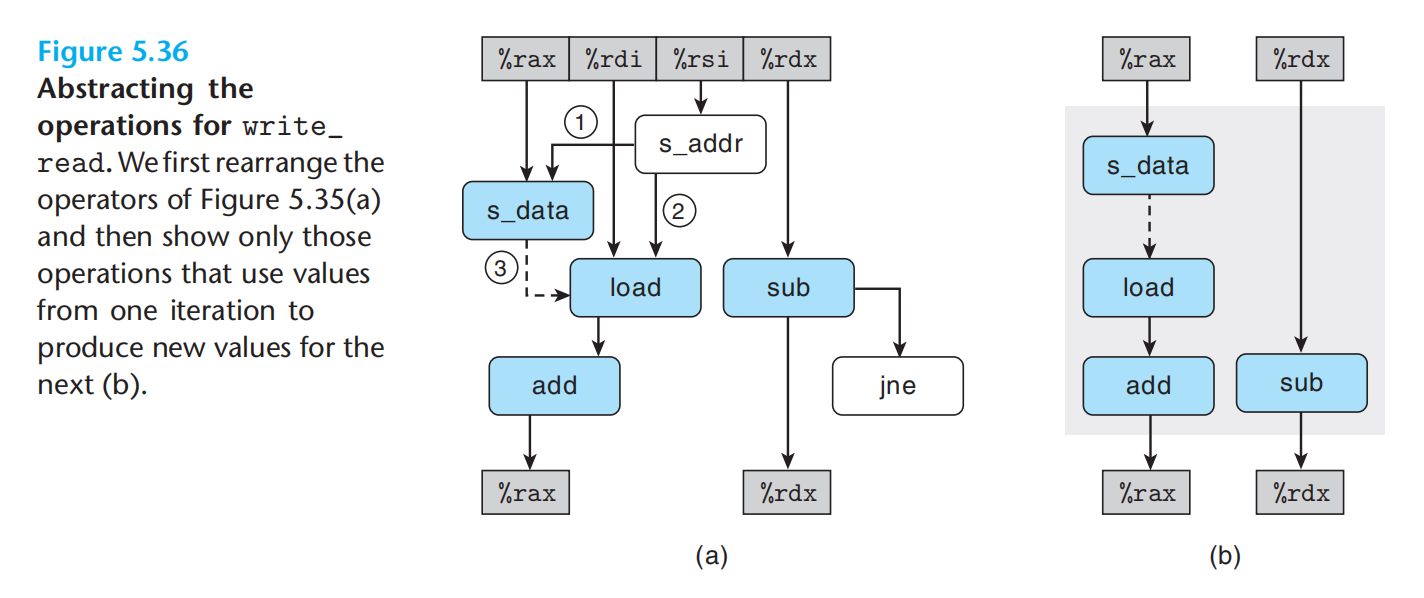
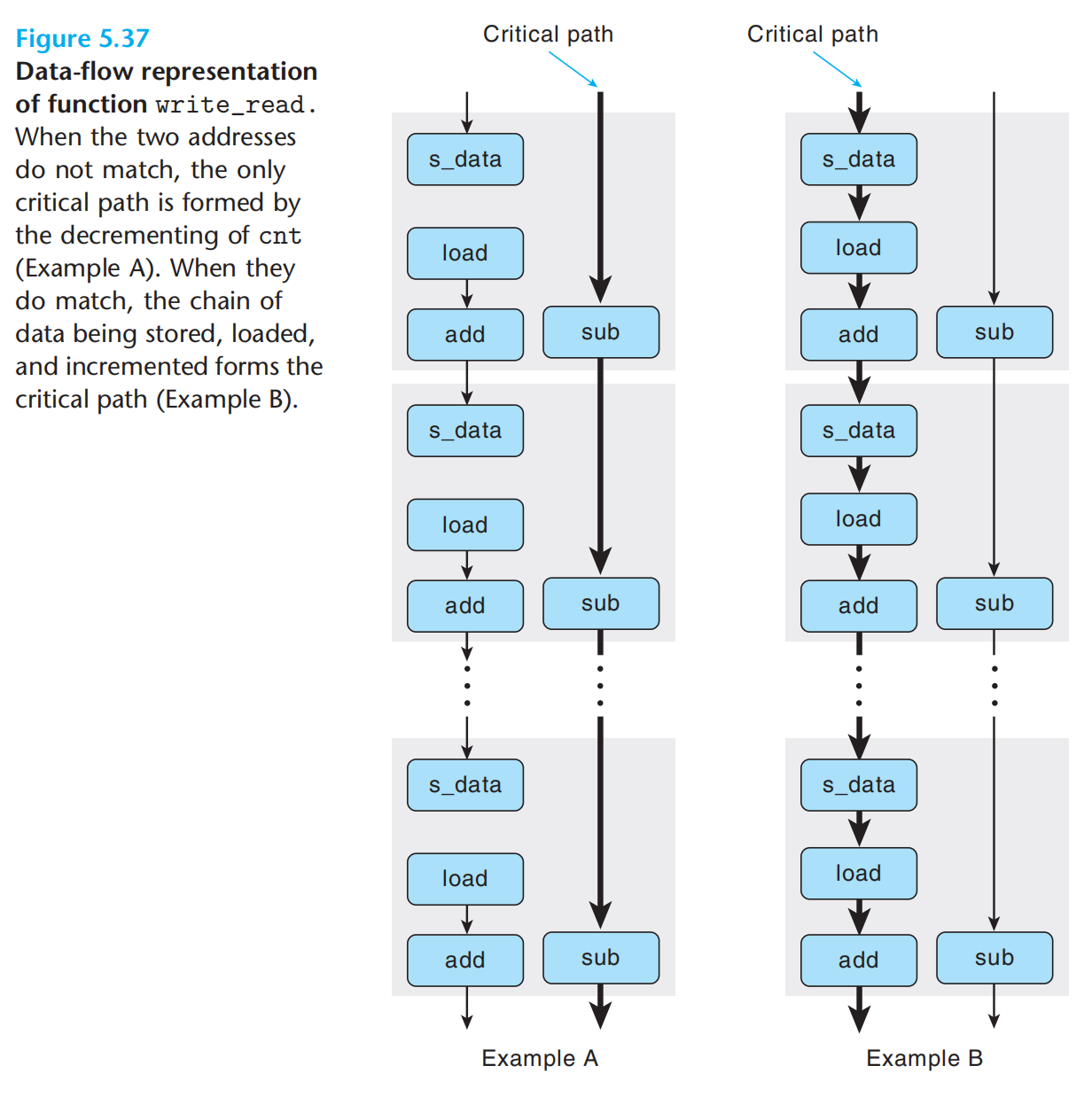
如何理解处理器的乱序并行计算与迭代中的关键路径?需要一点想象,一组有多个功能单元,每个功能单元又流水线化。寄存器重命名允许一些操作先于另外一些执行。
程序剖析
略,实战时再使用了。p388
存储器层次结构
前面我们从赋予二进制流意义到软件层面ISA的逼近,再到硬件层面对ISA的逼近(组合电路+存储设备,分阶段,再构成流水线),最后,讲述了硬件结构对软件的影响(关键路径)。此刻我们跳出了cpu,将cpu作为单纯的处理单元,开始了解存储单元。在虚拟地址空间的抽象下,我们将整个存储器层次结构视为一个完整的独立存储。
简单模型中,cpu执行指令,存储器为cpu提供指令与数据,线性字节数组,常数时间访问每个位置。
实际上:cpu-高速缓存-主存-磁盘-网络上其他设备
存储技术
1.SRAM
每个位存储在双稳态存储器单元,稳定,只要有电,永远保持他的值,访问速度仅次于寄存器。数个到数十周期。
2.DRAM
2.1dram内存芯片
每个位存储为对一个电容的充电,对干扰敏感,访问需要数百个周期。
DRAM单元:一个电容,存储一位信息
超单元:每个超单元由w个darm单元组成
超单元又被组织成r行c列的长方形矩阵,addr引脚,data引脚
RAS:行请求
CAS:列请求
RAS与CAS,共享相同的addr引脚,dram连接内存控制器,读取数据时,内存控制器先发送ras请求,将该行读入dram缓存,然后发送cas请求,读出具体的超单元,将信息通过data引脚返回给内存控制器。线性数组的方式组织超单元,会导致地址引脚增加,二维阵列的方式组织超单元,需要分两步发送地址,增加访问时间。
2.2内存模块
多个dram芯片连接到内存控制器,聚合成主存。
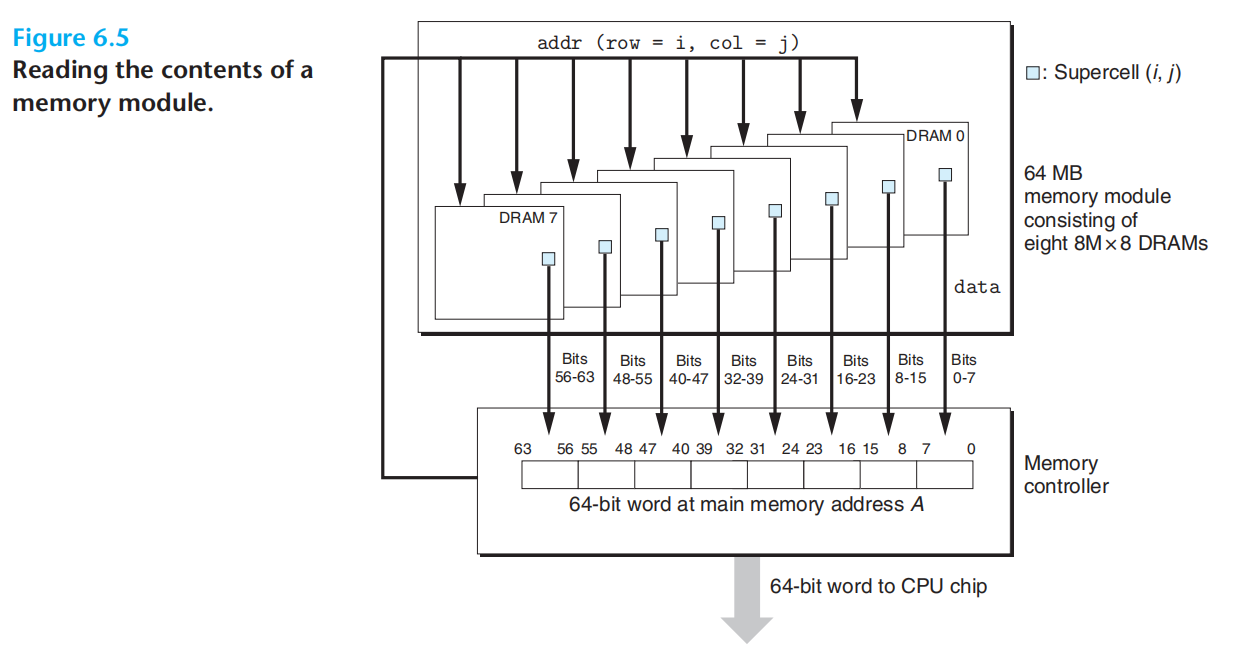
上图:每个超单元存储8位,8个dram芯片的(i,j)位置,共同存放一个64位的字。
dram,有多种增强形式:双倍速率同步ddram,原理嘛,不懂😅
3.其他一些非易失性存储器不做介绍
rom中有的类型可读,可写,不过整体上都被称作 只读存储器。存储在rom中的程序,通常被称为固件:BIOS基本输入输出,等等
4.访问主存
实际运行中的数据流:cpu - 总线(bus)- DRAM主存
总线事务:cpu与主存之间数据交互的一系列步骤统称
读事务:
写事务:
总线:一组并行的导线,可以携带地址、数据、控制信号,多个设备可以共享同一总线。
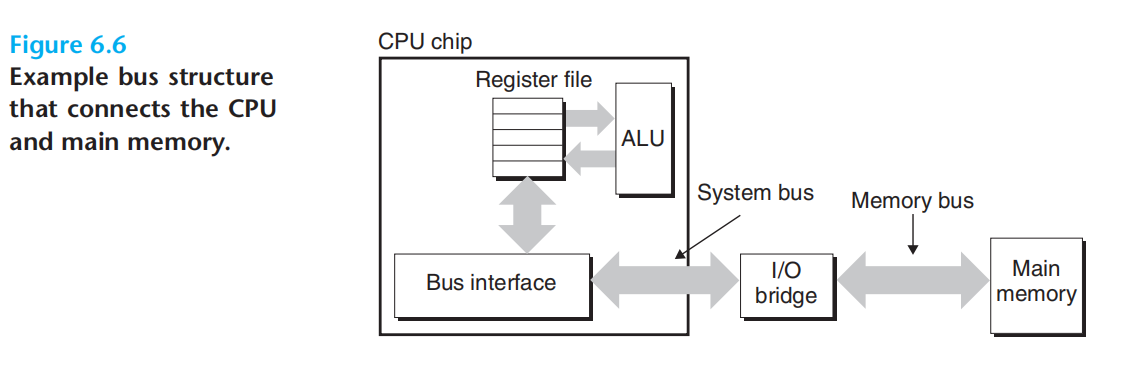
cpu中的总线接口,通过系统总线,连接io桥,io桥通过内存总线连接主存。
movq A, %rax
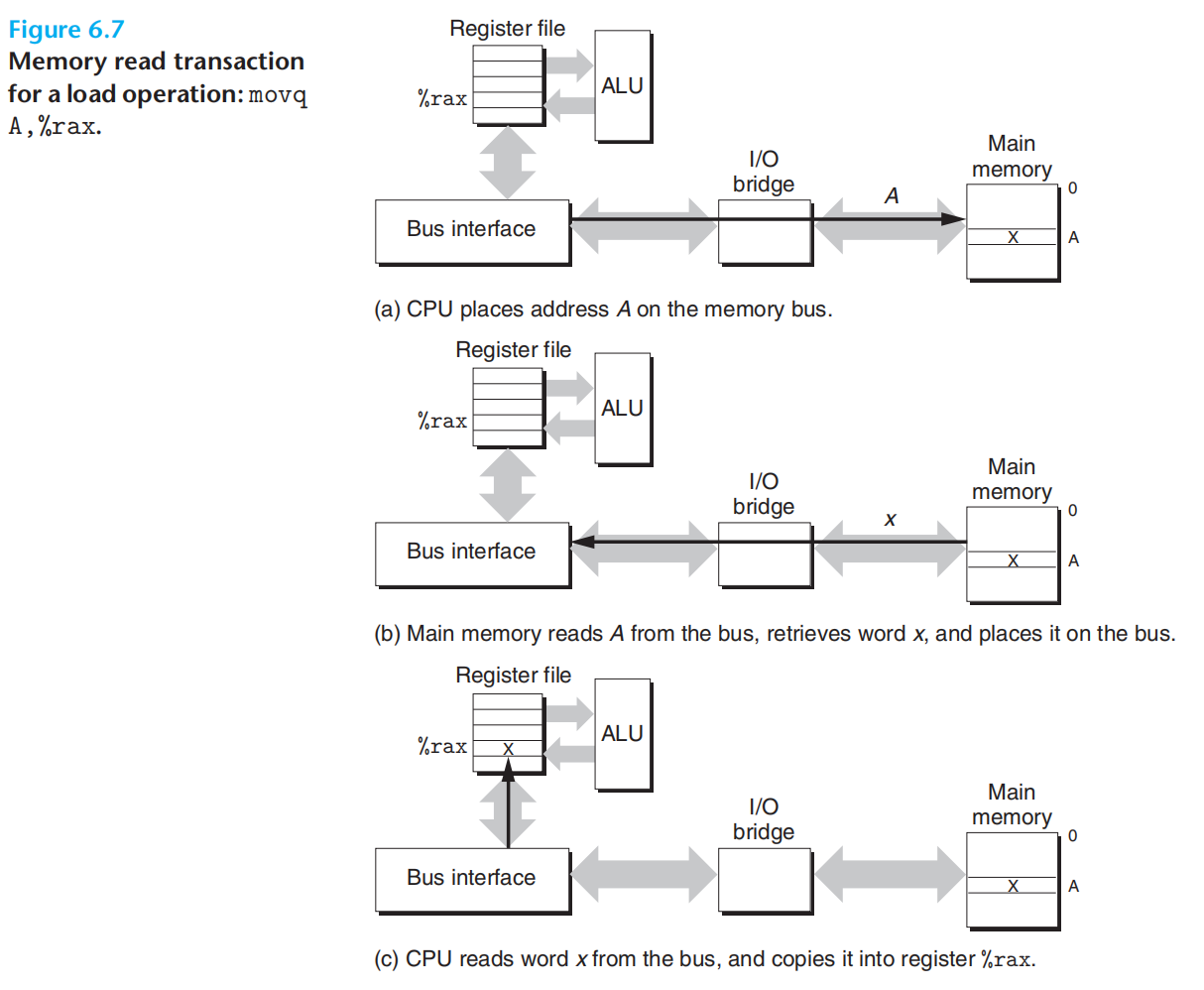
1.cpu将地址放到系统总线,io桥,信号转换,并将转换后的信号,传递到内存总线,主存感知地址信号,并将对应数据写到内存总线
2.io桥,转换信号,将数据传输到系统总线
3.cpu感知到系统总线数据,从系统总线读数据,并写到寄存器
5.磁盘
5.1物理结构
从磁盘上读取数据的时间为毫秒级,比DRAM慢10万倍,比SRAM慢百万倍
盘片platter:
表面surface:
主轴spindle:
RPM:Revolutiion Per Minute
磁道track:
扇区sector:
间隙gap:
磁盘驱动器 disk drive:
柱面cylinder:所有盘片表面到主轴中心,距离相等的磁道集合
磁盘-盘片-表面- 磁道 - 扇区&间隙;磁道+表面+盘片=柱面
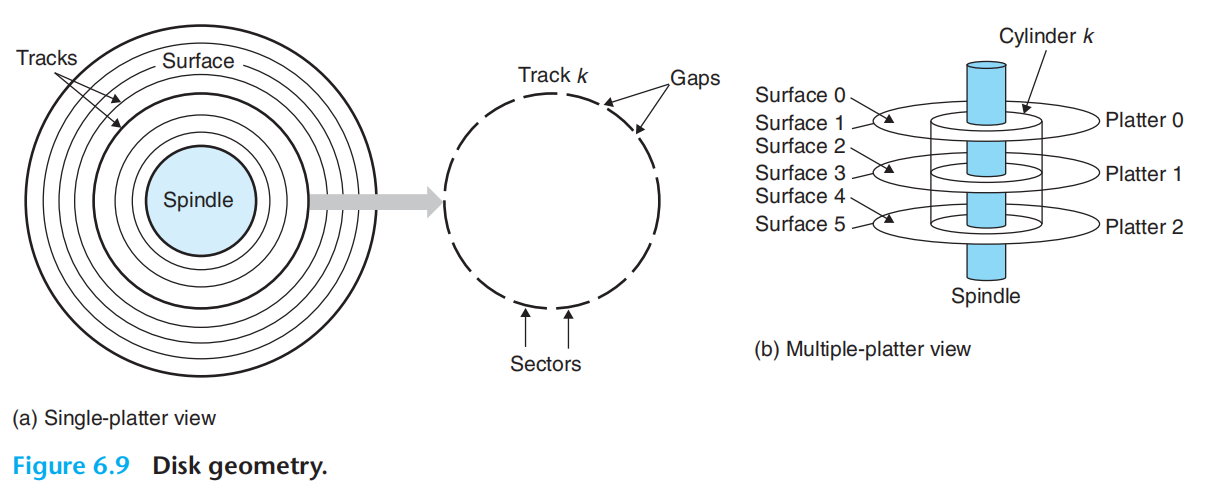
5.2磁盘容量
记录密度recording density(位/英寸):一英寸的段中可以放入的位。
磁道密度track density(道/英寸):磁盘中心出发,一英寸的段内可以有的磁道数量。
面密度areal density(位/平方英寸):记录*磁道
多区记录:柱面集合被分割成不相交的子集合,称为记录区,每个记录区,包含一组连续的柱面,每个柱面的每条磁道有相同的扇区数,由最里面的磁道的扇区决定。
note:磁盘及计算机网络中的 K M G T 以10为底,DRAM,SRAM中这是软件中的2为底
note:格式化会标识扇区信息与间隙、标识有故障的柱面、每个区中预留柱面作为备用,故格式化容量<最大容量
5.3磁盘操作
读写头,垂直排列,一致行动,任何时候位于同一柱面
对扇区访问时间:
寻道时间seek time:定位到目标磁道
旋转时间rotational time:定位到目标扇区
传送时间transfer time:读取数据的时间,扫描一个扇区的时间
主要耗时在寻道与旋转:解释了为什么要批处理,连续存储写入。
一般是:sram的数万倍,dram的数千倍
为了简化:将多个扇区,构成逻辑块,并编号,磁盘控制器维护逻辑块编号与世家物理扇区之间的映射关系(盘面,磁道,扇区)三元组。
6.访问磁盘
前面介绍了系统总线与内存总线,现在介绍io总线
io总线,负责连接鼠标、键盘、显示器、磁盘等设备
诸如PCI(Peripheral Component Interconnect 外围设备互联,pcie)等io总线,不同于内存总线与系统总线,其设计与底层cpu无关。
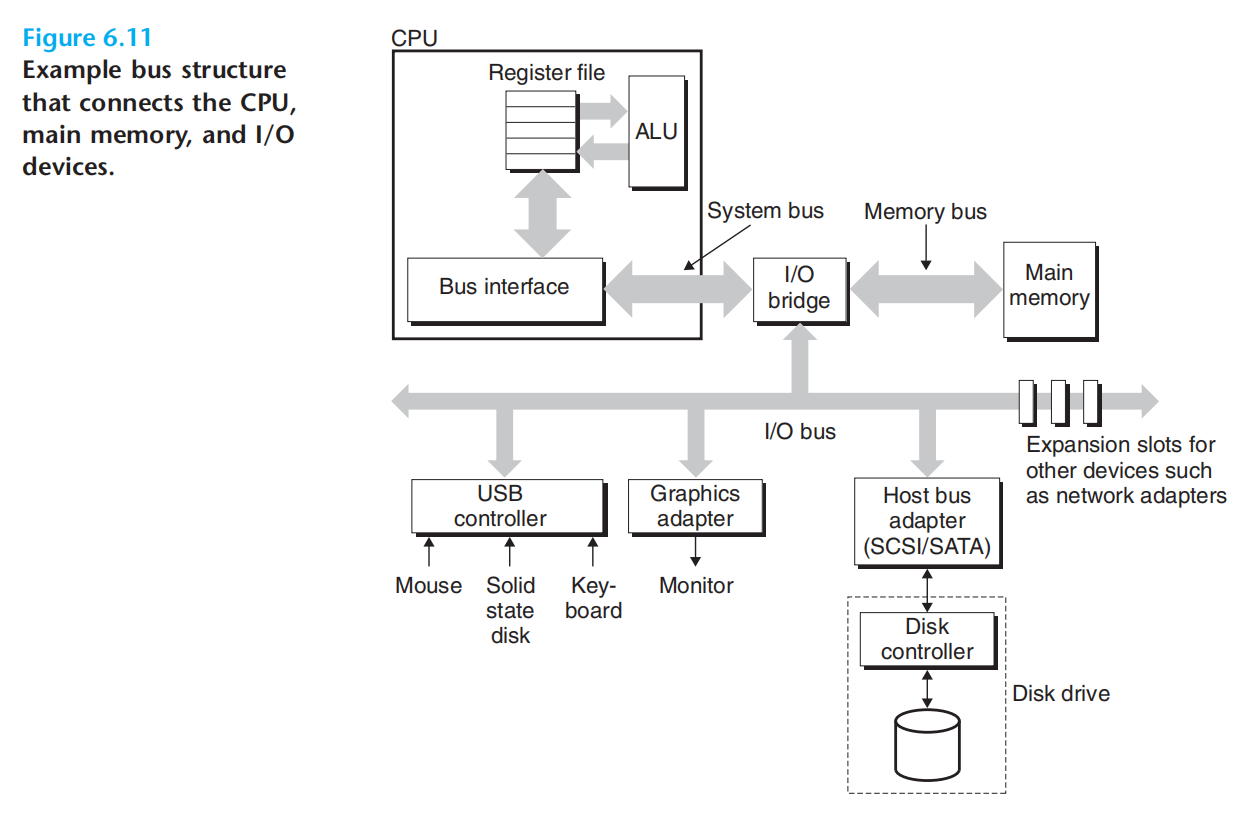
cpu使用,内存映射I/O(memory-mapped I/O)技术向io设备发送指令:
地址空间中,有一部分地址是为与i/o设备通信保留的(称为I/O端口 I/O part),当一个设备连接到总线时,便与一个或多个端口关联(被映射到一个/多个 端口)。
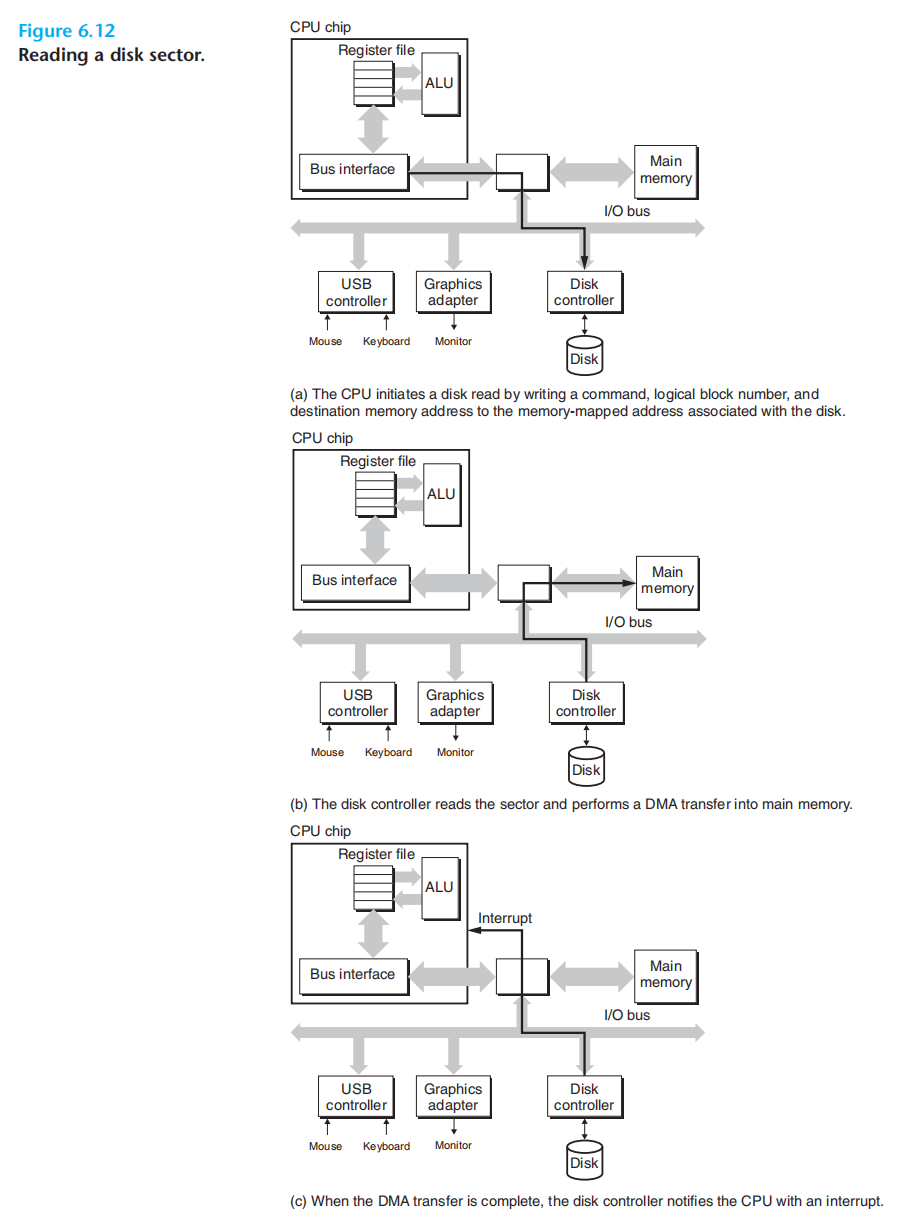
1.cpu对0xa0的磁盘发起三条指令(读命令+块编号+要存储到那个主存地址)
2.cpu开始干其他事情
3.磁盘控制器收到命令后,将逻辑好转译为扇区地址,然后读取data,并将data发送到主存(无需cpu参与,直接内存访问Direct Memory Access DMA)
4.磁盘将全部数据传送完后,给cpu发送中断信号,以便适时将控制返回到之前中断的地方
7.固态硬盘
不做过多介绍,速度比磁盘更快,读比写更快。闪存块-页 - 擦除
局部性
局部性:倾向于引用最近引用过数据项,临近的其他数据项
时间局部性:被引用过的内存位置在不久的将来,被多次引用
空间局部性:引用附近的
步长为1的引用模式:顺序引用模式
步长为k的引用模式
步长增加,空间局部性下降
- 重复引用相同变量的程序,具有良好的时间局部性
- 步长越小,空间局部性越好
- 对于指令而言,循环体越小,次数越多,局部性越好
存储器层次结构
在介绍完存储技术与软件的局部性后,作为性能与成本的平衡,存储器层次结构便产生了。
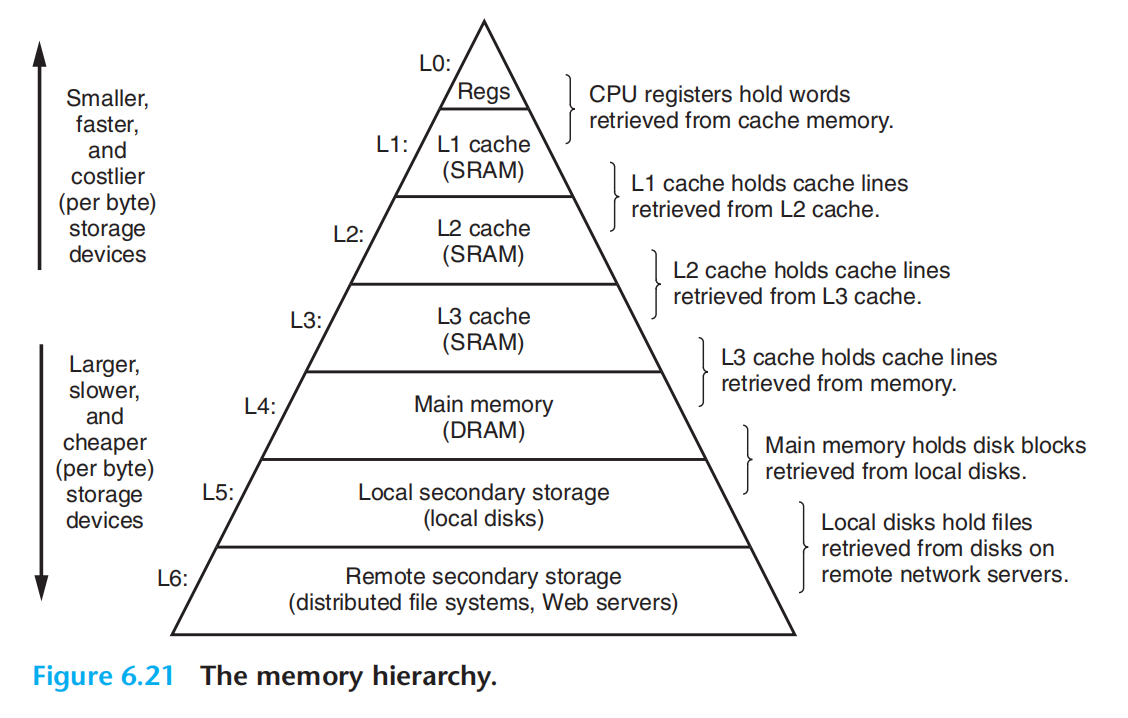
- 高层作为低层的缓存
- 数据总是以块作为传送单元在不同层来回复制,相邻层次之间块大小是固定的,不同层次之间块一般不同,越低层,访问越慢,越倾向于更大的块
缓存命中
缓存不命中:冷不命中、冲突不命中
替换策略:随机、LRU
缓存存储器
高速缓存结构描述:(S, E, B, m)
将地址,解析为:t(标记) + s(组索引) + b(块偏移)
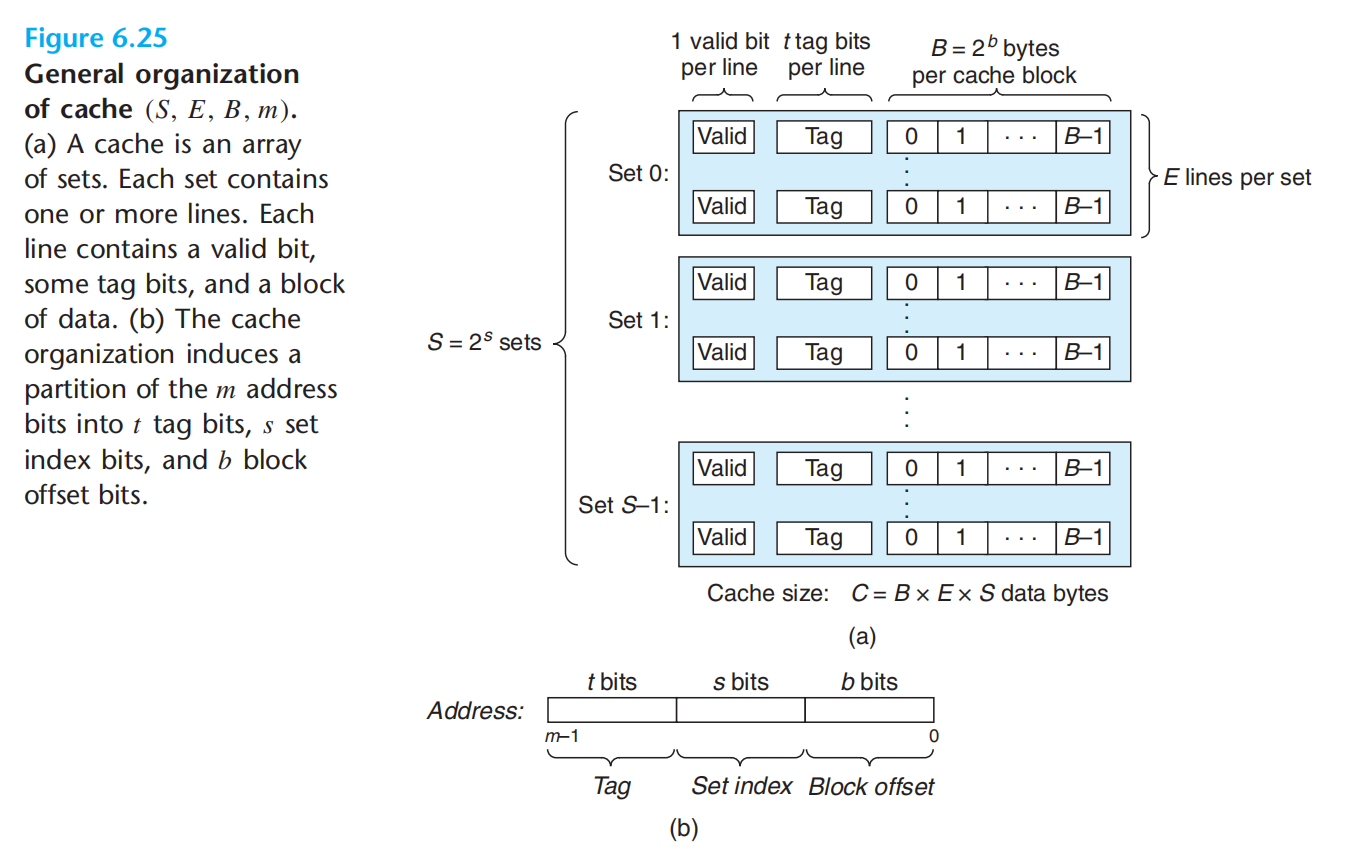

高速缓存的读取基本步骤:
- 组选择
- 行匹配
- 字抽取
直接映射高速缓存:每个组只有1行,E=1
组相连高速缓存:1<E<C/B
全相连高速缓存:E = C/B,即只有一个组
note:我们往高速缓存中,组里的行塞数据时,对象是块(缓存以块为传送单元),而块的大小由高速缓存结构定义。
关于上面三类更多细节:p425,建议一定要看下原书,在这里投入了两个晚上。
关于缓存的写(大概):
写命中:要写的内容已经存在与缓存中
1.直写:更新完缓存副本后,立即将缓存块写到底一层
2.写回:只有替换算法,要驱逐这个块时才将其写到下一层
处理写不命中:
写分配:将低一级的块加载进缓存再更新
非写分配:直接更新低一层,避开缓存
直写,通常非写分配;写回,通常写分配;作者建议:默认写回+写分配
一个现代处理器的例子:
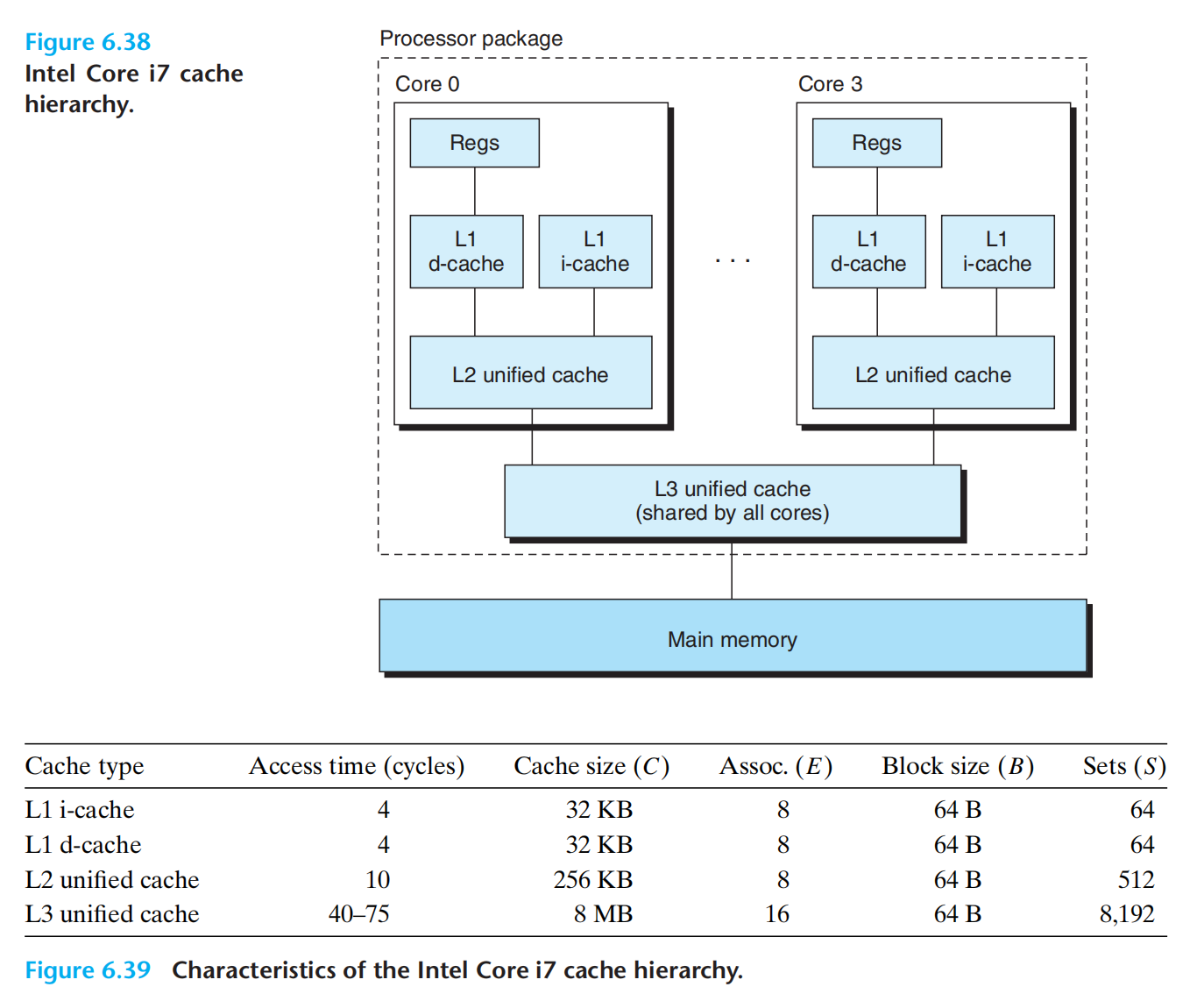
高速缓存的一些性能指标:
不命中率
命中率
命中时间
不命中处罚
容量大小:越大命中率高,命中时间越长
块大小:越大,越有效利用空间局部性,命中率越高,传输时间越长,不命中处罚越高,行数越少,不利于时间局部性
行数:越多,增加命中时间,增加不命中处罚
缓存友好代码
如前所述,局部变量反复利用,步长越小越好(步长与前面的循环展开)