操作系统上的程序
链接
前面讲了一个完整的程序在执行时与硬件的交互,现在开始程序运行与系统的交互。
实际的程序编写中,总是会引用其他部分的代码,如何将我们编写的引用了其他模块的独立文件,变成最终在内存中包含了所有执行所需信息的最终独立可执行文件?–链接!
java中不涉及链接,或者说有类似的东西,叫类加载器。在csapp之前,我是完全不知道链接这个概念。
链接:Linking is the process of collecting and combining various pieces of code and data into a single file that can be loaded (copied) into memory and executed.Linking can be performed at compile time, when the source code is translated into machine code; at load time, when the program is loaded into memory and executed by the loader; and even at run time, by application programs. On early computer systems, linking was performed manually. On modern systems, linking is performed automatically by programs called linkers.
分离编译:允许修改并编译一部分,然后链接到已有程序上。
共享库:
动态链接:
编译器驱动程序
gcc -Og -o prog main.c sum.c
编译驱动程序(gcc为例,源文件main.c):
- cpp:c预处理器,翻译成ascii码中间文件:main.i
- cc1:c编译器,翻译成ascii码汇编文件:main.s
- as:汇编器,翻译成可重定位目标文件:main.o
- 链接器,链接main.o & sum.o 生成目标可执行文件
静态链接
可重定位目标文件 + 命令行参数 -> 可执行目标文件
可重定位目标文件:代码 + 数据节
数据节:每一节都是一个连续的字节指令;指令在一节中,初始化了的全局变量在另一节,未初始化的变量又在另一节。
- 符号解析:函数/全局变量/静态变量
- 重定位:编译器和汇编器生成从位置0开始的代码和数据节,链接器把符号与位置关联起来,从而重定位这些节。然后修改所有对这些符号的引用,使其指向关联的内存位置。
目标文件
- 可重定位目标文件:链接时与其他可重定位目标文件合并,生成可执行文件。
- 可执行目标文件:可以直接复制到内存并执行。
- 共享目标文件:可在加载/运行时,被动态加载进入内存,并链接。
各系统目标文件不一致
可重定位目标文件
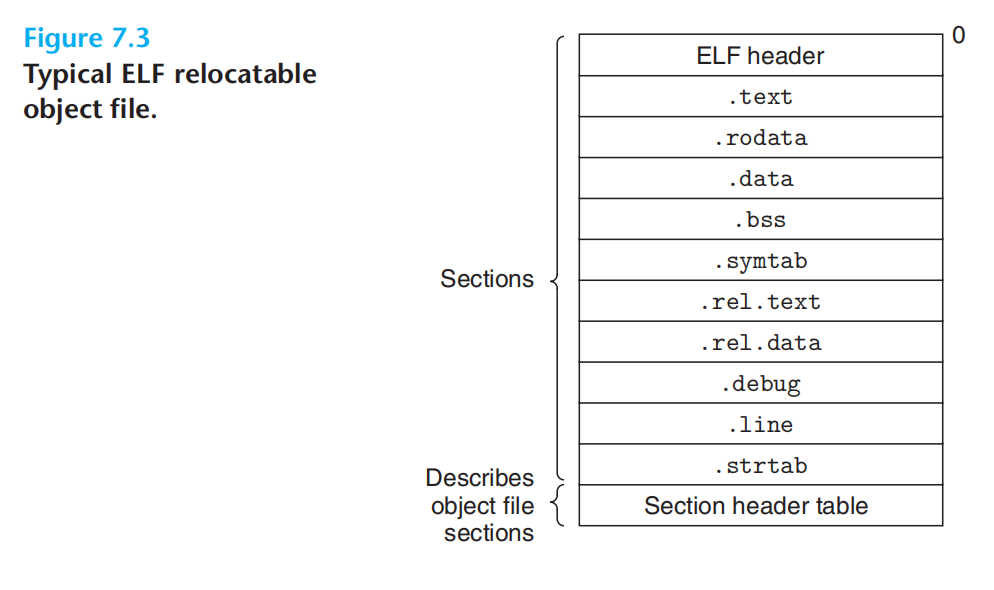
section:节
上图:elf 可重定位目标文件
#生成汇编
gcc -Og -S main.c
#生成目标文件
as -o main.o main.s
#查看目标文件
readelf -a main.o
c中的static:
1.局部static变量:静态区存储(非stack),只被初始化一次,方法结束后也不销毁,程序结束才销毁。
2.全局static变量/函数:类比java private。表明模块私有。
符号表(.symtab):
- 本模块定义并能被其他模块引用的全局符号。全局链接器符号:全局函数与变量(非静态)
- 其他模块定义,被本模块引用的全局符号。外部符号:其他模块的全局链接器符号
- 本模块定义与应用的局部符号。static修饰的符号与变量
定义在函数内部的局部变量,当然是运行时存放在stack中了,链接器对其不感兴趣。
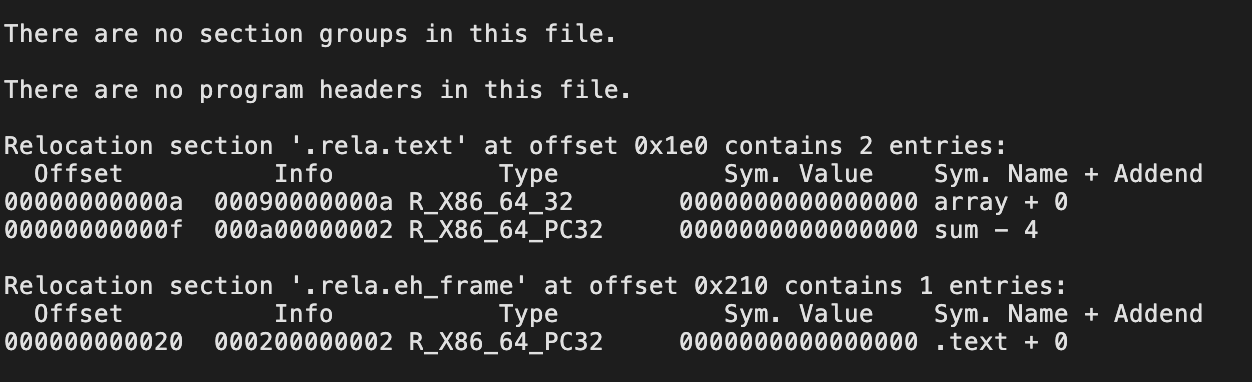
readelf -a main.o中符号表的部分:
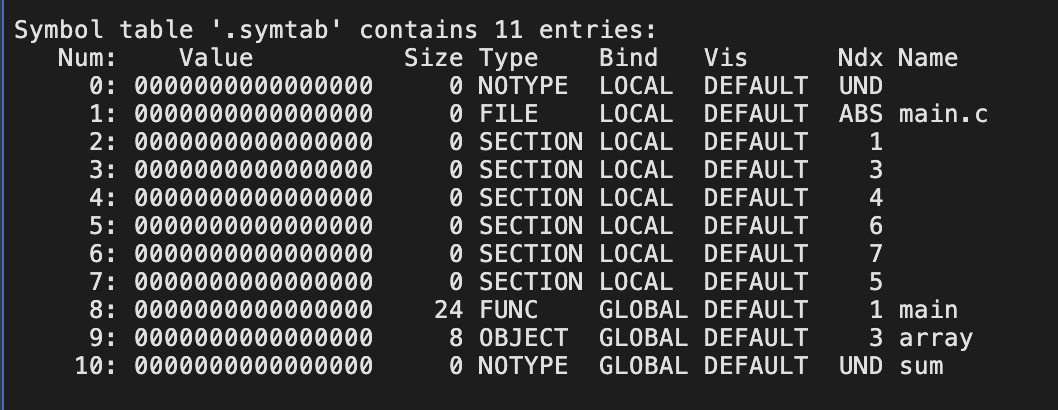
符号表The value is the symbol’s address. For relocatable modules, the value is an offset from the beginning of the section where the object is defifined. For executable object fifiles, the value is an absolute run-time address
8:main符号,位于1(.text节)偏移量为0的24字节func
9:array符号(定义在本文件的数组),位于3(.data节),偏移量为0的8字节object
10:sum符号,und(未定义的符号),notype。
目标文件 – 节 – 符号表 1.符号引用;2.符号定义
上面的8、9就是符号定义,而10则是符号引用。
符号解析
现在我们开始进入链接器真正重要的部分了
符号解析就是,将可重定位文件 中的所有符号引用与对应的符号定义关联起来。how?
对于局部符号或是静态局部符号的处理细节,暂时先不关心。
在诸多的输入文件中,确定全局符号的定义:
1.没有该定义
2.存在多个定义
linux 链接器使用如下规则处理多个定义:
At compile time, the compiler exports each global symbol to the assembler as either strong or weak, and the assembler encodes this information implicitly in the symbol table of the relocatable object fifile. Functions and initialized global variables get strong symbols. Uninitialized global variables get weak symbols.
Given this notion of strong and weak symbols, Linux linkers use the followingrules for dealing with duplicate symbol names:
Rule 1. Multiple strong symbols with the same name are not allowed.
Rule 2. Given a strong symbol and multiple weak symbols with the same name,choose the strong symbol.
Rule 3. Given multiple weak symbols with the same name, choose any of the weak symbols.
多个不同类型的弱定义/强弱结合,会产生意外的情况:污染其他定义。
注意联系7.2!
静态库:把模块打包成单独的文件。
当静态库作为输入时,链接器只会复制被引用的模块。
不使用静态库:
1.识别标准函数,编译器生成
2.所有标准函数打包成一个可重定向目标文件
自己构建库:
gcc -c addvec.c multvec.c
ar rcs libvector.a addvec.o multvec.o
#链接 库 编译
linux> gcc -c main2.c
linux> gcc -static -o prog2c main2.o ./libvector.a
#or
linux> gcc -c main2.c
linux> gcc -static -o prog2c main2.o -L. -lvector
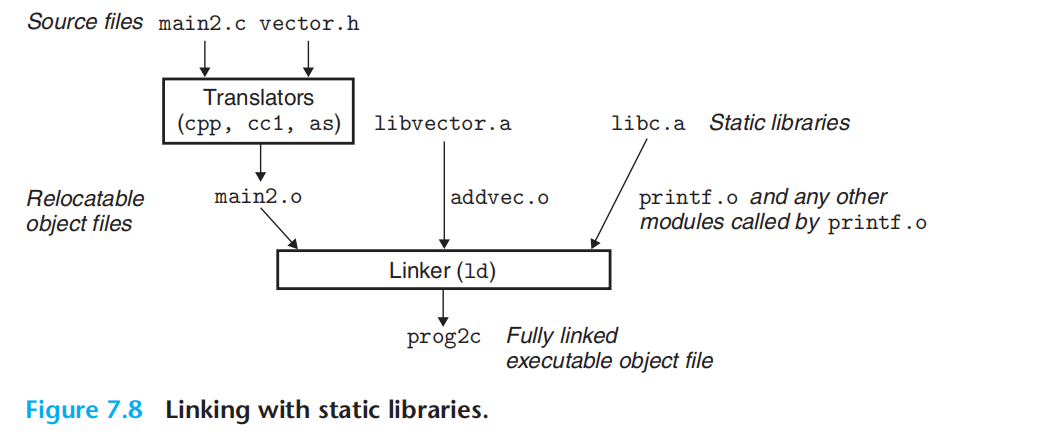
链接器使用静态库:
E:可重定位目标文件
U:未解析的符号
D:已被先前文件定义的符号
- For each input fifile f on the command line, the linker determines if f is an object fifile or an archive. If f is an object fifile, the linker adds f to E, updatesU and D to reflflect the symbol defifinitions and references in f , and proceeds to the next input fifile.
- If f is an archive, the linker attempts to match the unresolved symbols in U against the symbols defifined by the members of the archive. If some archive member m defifines a symbol that resolves a reference in U, then m is added to E, and the linker updates U and D to reflflect the symbol defifinitions and references in m. This process iterates over the member object fifiles in the archive until a fifixed point is reached where U and D no longer change. At this point, any member object fifiles not contained in E are simply discarded and the linker proceeds to the next input fifile.
- If U is nonempty when the linker fifinishes scanning the input fifiles on the command line, it prints an error and terminates. Otherwise, it merges and relocates the object fifiles in E to build the output executable fifile.
f:目标文件就更新u&d,库就将与u中匹配的目标文件添加到e,同时更新u&d,遍历结束,排除库中不在e的其他文件
这个算法会导致顺序问题。先库,后目标文件,就一定会报错。
完成符号解析后,符号定义与符号引用就建立起了关联。同时也确定了输入目标文件的所有代码节与数据节的大小了。开始重定位处理。
重定位
目的:合并输入模块,为每个符号分配运行时地址。
- 重定位节&符号定义:将所有的相同类型节合并成一个,同时给里面的所有指令&所有全局变量分配唯一的运行时地址。(此时非配的是全局变量的定义,其他代码中的全局变量的引用还未处理)
- 重定位节中的符号引用:现在才将所有的符号引用替换成前面分配的运行时地址。此步骤依赖于「重定位条目」数据结构
重定位条目:
生成目标文件时,汇编器并不知道指令与数据的运行时内存,当遇到符号引用时,就会生成重定位条目,存放于.real.text/.real.data中
readelf -a main.o
R_X86_64_PC32:重定位一个使用32位pc相对位置的引用;pc计数器:一般是下一条指令的地址,pc相对地址:距离当前位置的偏移量。有效地址=当前pc值 + 32位偏移量
R_X86_64_32:重定位一个32位绝对地址的引用。
上述两种类型:支持x86_64的小型代码模型(代码+数据 < 2GB);
结构:

objdump -dx main.o
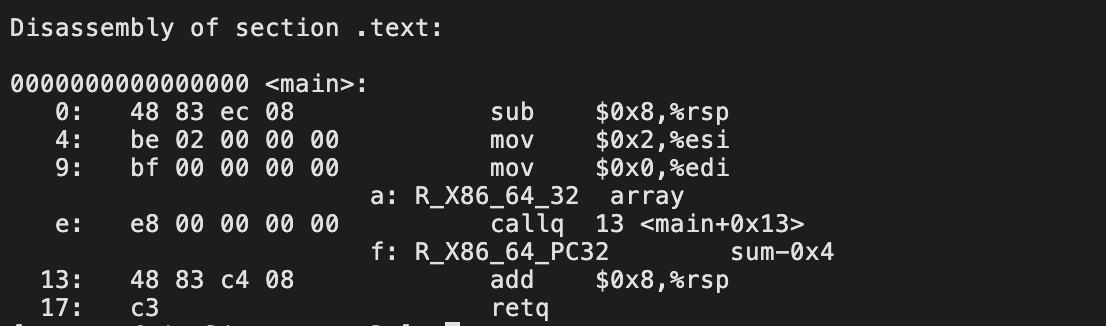
重定位计算算法:

refaddr:要修改的代码的地址
*refptr:那个地址的值
相关例子见书中p481
1.我们生成了可重定位目标文件
2.对其进行链接(符号解析+重定位(节与符号定义 + 符号引用))
3.现在我们得到了可执行目标文件(可以直接加载到内存中进行执行的代码)
可执行目标文件
gcc -Og -o exec main.c sum.c
objdump -x exec
相关文件信息及头部表内容见p483,(我并不认为我会记住这个…)
加载可执行文件
这一部分的内容有必要详细一点,对理解java的类加载机制很有价值。
./ exec
- exec 不是系统内置,shell 会认为exec是可执行目标文件
- 调用驻留在主存中的加载器(操作系统代码)来运行该代码,linux系统可通过调用execve函数来调用加载器
- 加载器将代码与数据复制到内存,然后跳转到程序的入口点
加载:上述将程序复制到内存并运行的过程
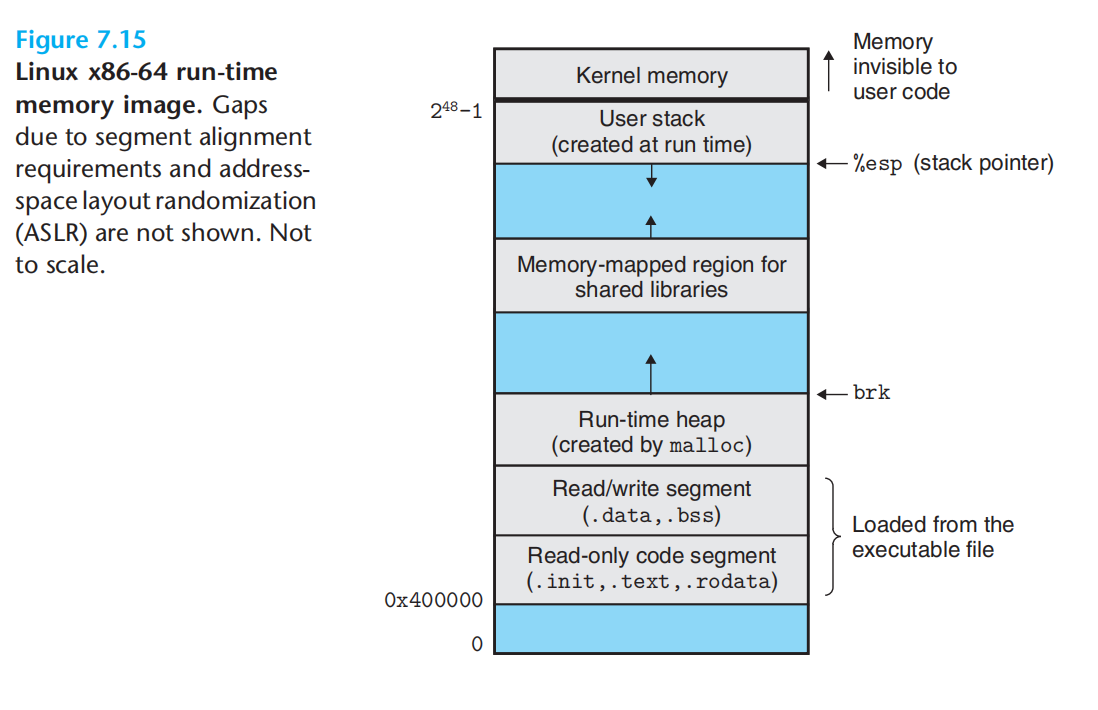
加载器运行:
1.创建类似上图的内存结构
2.将可执行文件的chunk 复制到代码段&数据段
3.跳转到程序的入口点(_start函数地址,系统目标文件ctrl.o中定义,所有c均是该函数)
4._start invoke __libc_start_main(libc.so) 初始化执行环境,调用main函数,处理main函数返回值,必要时把控制交给内核
动态链接共享库
前面介绍了静态库的链接算法。
使用静态库有如下两个主要缺点:
1.库更新后需要重新链接
2.几乎每个进程都会在内存保有printf之类的代码片段
共享库:目标模块,运行或加载时可加载到任意内存地址,并和一个在内存中的程序链接起来。linux:.so;windows:.dll
动态链接,动态链接器,共享目标。
共享:
1.一个文件系统中,一个库只有一个.so文件,所有引用共享。
2.共享库的.text节的一个副本,可被多个进程共享。
#生成共享库
gcc -shared -fpic -o libvector.so addvec.c multvec.c
#链接共享库
gcc -o prog2l main2.c ./libvector.so
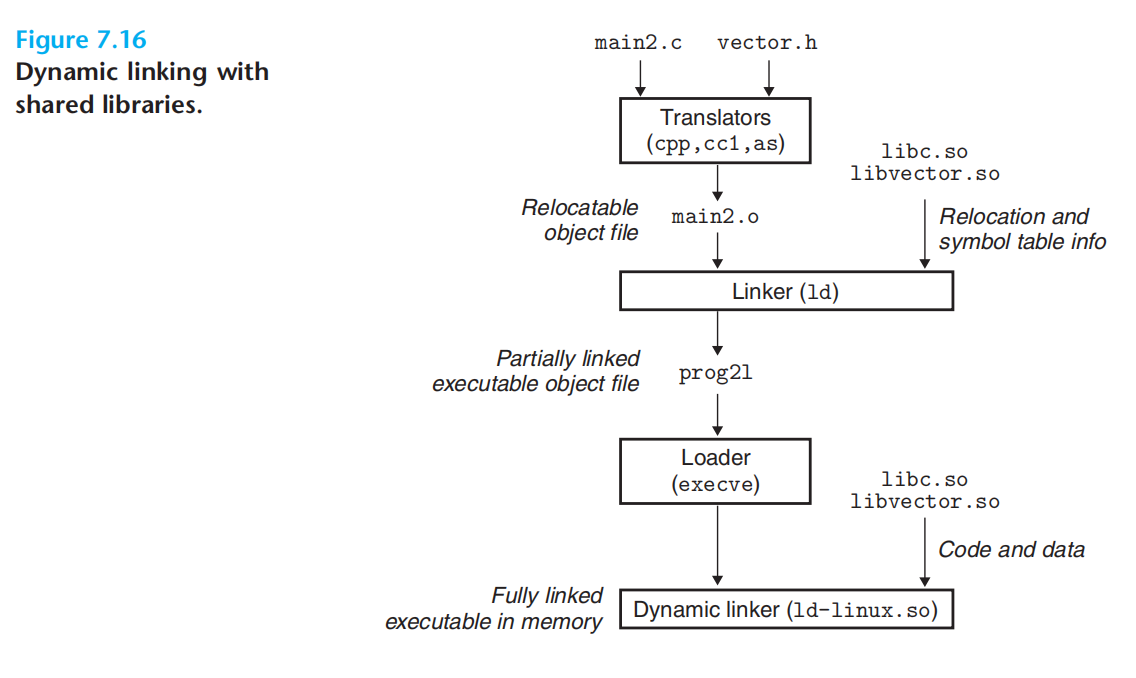
编译时,链接器生成一些重定位符号表
加载器运行时再执行动态链接器,内存中生成完整的可执行代码。
上面描述的是应用程序在运行前的链接,引用程序还可以在运行中加载并链接某个共享库,运行时,不停止就可以更新某个已存在的函数。
linux相关接口具体使用见p487;
java的本地接口。
多个进程是如何共享程序的一个副本的?
为何需要位置无关?:如果需要编译时提前确定位置,我们需要将共享库提前全部加载进内存,即使其可能不会被使用。
位置无关代码:可以加载而无需重定位的代码 gcc -fpic 编译。共享库就是。(Position-Indenpendent Code)
所有需要用到共享库的地方,都存放一个固定的指针,而指针具体指向哪里?运行时动态链接来确定。
1.PIC数据引用:任何目标文件的代码段与数据段,之间的偏移量是一个常量。在代码段中引用了一个全局变量,但我们只能在运行时才能确定全局变量的具体地址,故链接时,我们标明该全局变量对应的GOT表中的该项距离代码段的相对位置,而GOT中该项的具体值则是运行时动态链接器去维护。a变量为GOT表的第四项GOT[3],GOT[3]距离代码的固定偏移量是0x12345,而GOT[3]指向的具体地址,运行时动态链接器再确定。
2.PIC函数引用:如果对函数的应用也使用上述方法,则需要动态链接时修改调用处的代码,就不是PIC了,实际中采用延迟绑定
PLT条目:16字节代码
GOT与PLT之间的交互:第一次运行时通过指令将目标函数地址,初始化到GOT中,后续直接调用GOT中地址的函数即可。
库打桩
linux链接器,允许截获对共享库的调用,取而代之执行自己的方法。
编译时打桩:需要源码
链接时打桩:需要可重定位目标文件
运行时打桩:需要可执行文件
异常控制流
程序从开始到结束,计数器值构成一个序列,从一个地址到另一个地址的过度,就是控制转移。这个控制转移序列就是处理器的控制流。
exceptional control flow (ECF):控制流中的异常突变。诸如:进程切换。
从cpu的视角,程序计数器从一个一部分跳转到另一个几乎不相关的部分。把控制交给另外的部分。
对系统状态变化的响应,语言的异常处理只是其一个使用例子(try catch 形式提供的应用级ECF)。
异常
异常:控制流中的突变,用来响应处理器状态的变化,一部分由硬件实现,一部分由操作系统实现。有“硬件” 与 “软件”之分。
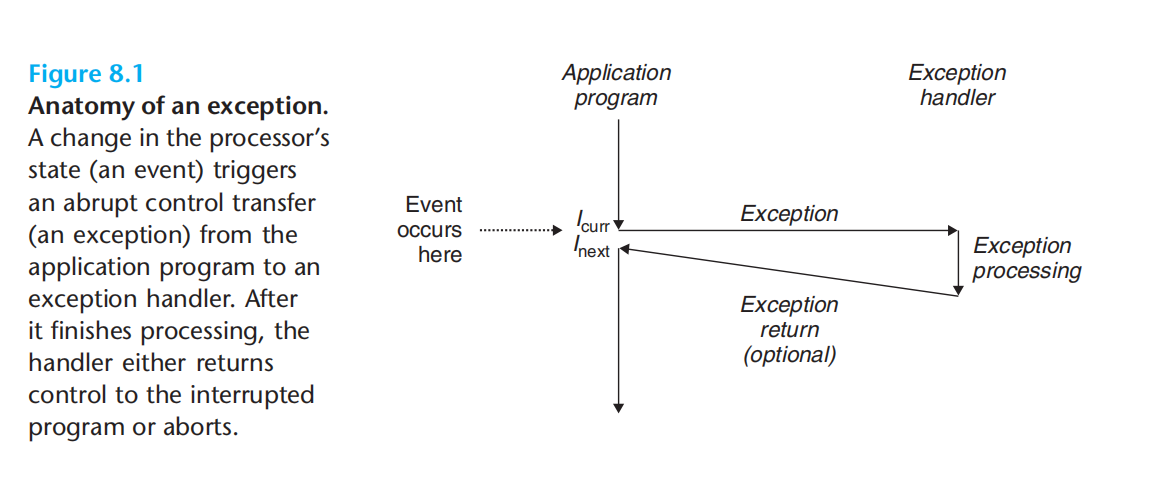
事件 – execption table – execption handler –next
1.i(curr)
2.i(next)
3.终止被中断的程序
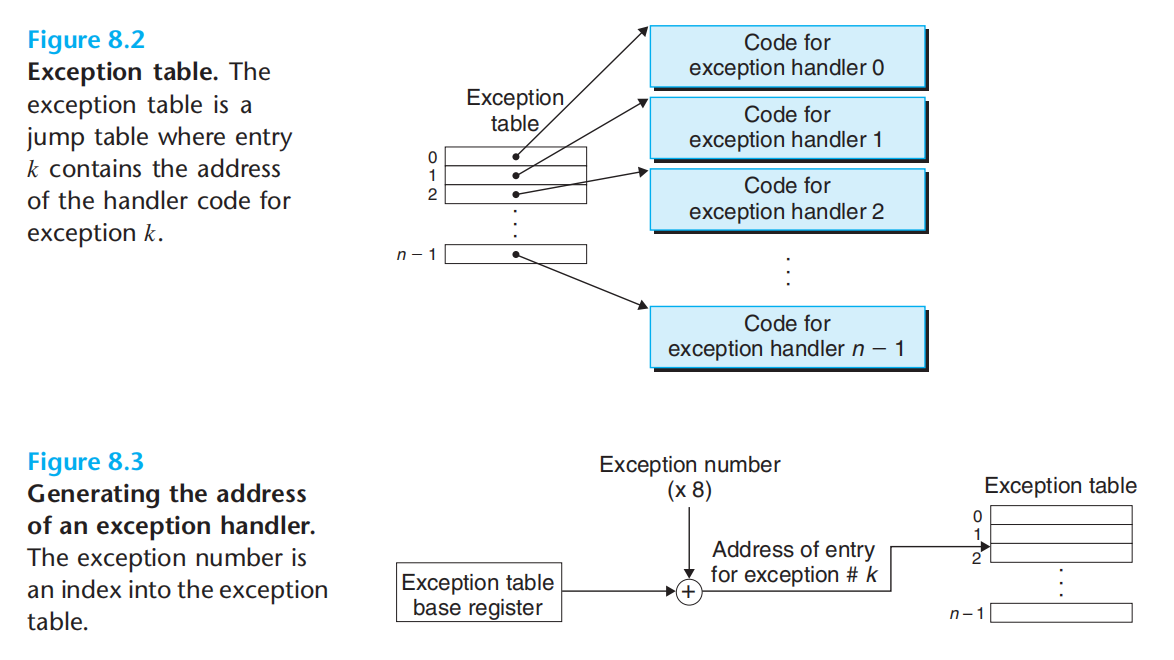
异常类型 对应 异常号(处理器占一部分+操作系统占一部分),异常号去异常表(指明异常处理程序)中找接下来的执行程序。异常表起始地址存放于异常表基址寄存器。
类似过程调用,但 返回地址,用户栈与系统栈,访问权限 有所不同。硬件触发了异常后,剩余工作异常处理程序在软件中完成。
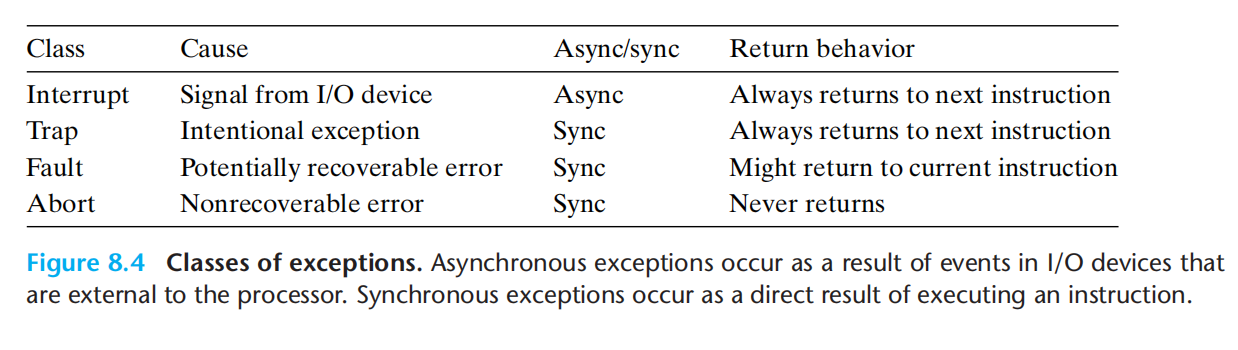
异常分类:
中断、陷阱、故障、终止
异步:来自外围IO设备
同步:来自指令执行的直接产物,故障指令
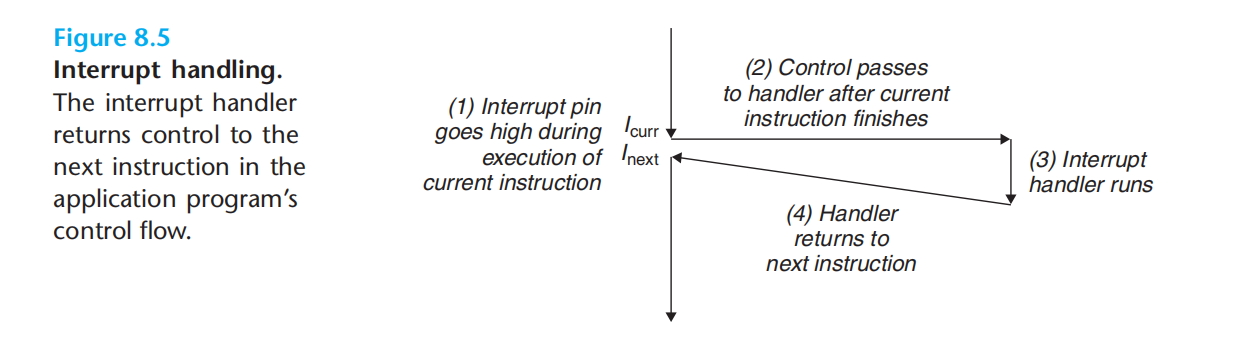
interrupt:
trap:例子:系统调用(syscall n)
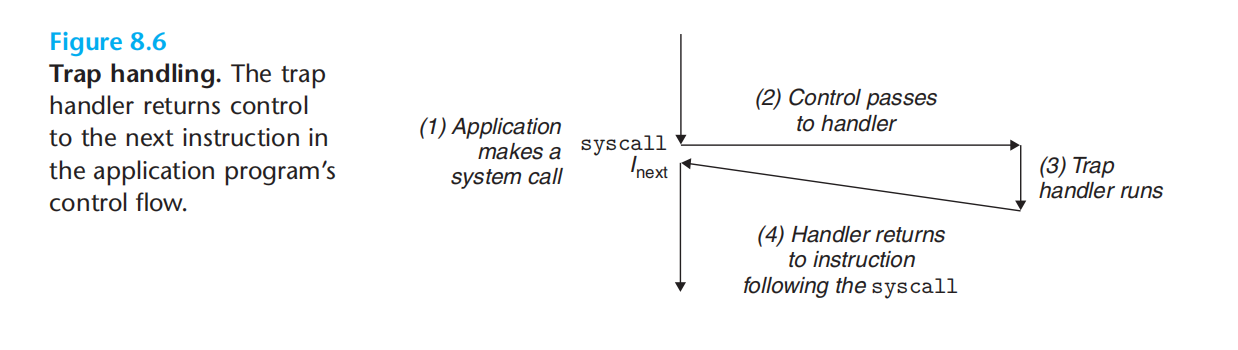
程序员视角:系统调用与普通的函数调用是一样的,实际差异:
1.函数 用户模式 限制了指令类型;系统调用内核模式,允许特殊指令。
2.函数 访问与调用函数相同的栈;内核模式,可以访问定义在内核的栈。
fault:例如 执行指令发现缺页,会执行异常处理加载后再执行该指令
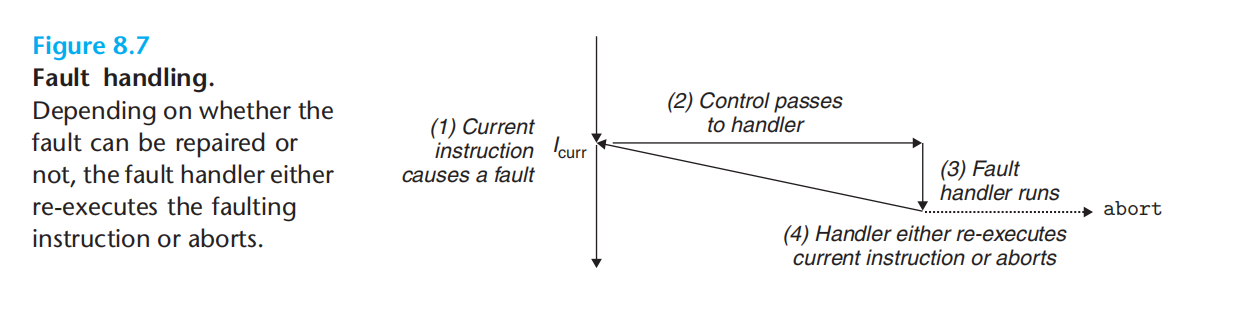
abort:
系统调用,跳转表,系统级函数
进程
进程:一个执行中的程序实例。每个程序都运行在某个进程的上下文中,context:程序正常运行所需的状态集合。
进程提供的关键抽象:
1.一个独立的逻辑控制流
2.一个独立的地址空间
逻辑控制流
并发流与并行流
私有地址空间,每个进程都是如此,即使两个进程的虚拟地址相同,它们对应的物理地址也可能不同
用户模式与内核模式,linux提供/proc文件系统,可以让用户模式的进程访问内核数据。
上下文切换:1.保存当前进程上下文,2.恢复被抢占进程被保存的上下文,3.控制传递给新的进程
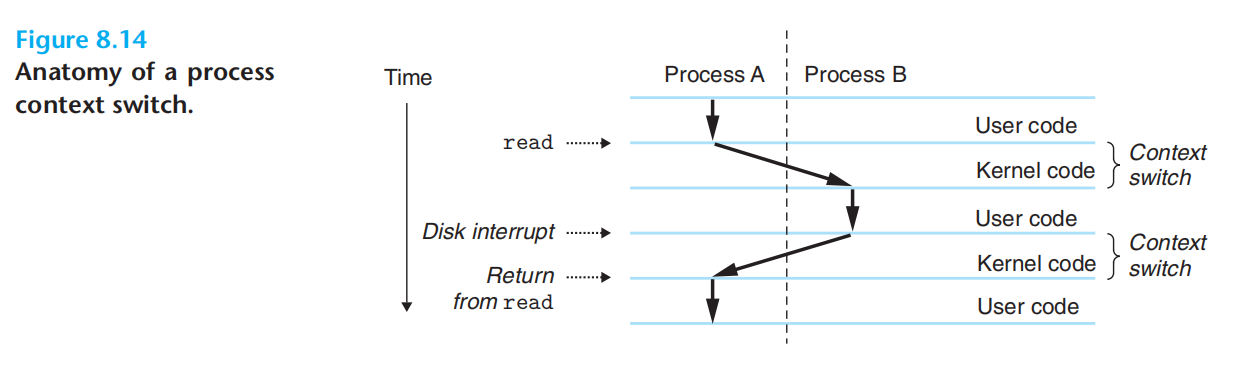
调用系统函数遇到错误,一般是创建对应的包装函数来提示错误。
进程控制
描述了一些操作进程的系统函数。p513
getpid(void);
getppid(void);// parent pid
//进程3个状态1.运行;2.停止;3.终止
//0 正常退出,非0表示异常或错误
void exit(int status);
//创建进程
pid_t fork(void);
//已终止还未被回收:僵死进程zombie
//init进程成为孤儿进程的养父
//回收子进程
//父进程 等待特定的子进程,全部终止后会设置erron= ECHILD
pid_t waitpid(pid_t pid, int *statusp, int options);
//休眠
unsigned int sleep(unsigned int secs);
//函数执行
int exec(const char *filename, const char *argv[], const char *envp[]);
char *getenv(const char *name);
int setenv(const char *name, const char *newvalue, int overwrite);
void unsetenv(const char *name);
信号
linux信号:允许进程&内核,中断其他进程。一条消息,告知进程,系统中发生了某些事件。
信号是操作系统内核在特定事件(如子进程终止)发生时生成的,并通知给父进程。
为每个进程维护pending向量位与black向量位,因为是向量,所以决定了每个进程相同类型的信号,只能存在1个,超出的部分会被丢弃,即信号不会排队。当我们受到某个信号时,我们唯一能获取的信息便是:系统中某个产生信号的事件至少发生了一次。
传送一个信号到目的进程:
- 发送信号:
- 内核检测到系统事件
- 调用kill函数,要求内核给目的进程发送一个信号
- 接收信号:目的进程被内核强迫对信号作出反应时,它就接收了信号
- 可以忽略
- 可以终止
- 可以执行 信号处理程序
- 待处理信号:发送了还没接收
- 一种类型,只能最多有一个待处理信号
- 进程可以选择性的阻塞接收某类型信号
- 一个待处理信号最多也只能被处理一次
内核为每个进程维护:pending位向量 & blacked位向量
当进程从内核模式切换到用户模式时,会检查该进程未被阻塞的待处理信号集合,非空则从中选取某个信号强直进程接收。
- 进程终止
- 进程终止并转储内存
- 进程停止,直到SIGCONT信号
- 进程忽略该信号
接下来便是一些api示例与进程的并发,因为上一个周末没有去图书馆,打了一天游戏,最近比较怠惰。这一部分还是放在shell实验里面了。虽然怠惰,但毕竟已经于昨天发生了,而我已不再拥有昨天了,so,调整心态,准备这新的一周。避免完美主义毁掉更多的时间!
虚拟内存
20241006,国庆假期的倒数第二天,9点十分左右到图书馆,自习室近乎满人了,比较舒服的位置均已被占,不过今天也将会被赋予一点特殊的意义:初步完结csapp!向着胜利冲锋!
一般,当你对某个资源进行虚拟化,通常是为了以另一种视图展示,实现的方式则是对访问过程的介入。
- 将主存,看作磁盘的缓存。
- 为每个进程,提供了一致的地址空间,简化内存管理
- 保护了进程的地址空间,不被其他进程破坏
物理寻址与虚拟寻址
物理寻址physical addressing:
将主存视为m个字节的数组,每个字节有唯一地址。
虚拟寻址virtual addressing:
虚拟地址,通过mmu(内存管理单元)翻译成物理地址(操作系统+cpu硬件)。
地址空间:一个整数集合,通过最大数的bit位数来描述,注意区分bits & address,主存中的每个数据,都有一个来自虚拟地址空间的虚拟地址,和一个来自物理地址空间的物理地址。
虚拟地址空间:一个非负整数集合,每个进程都有自己的页表,因而就是独立的虚拟地址空间
物理地址空间:对应darm?
数据-1物理地址-n虚拟地址
无论是虚拟地址空间还是物理地址空间,都是对磁盘空间的抽象,其中,物理地址空间有唯一的一个,而虚拟地址空间则每个进程都有一个,当进程说,我需要从虚拟地址x对应的位置读取1字节数据,实际上说的是我需要从磁盘上物理地址x‘处开始读取1字节。这个过程中我们会将x’所在的页从磁盘加载进主存,然后从主存中加载进入更高一级缓存,直至cpu。虚拟内存-缓存
虚拟内存所划分的对象是磁盘,而非主存。主存作为缓存使用。页作为缓存之间的传输单元。
虚拟页:虚拟内存进行分割所得
物理页(页帧):物理内存…
虚拟页集合=未分配 + 缓存的 + 未缓存的
虽然虚拟地址是对磁盘的划分,但其并不是从一诞生就立刻与物理地址存在映射。故作为对虚拟地址再划分的虚拟页,也就有了未分配这一状态了。
darm 是全相连的,只有一个组。
磁盘的构造决定了随机读远慢于顺序读,故页的大小一般较大。
页表-页表条目 page table entry:有效位+地址(未分配=null,已缓存=物理地址,未缓存=磁盘中的起始位置)
虚拟地址决定了我们需要读取页表的那一个页表条目,而页表条目的有效位决定了该页是否存在于缓存,页表条目的地址决定了该虚拟地址对应的物理地址。
页的三种情况,详情见p563
未命中
缺页
分配新的页虚拟内存-内存管理
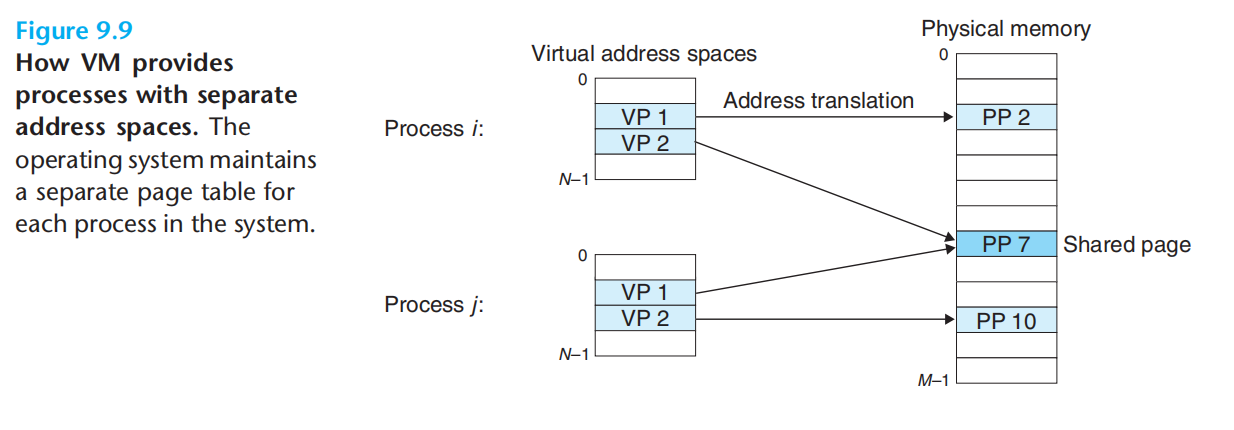
每个进程有一个独立的页表,每个进程也就独占一个完整的虚拟内存空间,极大的简化了内存管理。内存-内存保护
在PTE添加额外许可位,增强功能。

地址翻译


p位:2的p次方= 页大小,如下图所示,页表的大小决定了vpo的位数。
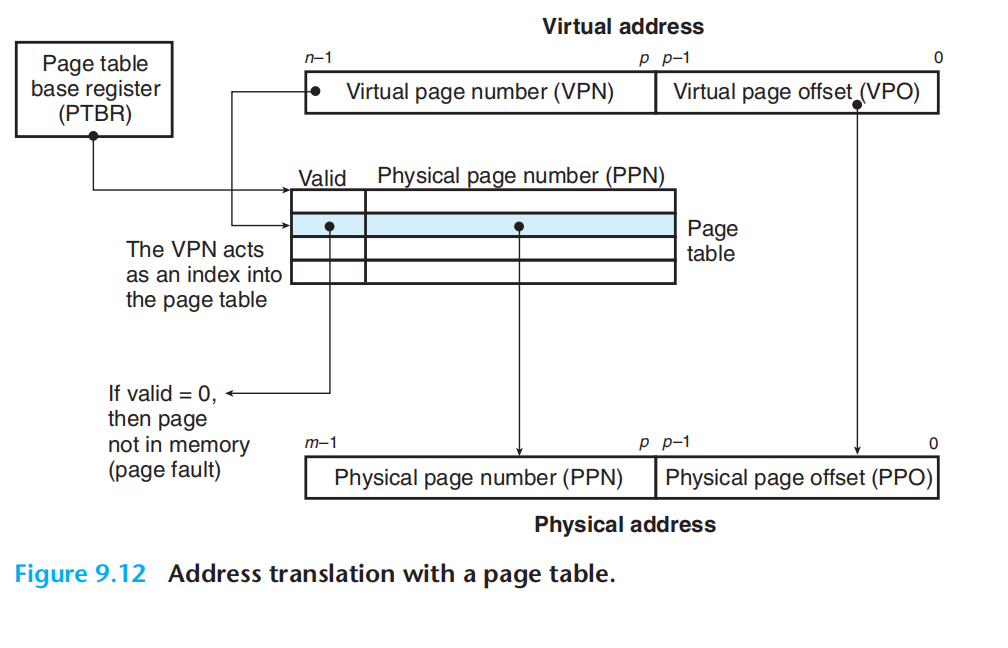
上图便是虚拟地址与物理地址映射的核心逻辑:
1.VPO = PPO(注意VPN与PPN的位数不一定相等)
2.VPN通过页表,获取PPN,
3.PPN+PPO = full address
完整的翻译流程:
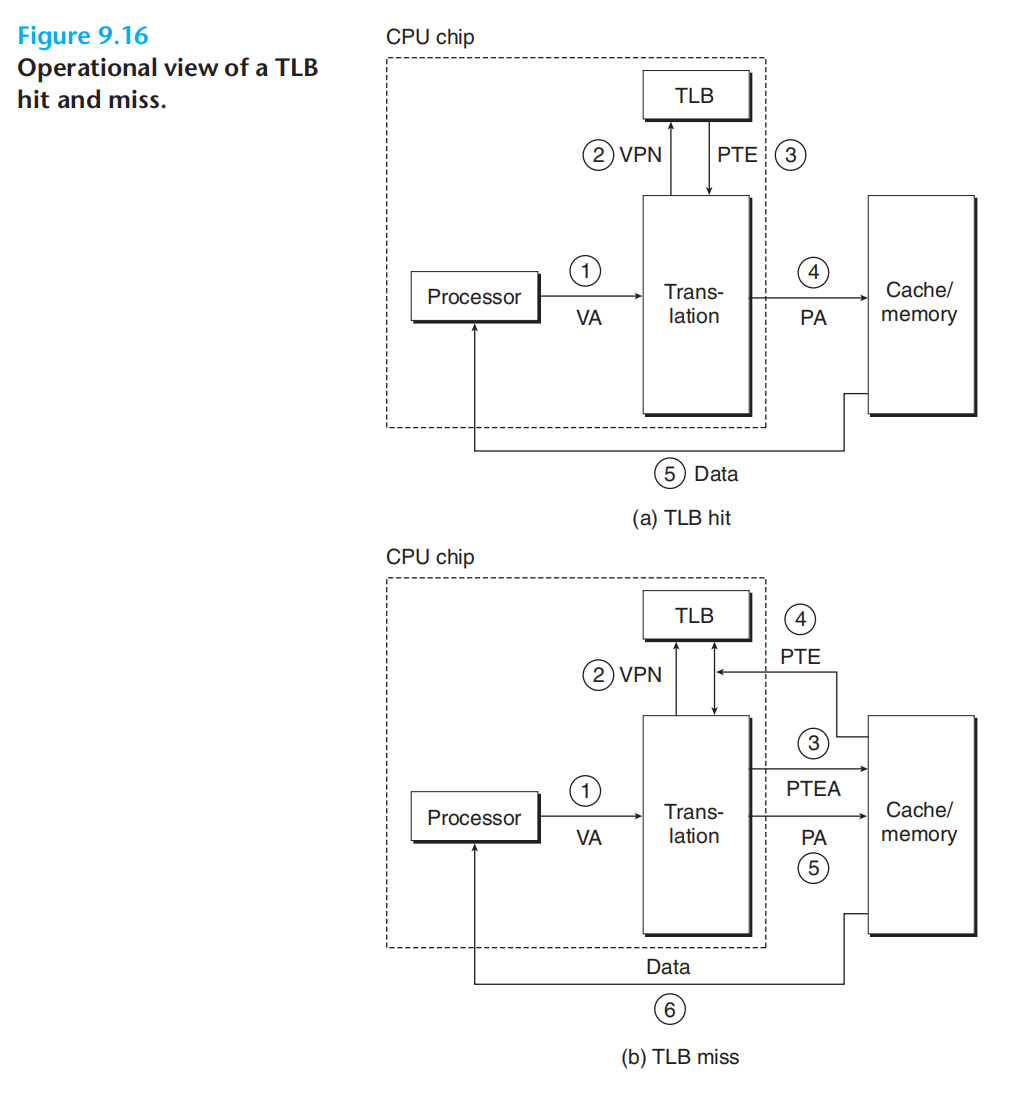
命中&不命中
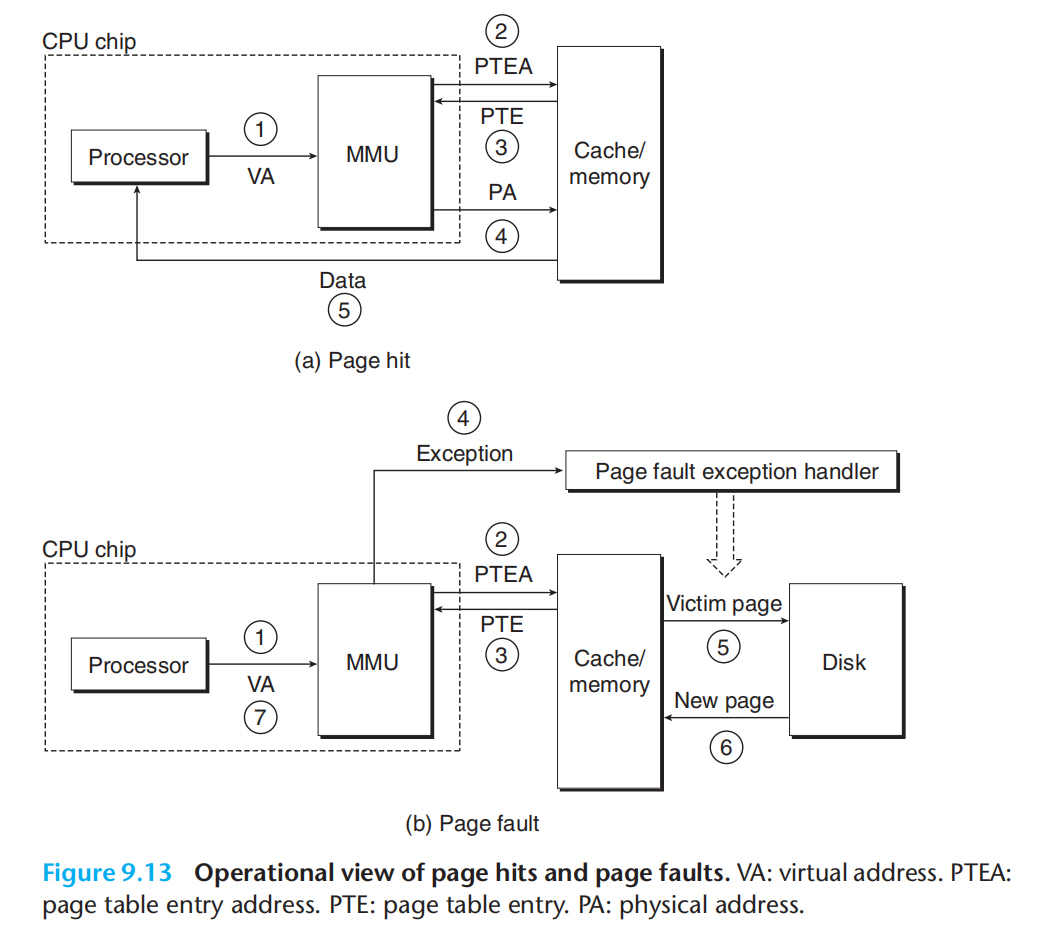
步骤2:请求PTE 地址
步骤3:返回PTE内容
注意:在缓存系统中(SRAM、DRAM)我们都是使用的物理地址!
虚拟内存与高速缓存:
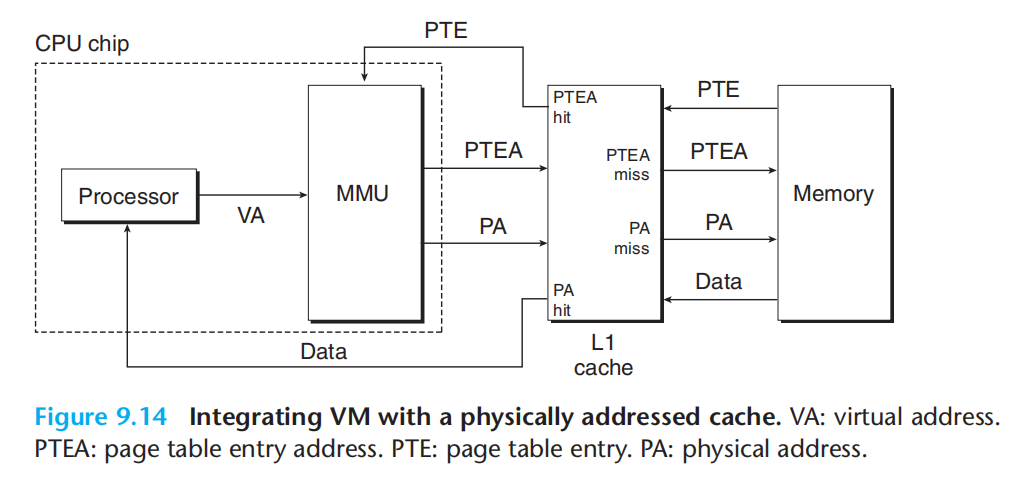
虚拟内存与TBL(快表Translation Lookaside Buffer(页表缓存)):
快表的组成:

t位,由TLB组多少决定,2的t次方个组
包含了TLB的名字&不命中图:
多级页表:
32位地址空间,假设页表大小为4KB,那么需要2的20次方个PTE,又假设每个PTE需要4B,总计页表需要4MB。
采用多级页表(2级为例):一级页表:1024个条目,二级页表还是1024个条目,每个条目4B,一级页表占用4KB,二级页表占用4MB,总计4.4MB。
全部占满的情况下,多级页表更占用内存。那为什么多级可以减少内存使用呢?
- 如果一级页表的PTE是空的,二级页表就不会存在。
- 只有一级页表&二级中常用的才会常驻主存。
端到端翻译:p573
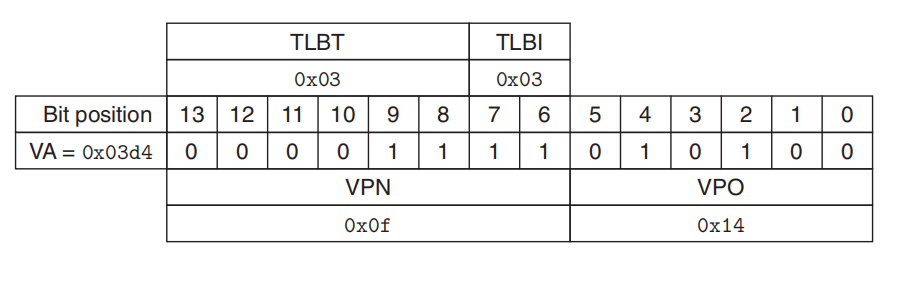
虚拟地址
TLBT:4组,2位索引
页表:页大小64B,6位偏移,8位VPN
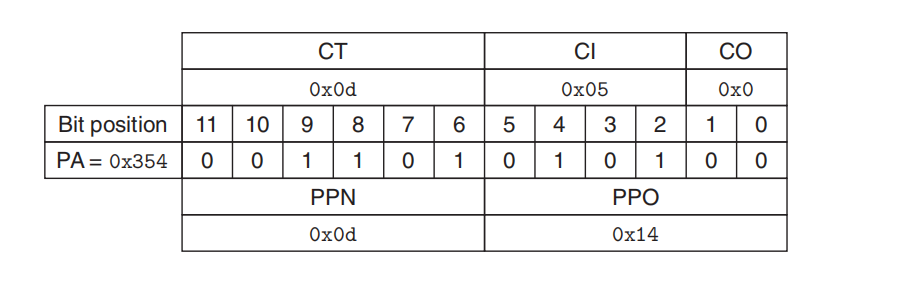
物理地址
缓存:4字节+16组= 2+4 位索引
案例
core i7
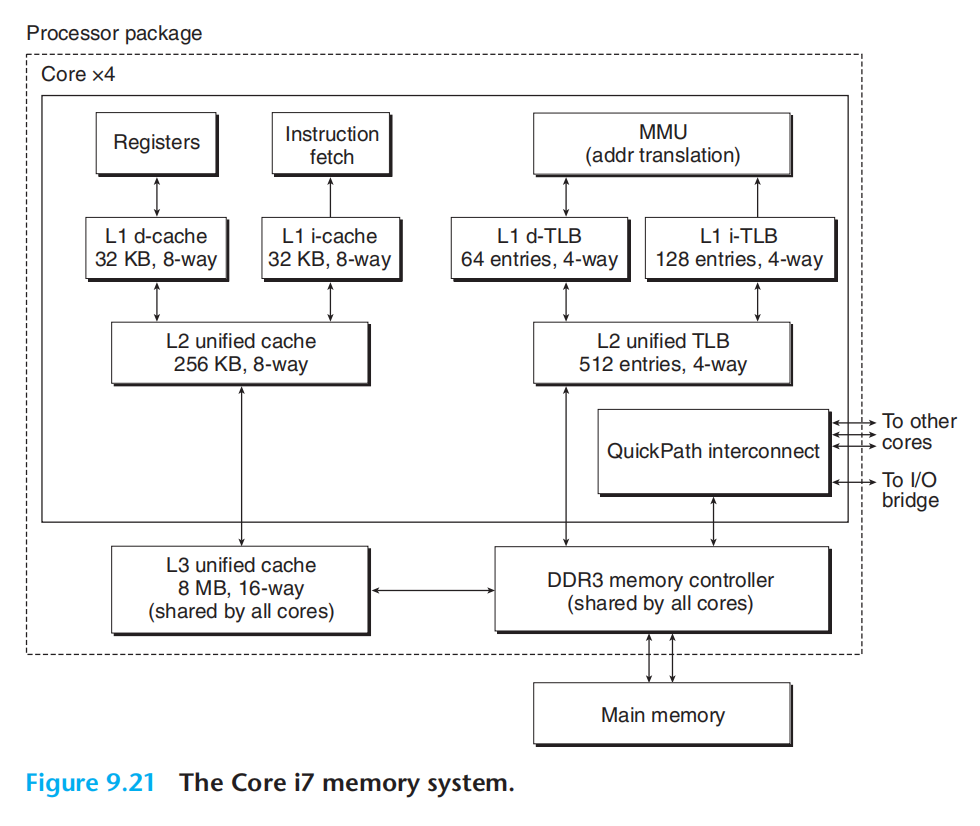
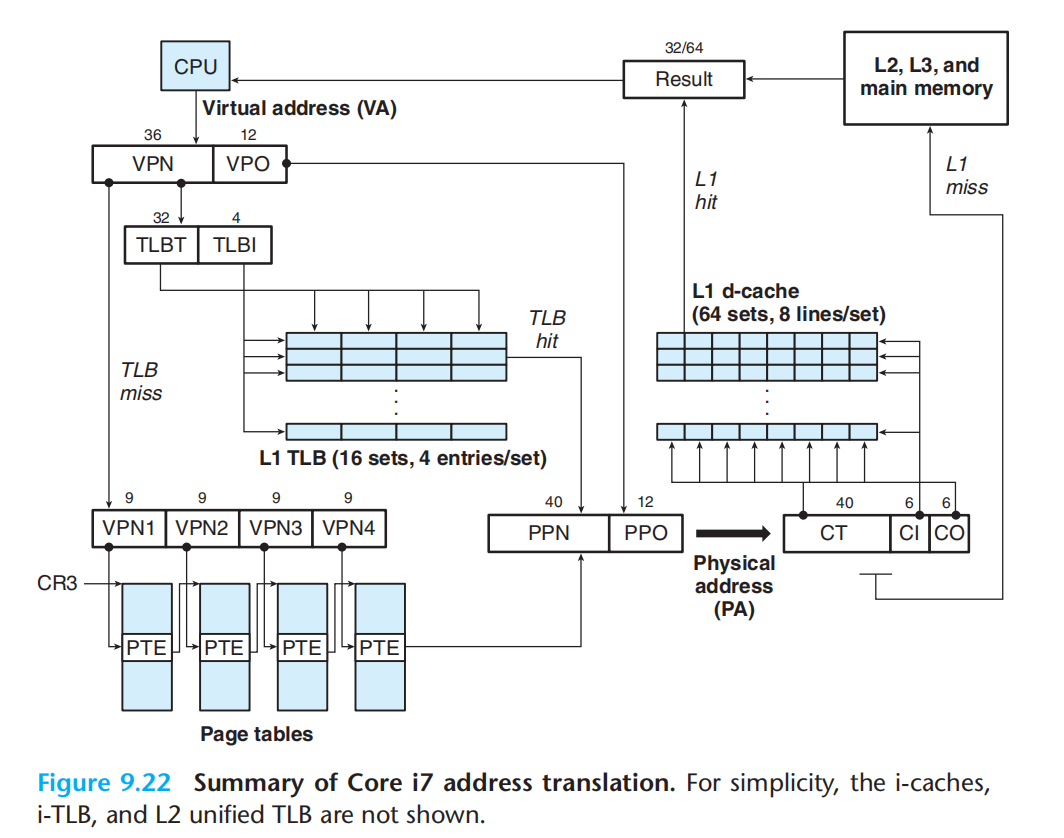
上图使用了四级页表。
通常页表中的PTE会有一些额外的标记位,以提供更强大的功能:诸如权限,A位(引用)D位(修改)。
linux 的虚拟内存系统
linux为每个进程维护了一个独立的虚拟地址空间,在对虚拟空间的管理中使用了分段与分页相结合的技巧。
分段示例:
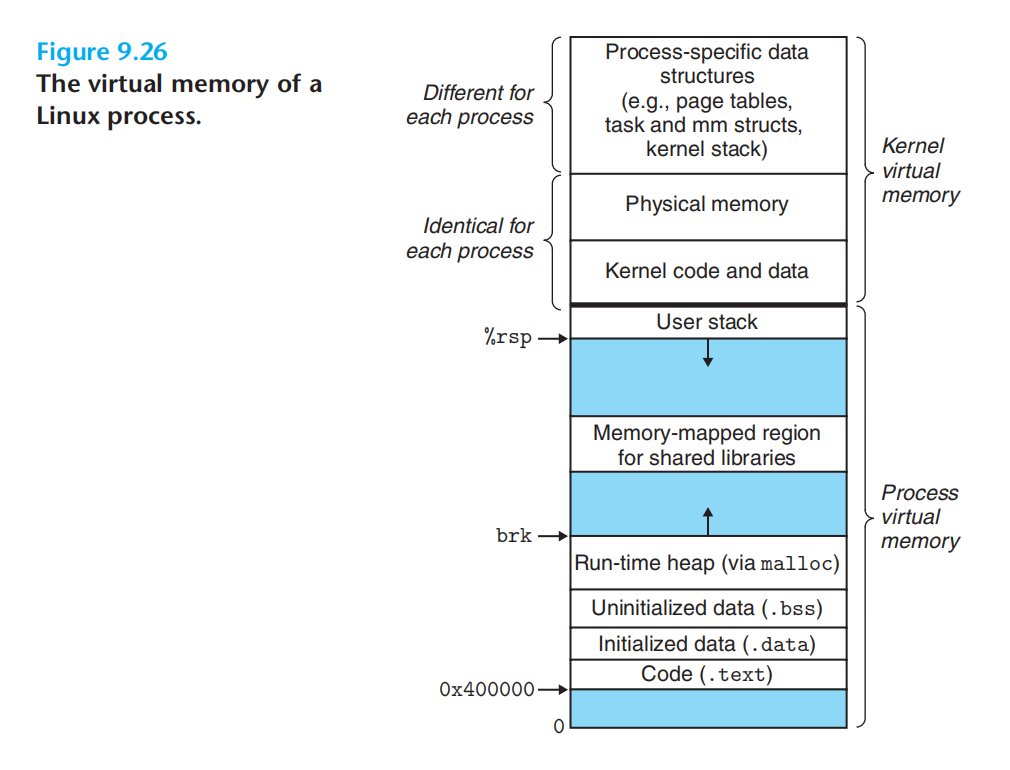
里面对所有进程都统一的Physical memory应该是指实际的一组连续的虚拟页面(>=实际的DRAM(包含了一些io设备等)),映射到相应的一组连续的物理页面。这样对所有进程,我们访问虚拟地址1,实际都是访问的相同的物理内存。
这里注意一个概念区分:虚拟内存指的是虚拟地址映射的内存。包含了:已分配未缓存(被交换到了磁盘)+已分配已缓存在dram中的。
point:
区域(段):每个存在的虚拟内存页都属于某个段,段就是连续的虚拟内存。Linux organizes the virtual memory as a collection of areas (also called segments).An area is a contiguous chunk of existing (allocated) virtual memory whose pages are related in some way.
linux虚拟内存区域的内核数据结构:
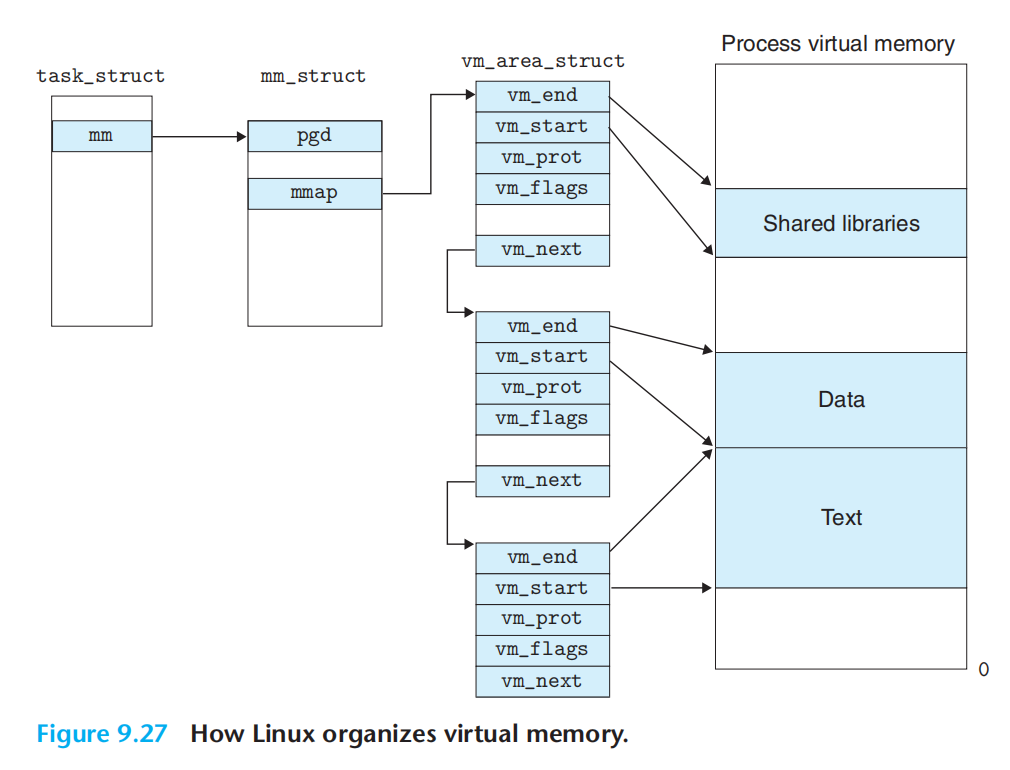
每个进程维护单独的任务结构(task_struct),pgd指向一级页表基址,mmap指向一个区域结构链表,里面的每一个项就是一个区域。
缺页处理:
1.是否合法
2.是否有权限
3.确定牺牲页并替换
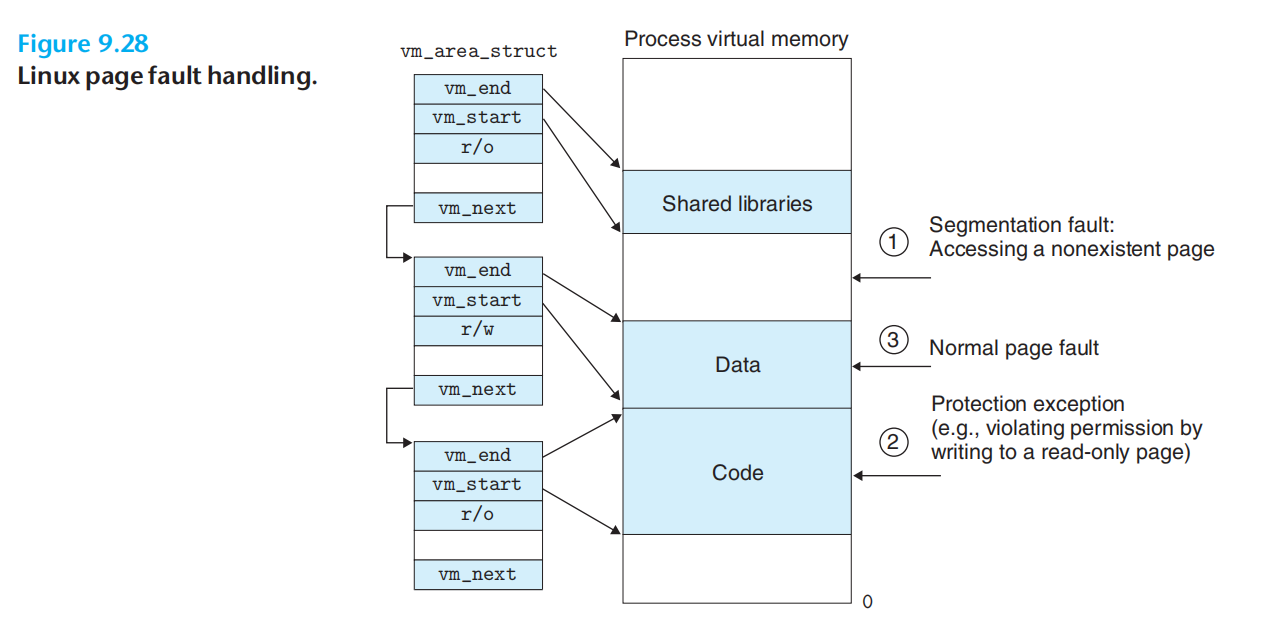
内存映射
内存映射:虚拟内存与磁盘对象(1.linux文件系统的普通文件;2.匿名文件)之间建立关联。
1.普通文件:虚拟区域映射到普通文件的连续部分。文件被按照页大小,分片,每一片对应一个虚拟页,虚拟页只有在第一次被cpu引用时才被加载进入DRAM.
2.匿名文件:请求二进制0的页
一旦虚拟页面被初始化,就会在内核维护的交换空间(交换文件)中换来换去,交换空间限制着当前运行进程能够分配的虚拟页面总数!!!!(物理+交换空间?)。
注意:虚拟地址空间是对整个磁盘的划分,而进程所能拥有的虚拟页的多少则取决于交换空间。
交换空间,磁盘上的一块空间,用于存储不活跃需要从DRAM中换出的虚拟页。其实现方式有如下两种
1.交换分区(Swap Partition):磁盘上划出一块连续的区域。
2.交换文件(Swap File):交换文件,文件系统中的一个文件,被用作交换空间。
内存映射与共享对象
1.共享对象
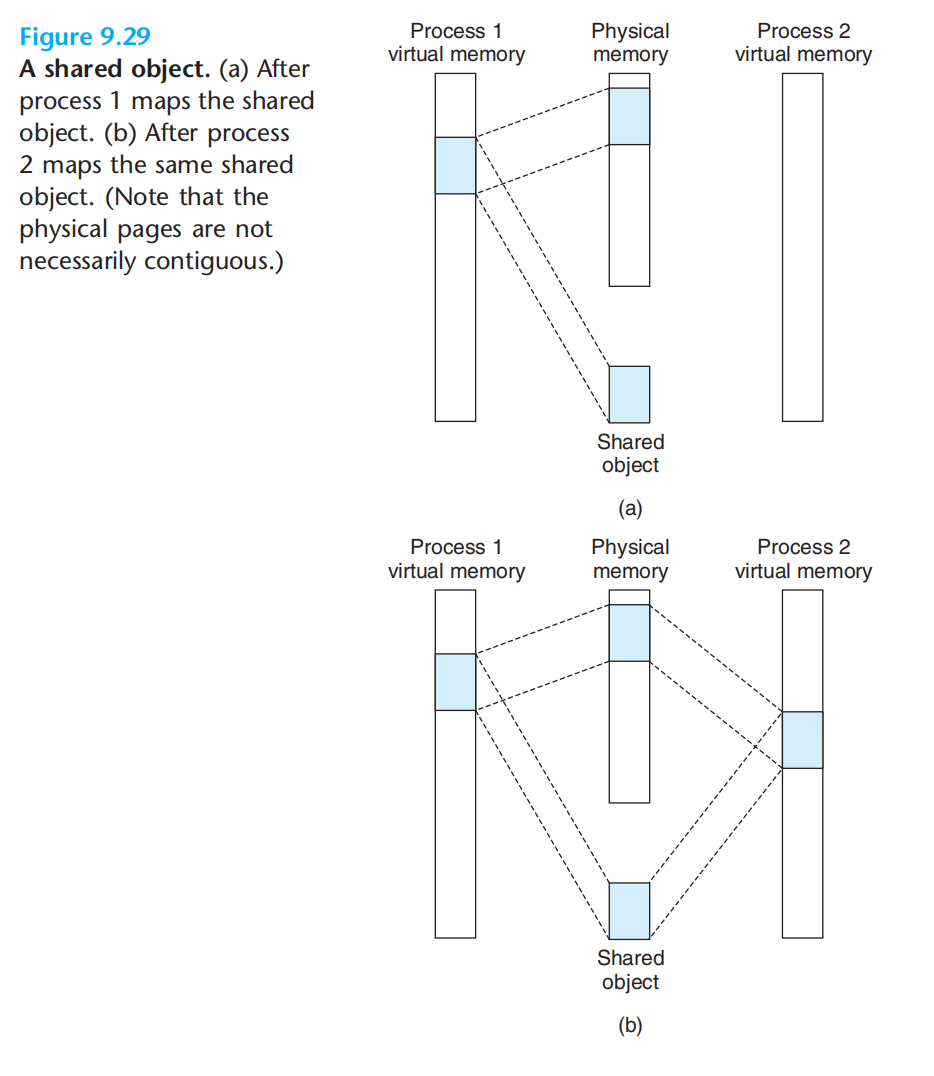
2.私有对象(写时触发copy-on-write)
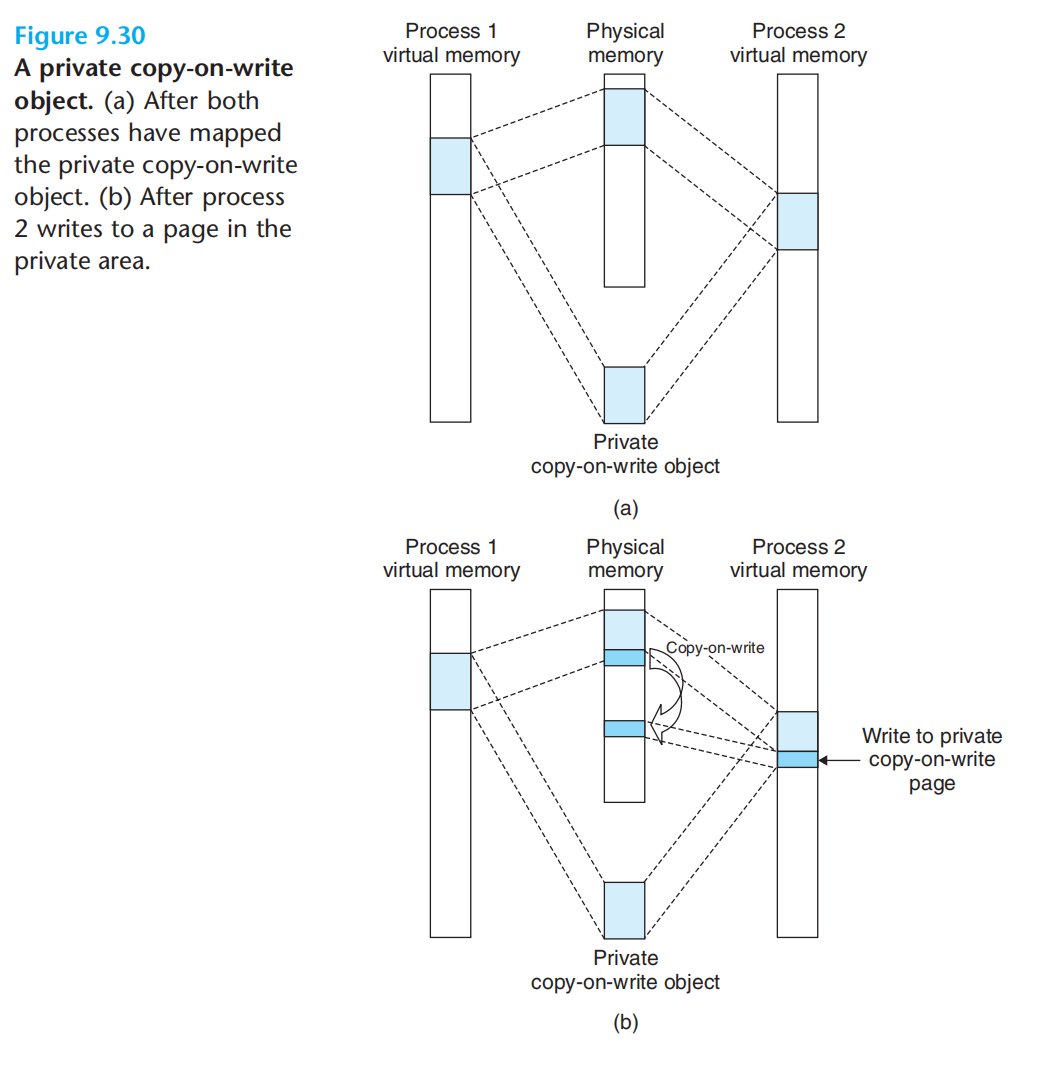
内存映射与fork函数
fork调用时,会复制当前进程的mm_struct,区域结构链表,页表等内容,并分配pid,同时将两个进程的页标记为只读,区域结构标记为私有的写时复制。
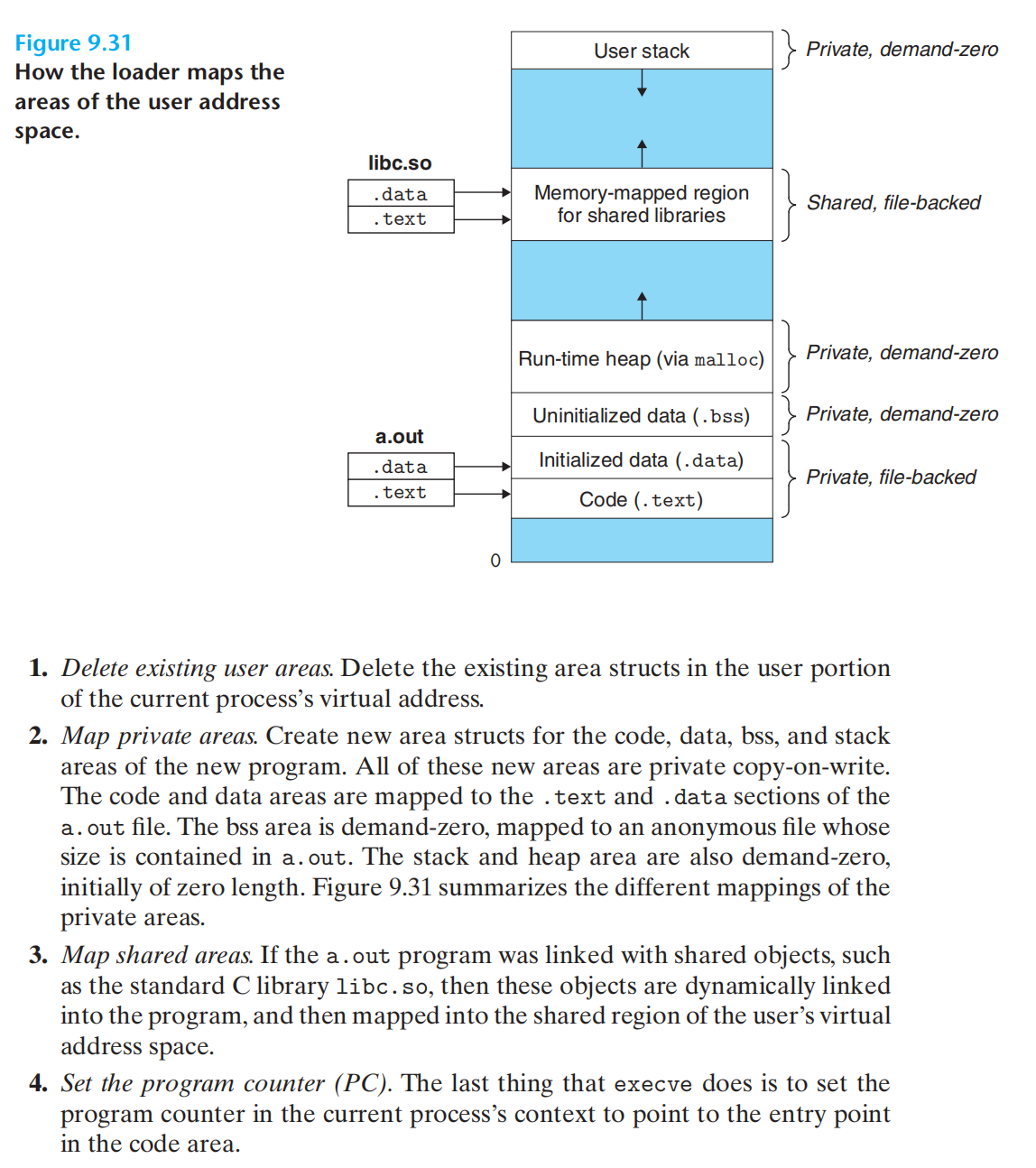
内存映射与execve函数
1.删除已存在的用户区域
2.映射私有区域(创建新的区域结构,并将执行程序的相关结构映射到新创建的结构)
3.映射共享区域
4.设置程序pc
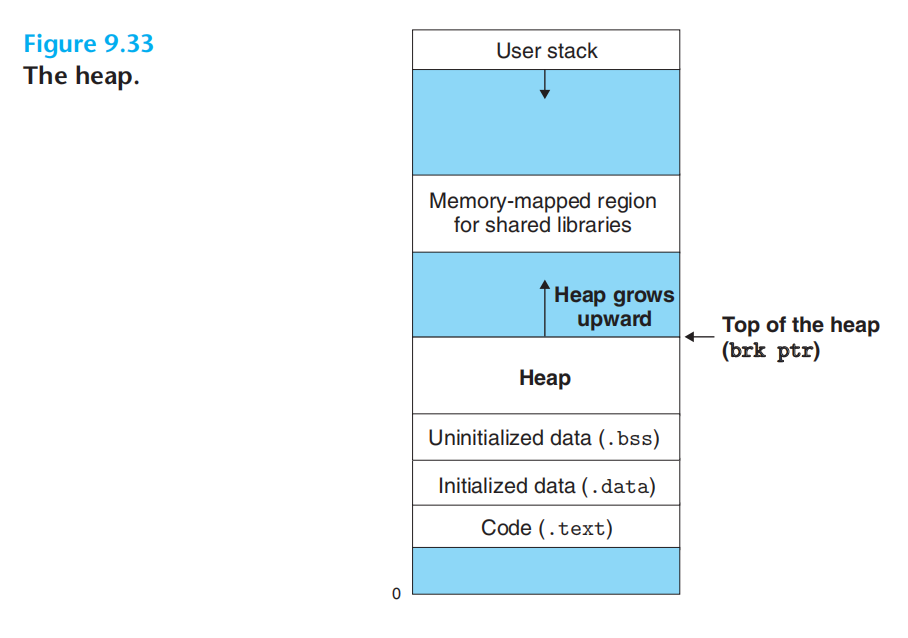
mmap&munmap
动态内存分配
mmap&munmap可以进行虚拟内存的分配与释放。
更高级一点的则是动态内存分配器:
heap,brk指针指向heap顶。向上生长,不同于stack向下生长。
分配器将heap视为不同大小的块(block),每一个块就是一个连续的虚拟内存chunk。块要么已分配,要么就是空闲的待分配。
分配器的两种风格:
1.显式:malloc & free
2.隐式:garbage collector
malloc只分配,不初始化;calloc,分配并初始化为0;realloc,重新分配之前的block。
虚拟内存空间大小 = 物理内存(DRAM) + 磁盘交换空间
分配器:最大化吞吐率 与 最大化内存利用率之间的平衡。Naive programmers often incorrectly assume that virtual memory is an unlimited resource
通用策略:维持少量的大空闲块,而不是大量的小空闲块。
利用率低:碎片
内部碎片:对齐,最小值等。已分配的块大小与有效载荷之间只差,取决于以前的请求模式与实现方式有关。
外部碎片:空闲块合起来可以满足分配请求,但每一个单独块均不能满足。不仅取决于以前的请求模式与实现方式,还取决于未来的请求模式。
围绕分配器设计必须要考虑:
空闲块:记录、放置、分割、合并
answer:隐式空闲链表
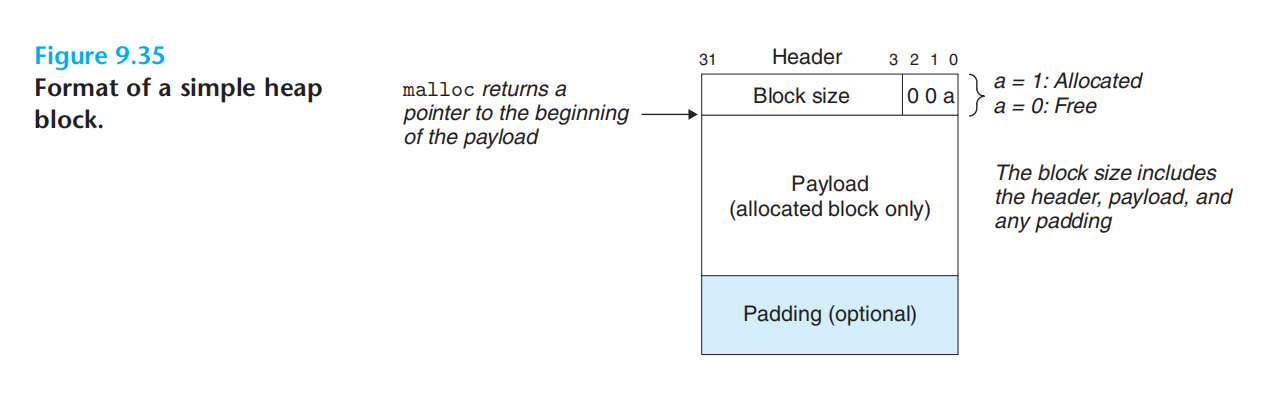
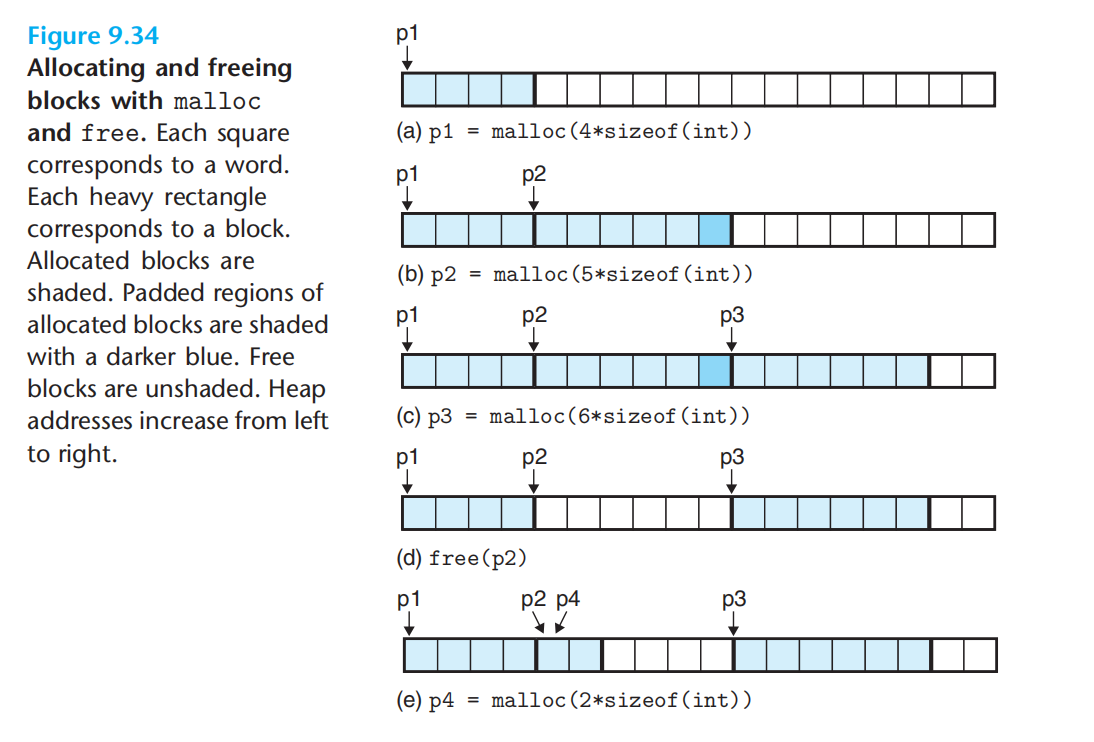
示例:头固定占了4个字节。如果要求双字对齐(8字节)则块大小(头+已分配+填充),为8字节的倍数。
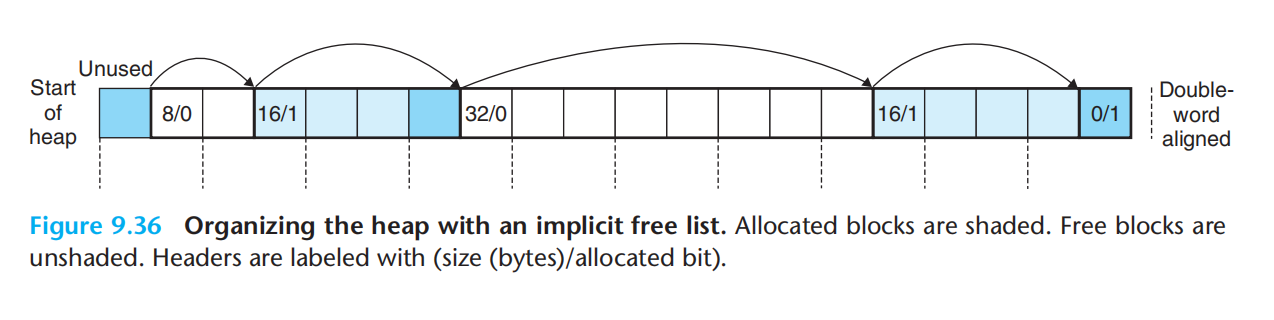
放置块
分割空闲块
获取额外堆内存(sbrk函数)
合并空闲块(假碎片)
显示空闲链表
分离的空闲链表
GC
以不在heap中的位置(变量、指针等)作为根节点,heap中的已分配的块作为子节点。构建有向可达图。然后从中标识出垃圾。
mark & sweep 垃圾收集器:
…
常见内存错误
…
系统级别IO
最开始讲了程序执行的内部,再到程序与系统的交互,现在开始程序与外部的交互。
字节序列是计算机的一种表现形式,通过结构化,赋予序列意义。
linux文件:字节序列
io设备:被模型化为文件,输入输出,对应读和写
文件的通用操作模型:
- 打开
- 改变当前文件位置
- 读 or 写:从某个位置开始,传输多少个字节
- 关闭
文件类型:
- 普通文件(文本文件、二进制文件)
- 目录:一个由链接构成的文件
- 套接字
- 命名通道、符号链接、字符&块设备…
Linux文件结构:
- 描述符表(进程私有)
- 文件表(进程共享):引用计数、位置
- v-node表(进程共享):文件的结构信息
两次open相同文件:两个fd,两个文件表(表示不同的文件位置),一个v-node 因为只有一个文件。
io重定向:fd指向新的文件表
计算机网络
基础的网络模型:局域网+路由器=广域网,网络适配器使主机连接到网络。
网络的基本介绍
网络:io设备,网络适配器(网卡)+(io总线,内存总线)+主存
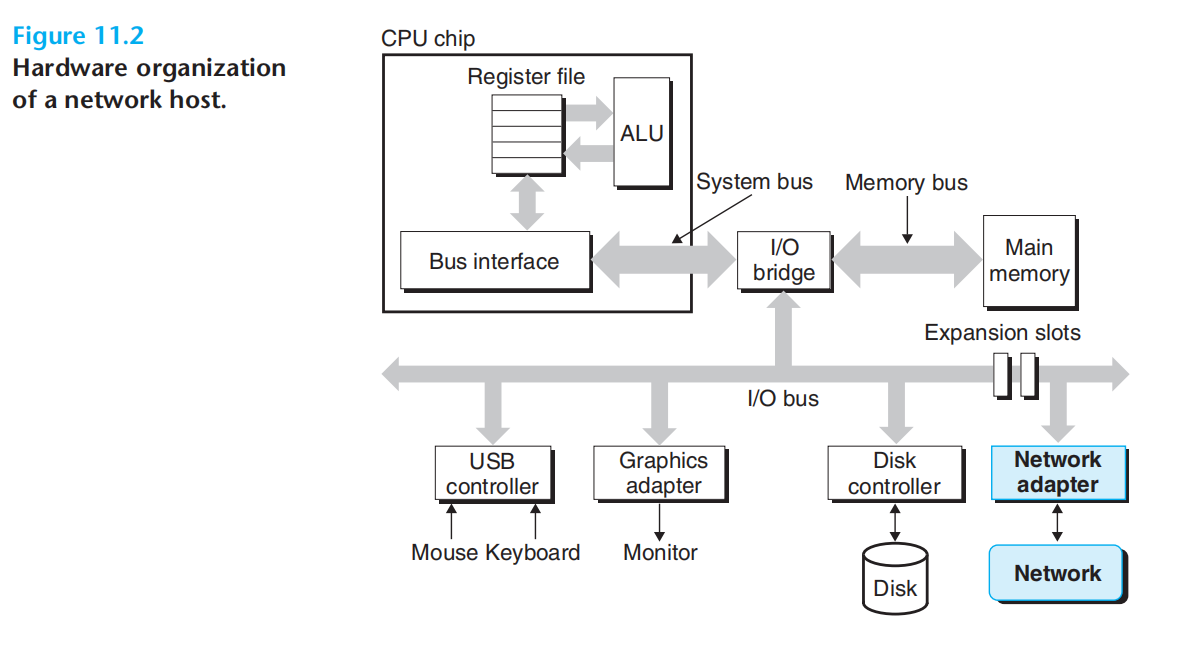
局域网:LAN,最成功的局域网= 以太网
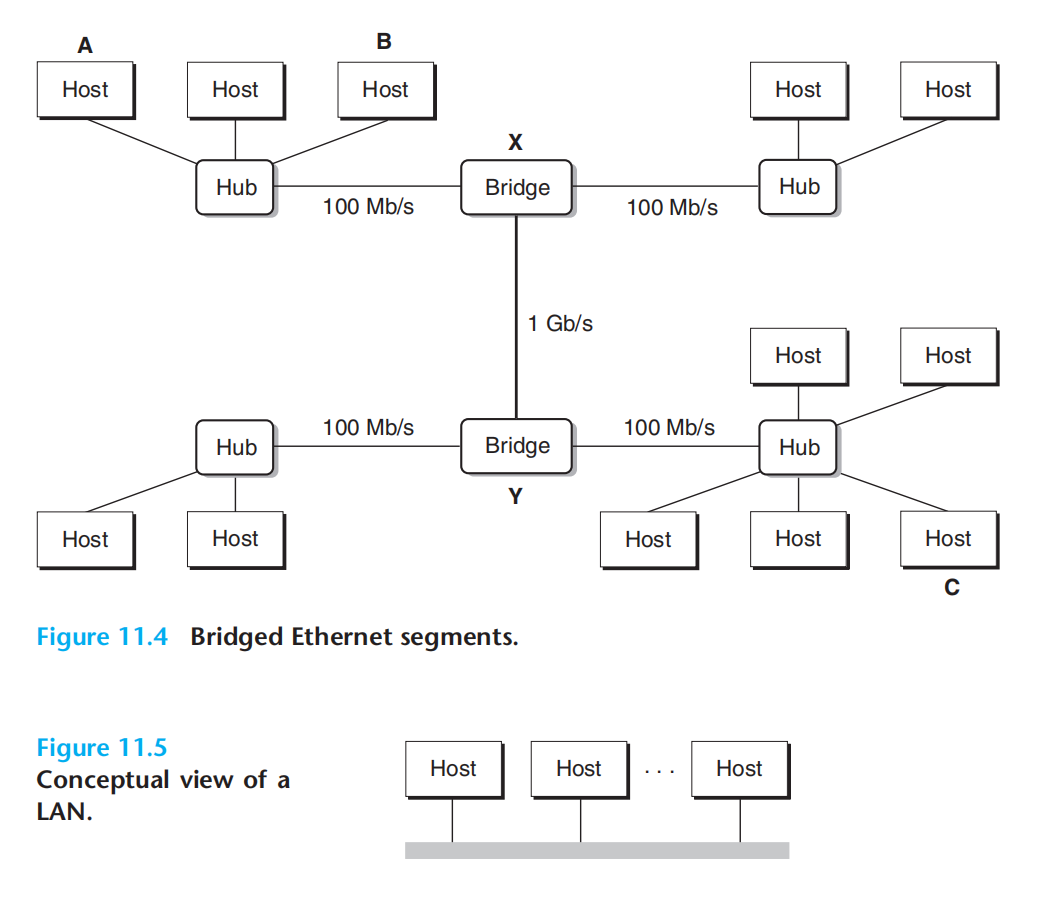
以太网段:主机+集线器 = 局域网;局域网与局域网之间通过网桥连接,不兼容的局域网可通过路由器连接。主机连接集线器的一个端口,集线器将从一个端口接收的数据复制到所有端口,但只有目标主机会实际读取。
广域网:WAN
wan:
互联网的一个特性就是许多网络不兼容,如何将一个数据跨过不兼容的网络传输到其他主机? – 软件定义的协议。(统一的地址+传送机制(head,body))
本章中我们采用的抽象模型:
1.主机被映射为32位ip地址
2.ip被映射为域名
3.internet上的主机进程 通过 connect 与internet上的其他主机进程 通信
socket 编程
ip
1.ip的表示
2.网络字节顺序,及其转换
3.ip点分十进程与十六进程的转换
通讯中,网络字节序,大端表示法
域名
dns
nslookup www.baidu.com 获取域名的IP地址
socket
因特网的客户端与服务器是建立在进程上的,连接的端点就是套接字。
定义套接字地址:(ip:port)
定义socket连接:连接的两个端点各自套接字,构成套接字对,socket pair 四元组
socket接口
socket接口是一组 函数,与unix io函数结合起来,用以创建网络应用。
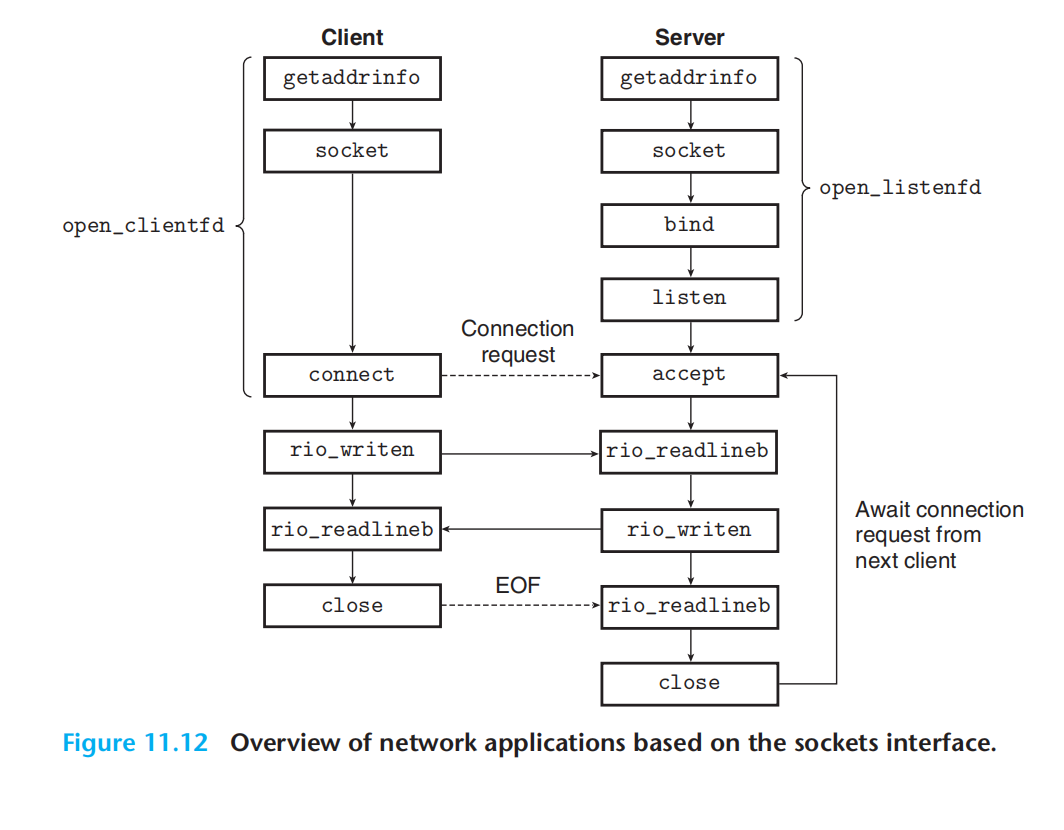
客户端:
创建socket
调用connect
服务器:
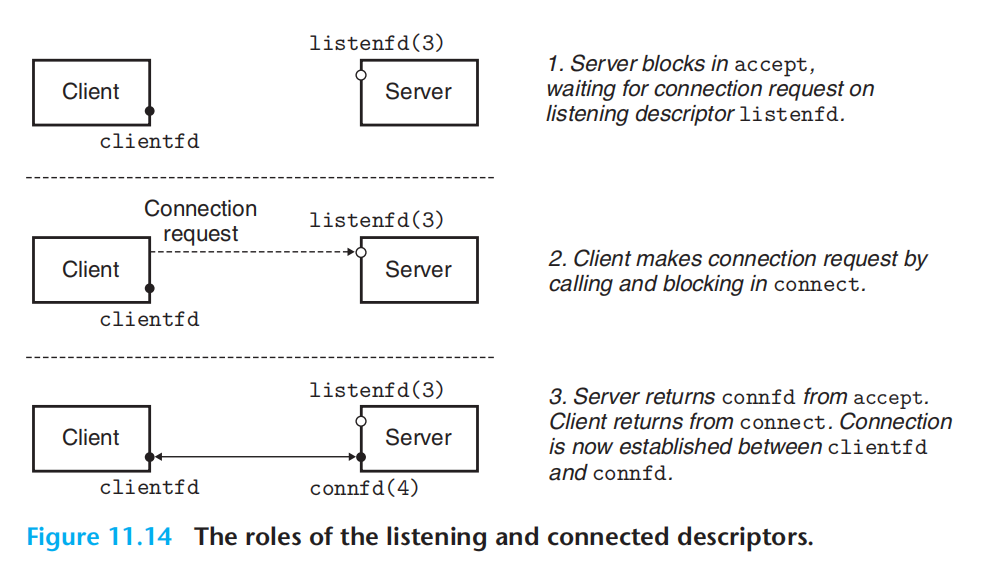
bind:将套接字地址与socket绑定(即,初始化,表明ip:port 是这个套接字的),客户端不需要bind,因为作为发起方不必关心端口;而服务端作为接收方往往需要bind特定的端口。
listen:将主动socket 转化为监听socket
accept:等待连接到达监听描述符,然后稍加处理,返回以连接描述符。可以理解为监听描述符是2元组,连接描述符是4元组。
1.sockaddr 与 sockaddr_in
sokcet地址的定义
2.sokcet
3.connect
4.bind
5.listen
6.accept
更强大的函数:
7.getaddrinfo,创建用于建立连接的socket 地址,方便后续调用socket 与 connect
freeaddrinfo,释放链表
gai_strerror,解析错误,将错误代码转换为字符串
8.gethostname:将addrinfo 转换为主机和服务名称字符串
可以简化,创建包装函数:
9.open_clientfd & open_listenfd p661
web服务器
web服务,通常基于http协议
web服务与常规的文件服务(例如ftp)主要区别则是,内容由html语言编写。
web内容是与MIME类型类型相关的字节序列
web服务器向客户端提供服务的两种方式:
1.取一个磁盘文件,将其内容返回给客户端(服务静态内容)
2.运行可执行文件,将其输出返回给客户端(服务动态内容)
URL是URI的一个具体实现
一个tiny web服务器
并发编程
所有欠下的工作,终将会在一个适当的时候,找到你。
今天,0922,开始学习并发编程,这一本该在1个月之前就开始进行的内容。不管怎样,现在正式开始!
并发:逻辑控制流在时间上与另一个逻辑控制流重叠。
并行:并发的一个真子集,两个逻辑控制流并发的运行在不同的处理器/计算机上。
三种基本的构造并发程序的方法:
1.进程,进程间通信
2.io多路复用:一个进程,将逻辑流模型化为状态机,数据到达文件描述符,状态就开始流转,所有逻辑流共享同样的地址空间
3.线程:类似前面二者的结合,同进程一样,由内核进行调度,又同io多路复用一样共享同一个地址空间
进程
进程的缺点在于
1.进程间的通信
2.开销较大
io多路复用
事件驱动程序
并发事件驱动程序
基于io多路复用的并发事件驱动程序
注意:纯粹的io多路复用,是只有一个进程来处理多个逻辑流的。所以叫并发事件驱动。
线程
线程与进程区别的两个主要点:
1.切换开销更小
2.进程有严格的层级结构,线程则是peer thread pool
1.线程可以杀死任何对等线程
2.线程可以等待任何对等线程终止
3.所有对等线程,可以读写相同的共享数据
Posix线程
- 线程的创建pthread_create
- 线程的终止
- 函数返回
- pthread_exit,主线程调用,则会等待所有对等线程终止后,终止自己,同时终止进程。
- exit 进程终止时
- pthread_cancel
- 回收已终止的线程资源:pthread_join
- 线程创建之初,默认是joinable ,pthread_detach 将其改变为 detached。为了回收资源,每个线程要么被其他线程显示回收,要么detached
- pthread_once 线程初始化
共享变量
c语言的线程内存模型
线程有自己独立的 id,stack,stack ptr,程序计数器,条件码,通用目的寄存器。
线程的stack也是被存放在虚拟地址空间的stack中,如果其他线程获取了相应指针,也是可以进行修改的。 - 全局变量,定义在函数外,存放在虚拟内存读写区域,只有一个实例。
- 本地非static变量,存放在每个线程各自的stack中。
- 本地statci变量,与全局变量一样,虚拟内存空间只有一个实例。
信号量
围绕着共享变量的操作,存在一个由相关指令构建的临界区。
要确保最终结果的正确性,临界区内的指令在执行时需要确保对共享变量的互斥访问。
进度图-临界区-不安全区
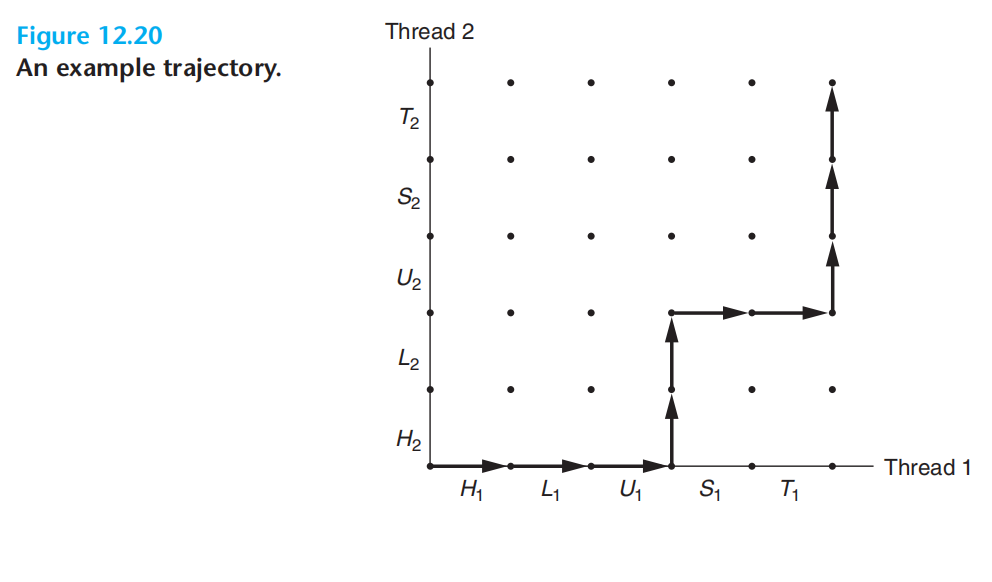
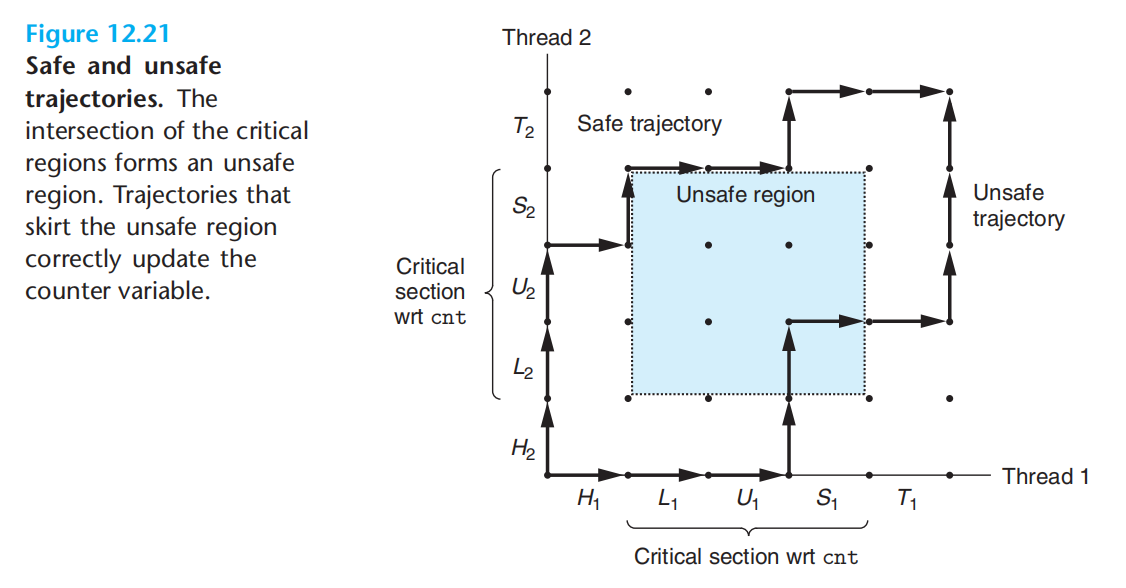
为了确保轨迹绕过安全区,需要对线程进行同步。
p:-1,0则挂起线程,否则-1并执行
v:+1,如果存在p在等待,则随机重启一个
二元信号量=互斥锁
除了互斥锁外,信号量还可以用于调度共享资源。
生产者-消费者
读-写
刻画程序性能
死锁:进度图中,重叠的禁止区。
一种解决方法:以一种顺序进行加锁/释放? 参考极客时间。
20240922:终于初步的over了!不知为何,一点兴奋之感都没有。因为没有总结系统的知识体系吗?还是因为还剩下一个lab没有完成?或者,有很多课后习题没有处理?whatever,完全没有那种完成目标的兴奋之感!也许是生理上的因素。
20241006:
国庆的倒数第二天,总算初步完成了csapp的总结,此刻并没有前几个月在学习过程中所想象的将来完成时的兴奋与冲动。
1.可能源于这个过程中的投入,有效心流的缺失,给人一种即使时间流逝了,内心似乎依旧空空如也的感觉。抛开个人感受,知识是否得到了有效掌握?不过今天还有2小时可以有效弥补。
2.质量的缺失,并没有完整的做完最后一个lab,课后习题也基本没做。同时也并不是完整的理解了所有的细节。
3.个人的周期叠加,自9月后没有再去运动,同时几乎每周一次,致使自身能量水平下降,状态不佳。正循环的终止。
4.未来预期的降低,也许这些投入并没有特别的意义。倘若一开始不赋予意义,一切又绝不会开始。
5.个人长期的无意识的思维逻辑:某种无意识的欲望压抑。及对自身超出能力范围的要求,致使所有一切变成了对意志力的消耗,极大的减少了正向反馈。
抛开知识的掌握,至少三点收获:
1.以一种至少现在回想起来并不会觉得特别碌碌无为的方式,流逝了几个月的生命。
2.开始一种新的目标导向的思维模式,进入未知的领域,不断的收集信息,任务分解,直至细化简单到能理解的层面,然后开始投入时间,最终解决问题。这种模式,最重要的点就是信念,以一种近似信仰的方式坚信自己能干成。我的直觉不错,高中时第一次开始给自己强调:干成一件事的前提是你得相信自己能干成!也如同jyy所言:迈出第一步最重要的,莫过于坚信所有的问题都能得到满意的解答,然后去花时间理解其中的来龙去脉。虽然在后来的不断的自我解构中,这种自信近乎没有了。感谢意志对彰显自身存在的强烈渴望!
3.从c语言到汇编,在第二点的实践下,算是对恐惧挑战的一次小小的成功案例。这种经验的积累是自信的关键!从18年毕业到21年离职转行到23年离职,这种面对黑盒面对未知的恐惧,主宰了我的方方面面。消除恐惧的最好方式就是直面恐惧!
虽然工作中,我们讨厌日报,讨厌科层制,把许多东西归纳为繁文缛节。可是是否存在一条明确的区分繁文缛节与执行过程中必要的分解细化的界限呢?我们的任务是学习,就必须要有所输出:
csapp,Computer Systems: A Programmer’s Perspective,从我们按照特定的语法,将逻辑转换为特定格式的语言开始,到计算机表现出符合我们预期的行为结束。这一过程究竟发生了什么?
首先我们将计算机抽象为:二进制比特序列+物理硬件,数据+对数据的操作。
操作系统=进程
进程=isa+虚拟内存
虚拟内存=主存(缓存)+文件(本体)
文件=磁盘+io设备
本书分成了三个部分:
1.完整的程序运行时的与cpu的交互
2.程序从编写完成到运行时与内部系统的交互
3.程序与外部的交互
2.对二进制比特序列的结构化处理,赋予了比特序列意义。涉及字符与数字(整数、浮点数)
3.软件层面对ISA的逼近–汇编:指令(对数据的操作)+stack(数据的存储)【stack结构,数据类型的存储,指令与stack的交互】
4.硬件层面对ISA的逼近–处理器:组合电路(操作)+存储设备(RAM+时钟寄存器);物理实现可以简化为时钟周期的电位设置。顺序(取指-译码-执行-访存-写回-PC)到 流水线(pc预测+数据冒险+控制冒险+异常)
5.硬件的实现 与 软件的交互:一个新的处理器结构模型(指令控制单元(取指、译码、退役)+执行单元(分支、计算、加载、存储))。重点介绍了这种结构下指令级别的并发执行:指标(延迟时间、发射时间、容量);模型(循环寄存器+指令=关键路径)
6.存储结构:SRAM、DRAM(基本单元-电容、超单元、R*C=内存芯片、内存控制器、主存)、磁盘(主轴、盘片、表面、磁道、扇区+间隙、柱面。寻道、旋转、传输)、固态、io设备。基本操作流程。速度的差异+局部性=缓存的必要性。缓存结构(S、E、B、m)(m位=t+s+b),组选择、行匹配、字抽取。
7.链接:符号引用与符号定义,符号解析(E、U、D)与重定位(明确地址+重定位符号(符号表条目))。目标文件结构、虚拟空间结构。共享库与库打桩。有点模糊?
8.异常:中断、陷阱、故障、终止。进程与信号(pengding与blacking)。内核态到用户态时,检测并处理信号
9.虚拟内存:地址空间与磁盘,页,页表,多级页表。页表查找:cpu-tlb-cache。vpn+vpo,tlb(index+tag),ppn+ppo,缓存的co,ci,ct(tsb)。虚拟地址空间结构、内存映射。内存映射与符号表?
10.io:符号表、文件表、v-node表
11&12:监听描述符&连接描述符、进程,线程(内存模型,race,进度图,信号量),io多路复用。
马上要闭馆了,速度结束!今晚还有一件事儿呢!(事后来看,自取其辱了)