操作系统_并发
start
Don’t Panic!
shell:将自然语言翻译成操作系统能理解的语言。
topic:
why? what? how?
图灵机与可计算性
1946.2.14 eniac 诞生
一个内存可以放两个程序了!
+
只有1个cpu
=分时操作系统 并发!
进程+虚拟内存

[Read The Fucking Manual]
[Search The Fucking Web]
机器永远是对的
没有测试的代码永远是错的
Get Your Hands Dirty
什么是程序
状态机:
数字逻辑电路
状态:寄存器
初始状态:
迁移:组合逻辑电路
理解数字逻辑电路处的c代码,gcc 宏展开 done
七段管 done
#include <stdio.h>
#include <unistd.h>
#define REGS_FOREACH(_) _(X) _(Y)
#define OUTS_FOREACH(_) _(A) _(B) _(C) _(D) _(E) _(F) _(G)
#define RUN_LOGIC X1 = !X && Y; \
Y1 = !X && !Y; \
A = (!X && !Y) || (X && !Y); \
B = 1; \
C = (!X && !Y) || (!X && Y); \
D = (!X && !Y) || (X && !Y); \
E = (!X && !Y) || (X && !Y); \
F = (!X && !Y); \
G = (X && !Y);
#define DEFINE(X) static int X, X##1;
#define UPDATE(X) X = X##1;
#define PRINT(X) printf(#X " = %d; ", X);
int main() {
REGS_FOREACH(DEFINE);
OUTS_FOREACH(DEFINE);
while (1) { // clock
RUN_LOGIC;
OUTS_FOREACH(PRINT);
REGS_FOREACH(UPDATE);
putchar('
');
fflush(stdout);
sleep(1);
}
}
import fileinput
TEMPLATE = '''
\033[2J\033[1;1f
AAAAAAAAA
FF BB
FF BB
FF BB
FF BB
GGGGGGGGGG
EE CC
EE CC
EE CC
EE CC
DDDDDDDDD
'''
BLOCK = {
0: '\033[37m░\033[0m', # STFW: ANSI Escape Code
1: '\033[31m█\033[0m',
}
VARS = 'ABCDEFG'
for v in VARS:
globals()[v] = 0
stdin = fileinput.input()
while True:
exec(stdin.readline())
pic = TEMPLATE
for v in VARS:
pic = pic.replace(v, BLOCK[globals()[v]]) # 'A' -> BLOCK[A], ...
print(pic)
- Make each program do one thing well
- Expect the output of every program to become the input to another
安装man的友好版本. Done
wget 证书验证失败,需要处理 done 、bashrc设置别名
图灵机是状态机
数字系统是状态机
所有的程序运行在数字系统上,程序=状态机
c语言:
堆栈=状态
main第一条语句=初始状态
执行语句=状态迁移
例子:gdb:每次执行都可以info frame
c程序的状态机模型:
-
状态 = stack frame 的列表 (每个 frame 有 PC) + 全局变量
-
初始状态 = main(argc, argv), 全局变量初始化
-
迁移 = 执行 top stack frame PC 的语句; PC++
- 函数调用 = push frame (frame.PC = 入口)
- 函数返回 = pop frame
汉诺塔的非递归版本:汇编语言。汇编层面,没有递归。
todo:理解汉诺塔的递归与非递归版本 同时 再接个cs61a 进一步理解 a>b ;b>a形式的递归,再进一步理解汉诺塔的非递归版本。
gdb可以切换到源代码视角? Layout watchpoint
程序是状态机:
在这个状态机中,函数调用是什么?函数返回是什么?
非递归汉诺塔:遍历stack,不停的压frame与排除frame,
变量+栈帧 && 语句
二进制下,状态机模型:
pc + 寄存器 :这个模型下,离开原来的逻辑流 需要 异常
纯粹的计算:内存/寄存器 取值/计算/放回去
执行流: cpu一但启动,就会不停的运行,如何从执行流中产生分支–syscall(实现与操作系统的交互):把状态交给操作系统,操作系统知道你要打印什么就给你打印,操作系统可以修改你的状态
程序= 计算+syscall
Todo 理解 minimal.S。 syscall 手册
程序:
寄存器、内存 + 指令:计算+syscall
程序,计算出图片,放到内存,操作系统去展示图片
寄存器+内存 && 指令
两种视角的切换与关联(编译)
编译正确性:
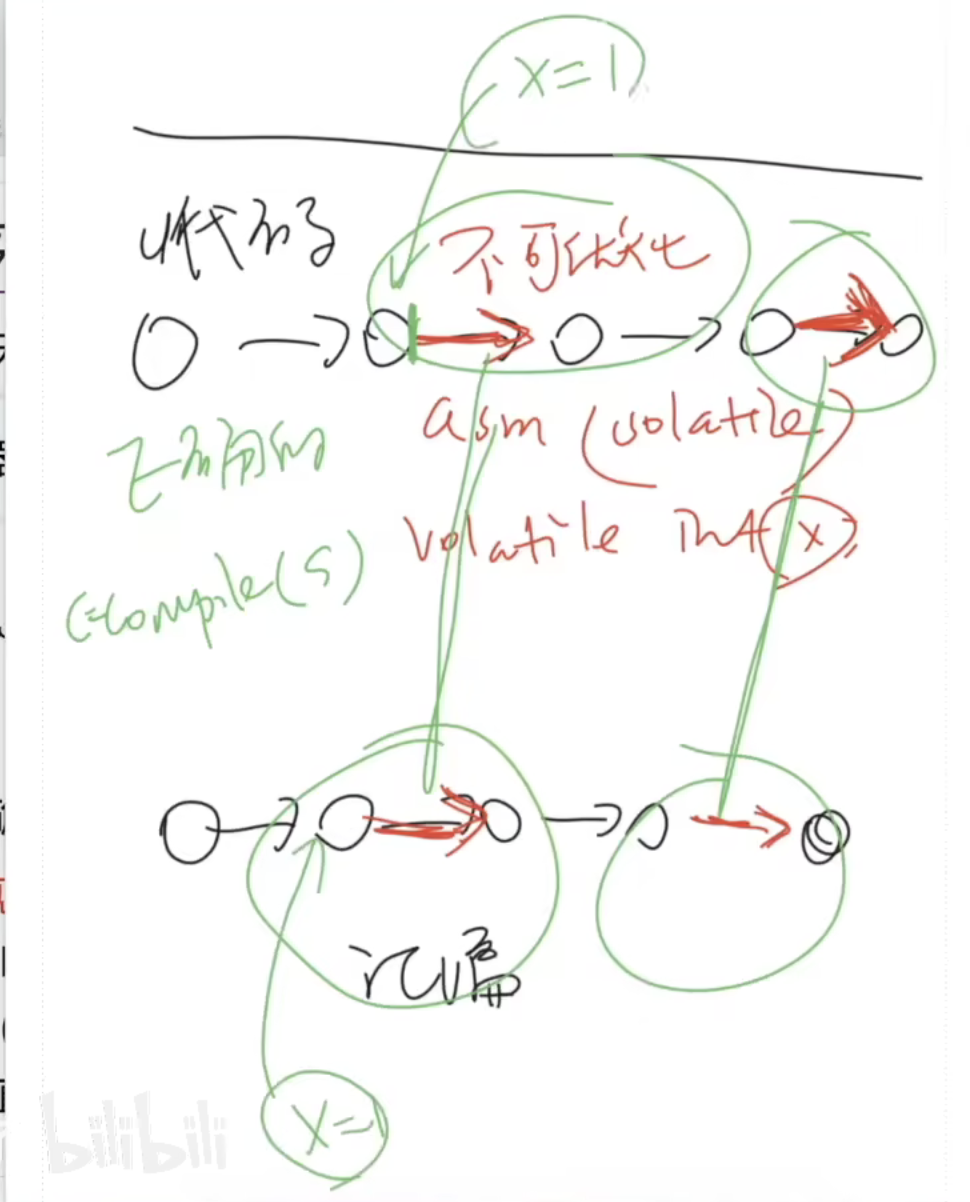
这里的编译正确性 类比 并发的正确性
syscall 收编了所有的api,操作系统= syscall + syscall 定义的api
need 重复操作一遍,第二节课
main() 之前发生了什么?
strace
todo:杀人面试题
状态机是一个严谨的数学对象。计算机系统不存在玄学;一切都建立在确定的机制上


第一周阅读材料
虚拟化(virtualization)、并发(concurrency)、持久性(persistence)
crux of problem
操作系统是什么?
jyy:硬件视角、程序视角、数学视角?
ostep:虚拟化,将物理资源转化为虚拟形式(虚拟机)。提供了api,提供了一个标准库。虚拟化实现了资源共享,资源管理器。
虚拟化cpu,单个物理cpu,似乎可以同时运行多个程序
虚拟化内存
并发
持久化
操作系统,将物理资源虚拟化,处理并发,并持久的存储文件。
target:
- 实现功能的基础上,提供高性能的同时最小化操作系统的开销。
- protection & isolation
一些库-> 超越库 -> 并发多个程序
AbstractMachine
图灵机 就是 状态机? 编程语言?

图灵机的可计算性 -> 如何制造?
ENIAC:用电子管实现状态机,然后读取数据,状态流转。
von neumann:程序也是可以存储起来,可以把状态机的形态存储起来
io出现了
cpu 不能等io:中断

中断处理程序就是操作系统。
分时多线程
分时多线程+虚拟内存 = 进程
c语言运行环境,提供了5组API:
- (TRM)
putch/halt- 最基础的计算、显示和停机 - (IOE)
ioe_read/ioe_write- I/O 设备管理 - (CTE)
ienabled/iset/yield/kcontext- 中断和异常 - (VME)
protect/unprotect/map/ucontext- 虚存管理 - (MPE)
cpu_count/cpu_current/atomic_xchg- 多处理器
linux 文本到执行
question:c程序是如何运行在裸机上的?如何从文本文件到最终在操作系统上运行起来?如下每一步的细节?
1.生成ELF文件
2.将elf二进制文件加载到指定位置
3.如何将pc跳转到位置不固定的main函数中
编译、链接、加载、运行
$ gcc -c -O2 -o main.o main.c
$ gcc -c -O2 -o say.o say.c
$ gcc main.o say.o
# or
$ ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 \
/usr/lib/x86_64-linux-gnu/crt1.o \
/usr/lib/x86_64-linux-gnu/crti.o \
main.o say.o -lc \
/usr/lib/x86_64-linux-gnu/crtn.o
我们得到了可执行文件。因为宏是在预处阶段被处理了,所以编译时只使用了putchar,没有我们自定义的putch,故不会报错putch 未定义。
now 下一步:加载
简单的归纳:
1.shell - fork
2.exevc 动态链接 & 将pc转移到_start初始化运行环境,最后跳转到main方法
3.print等操作则是系统调用 syscall int
gdb
starti
bt f #backtrace full 查看线程stack
info inferiors #输出当前进程信息
!cat /proc/18137/maps # 打印进程的内存信息 todo 每一段内存 是什么?为什么a.out有四段?
_start
main
执行到_strat时,可以查看maps,已经初始化了stack/heap/lib.c/a.out : 完全看不出那是哪儿 😂
Breakpoint 1, 0x0000555555555080 in _start ()
(gdb) !cat /proc/18490/maps
555555554000-555555555000 r--p 00000000 fc:03 1570637 /learn/os/os-workbench-2022/L0/ud_abs/a.out
555555555000-555555556000 r-xp 00001000 fc:03 1570637 /learn/os/os-workbench-2022/L0/ud_abs/a.out
555555556000-555555557000 r--p 00002000 fc:03 1570637 /learn/os/os-workbench-2022/L0/ud_abs/a.out
555555557000-555555558000 r--p 00002000 fc:03 1570637 /learn/os/os-workbench-2022/L0/ud_abs/a.out
555555558000-555555559000 rw-p 00003000 fc:03 1570637 /learn/os/os-workbench-2022/L0/ud_abs/a.out
7ffff7d87000-7ffff7d8a000 rw-p 00000000 00:00 0
7ffff7d8a000-7ffff7db2000 r--p 00000000 fc:03 132514 /usr/lib/x86_64-linux-gnu/libc.so.6
7ffff7db2000-7ffff7f47000 r-xp 00028000 fc:03 132514 /usr/lib/x86_64-linux-gnu/libc.so.6
7ffff7f47000-7ffff7f9f000 r--p 001bd000 fc:03 132514 /usr/lib/x86_64-linux-gnu/libc.so.6
7ffff7f9f000-7ffff7fa0000 ---p 00215000 fc:03 132514 /usr/lib/x86_64-linux-gnu/libc.so.6
7ffff7fa0000-7ffff7fa4000 r--p 00215000 fc:03 132514 /usr/lib/x86_64-linux-gnu/libc.so.6
7ffff7fa4000-7ffff7fa6000 rw-p 00219000 fc:03 132514 /usr/lib/x86_64-linux-gnu/libc.so.6
7ffff7fa6000-7ffff7fb3000 rw-p 00000000 00:00 0
7ffff7fbb000-7ffff7fbd000 rw-p 00000000 00:00 0
7ffff7fbd000-7ffff7fc1000 r--p 00000000 00:00 0 [vvar]
7ffff7fc1000-7ffff7fc3000 r-xp 00000000 00:00 0 [vdso]
7ffff7fc3000-7ffff7fc5000 r--p 00000000 fc:03 131486 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffff7fc5000-7ffff7fef000 r-xp 00002000 fc:03 131486 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffff7fef000-7ffff7ffa000 r--p 0002c000 fc:03 131486 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffff7ffb000-7ffff7ffd000 r--p 00037000 fc:03 131486 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffff7ffd000-7ffff7fff000 rw-p 00039000 fc:03 131486 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
_start 完成初始化后会调用 main(),c程序的初始化由 _start 负责
bare-metal 文本到执行
不是太理解 abstractmachine
先试着阅读下makefile
os-workbench-2022/Makefile
export TOKEN := ???
# ----- DO NOT MODIFY -----
ifeq ($(NAME),)
$(error Should make in each lab's directory)
endif
SRCS := $(shell find . -maxdepth 1 -name "*.c")
DEPS := $(shell find . -maxdepth 1 -name "*.h") $(SRCS)
CFLAGS += -O1 -std=gnu11 -ggdb -Wall -Werror -Wno-unused-result -Wno-unused-value -Wno-unused-variable
.PHONY: all git test clean commit-and-make
.DEFAULT_GOAL := commit-and-make
commit-and-make: git all
$(NAME)-64: $(DEPS) # 64bit binary
gcc -m64 $(CFLAGS) $(SRCS) -o $@ $(LDFLAGS)
$(NAME)-32: $(DEPS) # 32bit binary
gcc -m32 $(CFLAGS) $(SRCS) -o $@ $(LDFLAGS)
$(NAME)-64.so: $(DEPS) # 64bit shared library
gcc -fPIC -shared -m64 $(CFLAGS) $(SRCS) -o $@ $(LDFLAGS)
$(NAME)-32.so: $(DEPS) # 32bit shared library
gcc -fPIC -shared -m32 $(CFLAGS) $(SRCS) -o $@ $(LDFLAGS)
clean:
rm -f $(NAME)-64 $(NAME)-32 $(NAME)-64.so $(NAME)-32.so
os-workbench-2022/Makefile.lab
export COURSE := OS2022
URL := 'http://jyywiki.cn/static/submit-os2022.sh'
submit:
@cd $(dir $(abspath $(lastword $(MAKEFILE_LIST)))) && \
curl -sSLf '$(URL)' && \
curl -sSLf '$(URL)' | bash
git:
@git add $(shell find . -name "*.c") $(shell find . -name "*.h") -A --ignore-errors
@while (test -e .git/index.lock); do sleep 0.1; done
@(uname -a && uptime) | git commit -F - -q --author='tracer-nju <[email protected]>' --no-verify --allow-empty
@sync
Make file 导读
abs的makefile 非常长,但要进行实验还必须得花时间。
makefile 工具
make -nB | grep -v '^mkdir' | vim -
:%s/^/\r
:%s/ /\r /g
%s/learn\/os\/os-workbench-2022\/LAB/pwd /g
:w newfile.txt
:set nu
-I,-D 等编译选项,可以vscode补全,实现正确的跳转。??? how todo? – bear
第二周阅读材料
Todo:汇编中,如何确定 是立即数还是地址? 寄存器的值还是寄存器值对应的地址处的值?
cooperating sequential process:https://www.cs.utexas.edu/~EWD/transcriptions/EWD01xx/EWD123.html
线程
共享数据
不可控调度
原子性
临界区、竞态条件、不确定性、互斥执行
todo:homework
create
join
锁:
lock、unlock、初始化
条件变量:
wait、signal
0x3线程库、现代处理器和宽松内存模型
c语言程序的形式语义?
为什么操作系统要研究并发? 因为操作系统是第一个并发程序!
并发程序的状态机模型:
黑板:共享变量
每个学生:线程私有(stack frame(pc + 局部变量))
状态:全局+线程私有
状态的迁移:线程
人类:单线程,序列化
整个世界:并发
示例:thread.h
#include "thread.h"
void Ta() { while (1) { printf("a"); } }
void Tb() { while (1) { printf("b"); } }
int main() {
create(Ta);
create(Tb);
}
操作系统自动把线程放在不同的cpu上,200%,为何复现不出来,会有只有大概2%。
todo:Thread.h 入门后的。习题 & 练习 进一步配置,设置更大的线程stack。45分钟左右
Stack-probe.c 如何确定每一次递归时占用的stack空间?为什么进行了8192 * 1024次 递归就可以得出 线程的stack空间是8192kB? 即一次递归占用1B的空间?
#include "thread.h"
__thread char *base, *cur; // thread-local variables
__thread int id;
// objdump to see how thread-local variables are implemented
__attribute__((noinline)) void set_cur(void *ptr) { cur = ptr; }
__attribute__((noinline)) char *get_cur() { return cur; }
void stackoverflow(int n) {
set_cur(&n);
if (n % 1024 == 0) {
int sz = base - get_cur();
printf("Stack size of T%d >= %d KB
", id, sz / 1024);
}
stackoverflow(n + 1);
}
void Tprobe(int tid) {
id = tid;
base = (void *)&tid;
stackoverflow(0);
}
int main() {
setbuf(stdout, NULL);
for (int i = 0; i < 4; i++) {
create(Tprobe);
}
}
mov %rax,%fs:0xfffffffffffffff0
mov %fs:0xfffffffffffffff0,%rax
%fs:0xfffffffffffffff0:这部分指定了目标地址。%fs 是一个段寄存器,用于访问特定的内存段。0xfffffffffffffff0 是一个相对 %fs 基地址的偏移量。
线程变量被存储在了特定的段内。
- 创建线程使用的是哪个系统调用? – clone
- gdb 调试多线程:
并发:原子性丧失
传统的状态机模型:程序是一条完整的序列,独占的使用;
单处理器多线程:上下文切换
多处理器多线程:本质是并行的
#include "thread.h"
#define N 100000000
long sum = 0;
void Tsum() {
for (int i = 0; i < N; i++) {
asm volatile("add $1, %0":"+m"(sum));
//sum++;
}
}
int main() {
create(Tsum);
create(Tsum);
join();
printf("sum = %ld
", sum);
}
上面这个例子在单处理器中是正确的,但多处理器不正确? 如何将程序限制到单个处理器上。
todo:
man printf

并发:顺序性丧失
sum o1 或 o2 程度的优化
While(!done) -> if(!done) while(1);
编译器的优化,导致的顺序丧失 -> barrier
共享内存作为线程同步的工具就失效了。
最大的麻烦:内存模型
并发:可见性
todo 理解https://jyywiki.cn/pages/OS/2022/demos/mem-ordering.c done
c语言内嵌汇编
出现了状态机中永远不应该出现的:0 0 😱
计算机体系结构:量化研究方法。有详细讲述乱序执行CAAQA
复习下csapp中 处理器体系结构

开关,导致必须从内存读取,cache miss? right?, print (y) 先于 赋值x = 1 执行。
计算机体系导致的顺序性丧失。
这里的顺序性与可见性的区别是什么?
Todo 内存模型的阅读
奇怪:mem-ordering.c 示例程序并没有表现出 11/00 的情况,几乎全是01,在赋值与打印之间加了usleep(1),勉强出现了01/10. 特别慢,也复现不出来视频中的11/00.
计算机体系结构:量化研究方法
20241115:今天定个小目标,大致理解指令级并行(No.3)。
指令级并行:
1.以前主要通过流水线
2.多指令发射
单核处理器的频率很难再提高后,性能提高由
1.指令级并行
转换为(多核处理器)
2.数据级并行
3.线程级并行
应用程序的并行:
1.数据级并行:同时操作许多数据项
2.任务级并行:并行的方式执行任务
4种方式来开发这2类并行程序
1.指令级并行:流水线
2.向量体系结构和图形处理器:GPU
3.线程级并行
4.请求级并行
流水线基础与中级概念:
RISC指令集的非流水线实现:
- 取指
- 译码
- 执行
- 访存
- 写回
冒险阻碍了指令的完全流水线化:
1.结构冒险:硬件结构,不能满足完全流水线化,例如两条指令某个阶段需要同时操作内存,但处理器只有一个存储器。– 气泡,停顿
2.数据冒险:指令之间存在数据依赖。–转发(流水线内部的数据流转,诸如寄存器重命名)互锁
3.分支冒险:…一系列处理方式,暂时不深入。
关于流水线的具体实现也不再深入。
流水线下的异常处理:csapp中简单介绍了几个基本的原则,此处另一种模型对这些进行了概述。
一个完整的流水线。略过。
CAAQA:中关于流水线的介绍明显更加深入,但当前并没有足够的时间介入其中。
毫无疑问,CAAQA对cpu的描述更加的深入,今晚注定是完成不了的。先理解静态调度,再理解动态调度。还有大概2小时!
流水线重叠指令的执行过程 -> 指令并行
1.硬件动态发现并行
2.软件编译,静态发现并行
一些阻碍并行的原因:
相关:-> 依赖 -> 限制了并行
1.数据相关
2.名称相关 (两条指令使用了相同的寄存器)
对数据冒险的细化:
读了一个旧值
覆盖写
读了一个新值
3.控制相关
对于静态调度:
1.循环展开
2.分支预测
动态调度:重头戏
硬件重新安排指令的执行顺序以减少停顿,并同时保持数据流和异常行为。
显著提高了硬件的复杂度。
简单流水线:指令按照程序顺序发射,一条的停顿,导致后续所有的停顿
一个优化:一条指令在其操作数可用时就立即执行 乱序执行,乱序完成
乱序执行涉及:
数据冒险:错误读取新值、覆盖写
异常处理变得十分复杂:
1.保持逻辑一致性
2.非精确异常(发生异常时的状态与按顺序执行时的状态不一致,后面的指令已经执行了,或者先前的指令还没有执行)
将传统的译码阶段大致细化为:发射(译码&检查结构冒险)+读操作数(直到没有数据冒险就读取操作数)
指令顺序发射,但在读操作数阶段可能停顿或者旁路,从而导致 乱序执行状态。
动态调度的算法: 略
真难。
不过到此为止也能大概理解之前的写x读y & 写y读x 为何会出现00了,因为在当前线程内,x与y不存在数据冒险,故满足乱序执行的条件。单个cpu的动态调度算法无法探知到其他cpu对共享数据的修改!所以并发带来的第三个问题是 不可见,虽然表现形式是顺序丧失。
因为不可见,自然而然引出了内存模型。
memory model
https://research.swtch.com/mm
No1 硬件内存模型
过去:只需要等待下一代处理器,程序就可以跑到更快,-> 硬件以操作系统线程的形式提供多处理器。
单线程中硬件与编译器的许多不可见的优化在多线程中变得不可靠。
//thread1
x = 1;
done = 1;
<br>
//thread2
while(done == 0){}
print(x);
直观上,但thread2 跳出循环时,一定执行了x=1,所以不可能打印出x = 0;
实际是,取决于硬件与编译器。
It depends. It depends on the hardware, and it depends on the compiler. A direct line-for-line translation to assembly run on an x86 multiprocessor will always print 1. But a direct line-for-line translation to assembly run on an ARM or POWER multiprocessor can print 0. Also, no matter what the underlying hardware, standard compiler optimizations could make this program print 0 or go into an infinite loop.
回到前面:并发是反人类直觉的。
硬件内存模型
编程语言内存模型
最开始的内存模型是针对汇编语言的,后来,java/c 开始定义自己的内存模型,内存模型还需要包含编译器。
多处理器的顺序一致性。
我们将前面的问题转化为: 能否在r1 = 1 的情况下,看到r2 = 0?
//thread1
x = 1;
y = 1;
<br>
//thread2
<br>
r1 = y;
r2 = x;
线程各自运行在专用处理器上,编译器不会重排序。
如果满足硬件满足顺序一致性,执行只会有6只可能的结果

如果硬件满足顺序一致性,r1 = 1,r2 = 0 的情况永远不会出现。
对顺序一致性的抽象,可以想象为所有处理器都是直连共享内存:single-use-at-a-time shared memory
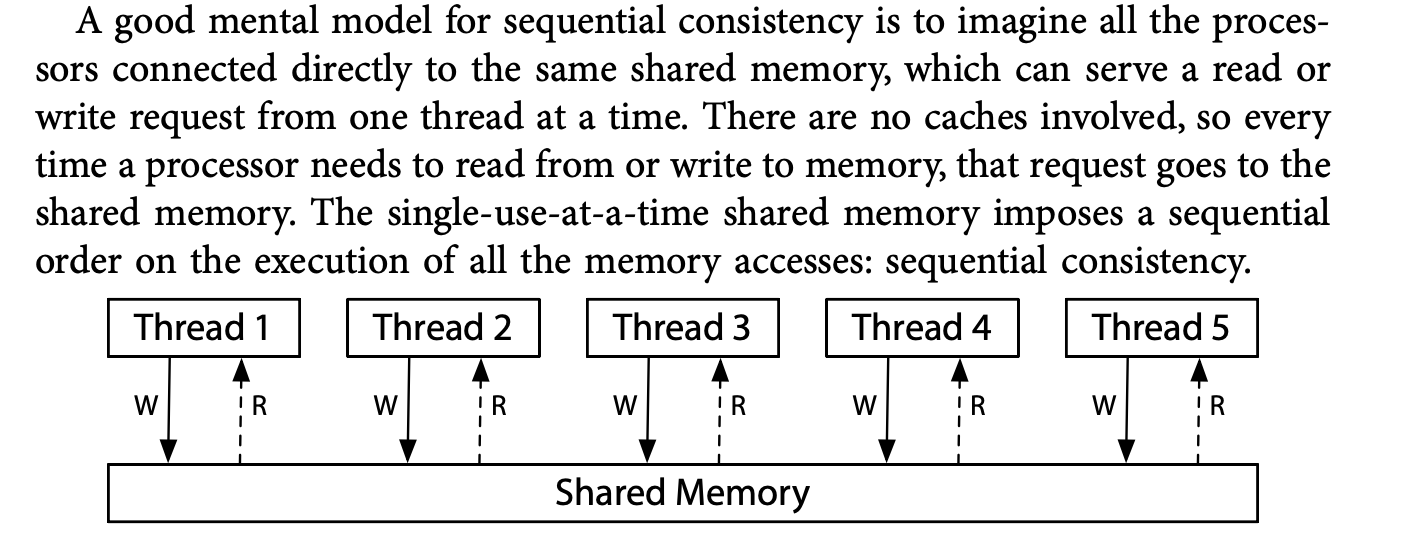
严格的顺序一致性模型,会限制硬件的执行速度。变种之x86
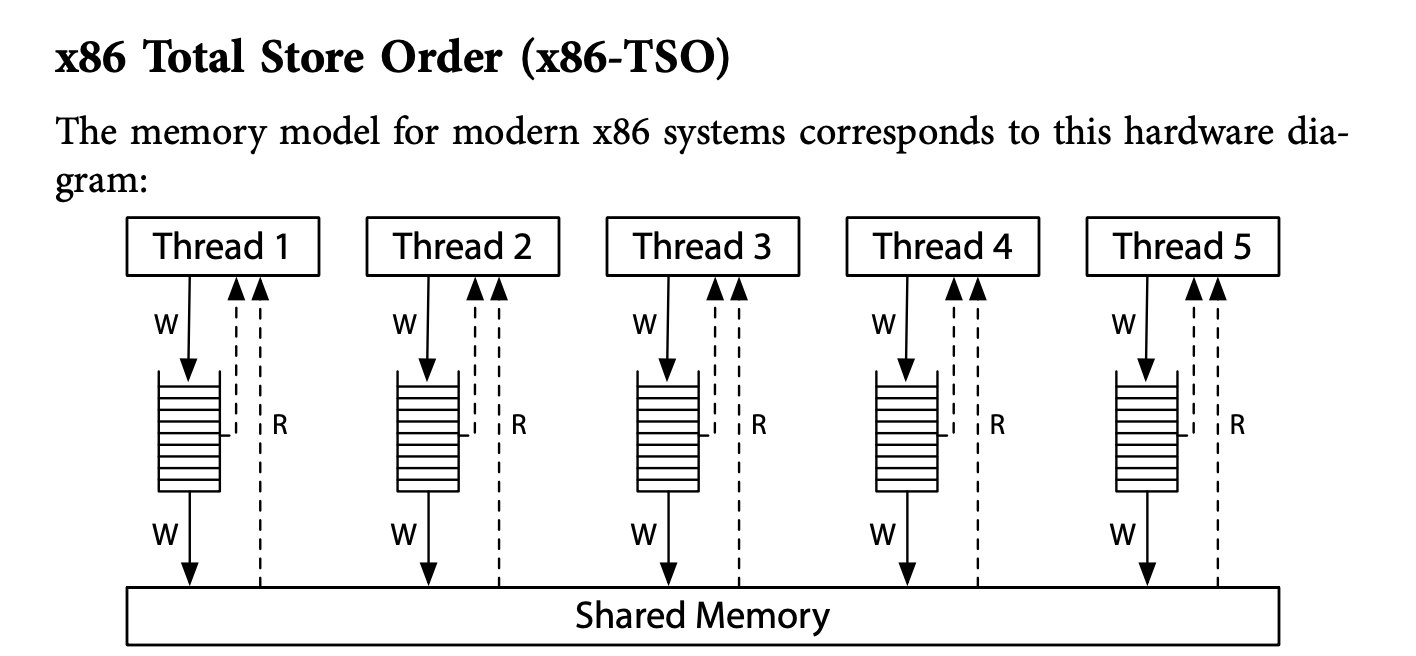
一个写的缓存队列,先进先出,读取数据时优先读本线程写的,然后才是共享内存。为什么叫total store order?
内存一致性模型(如Total Store Order)确保了所有处理器看到的写入操作的顺序是一致的。这意味着,如果处理器P1先执行了写入操作A,然后处理器P2执行了写入操作B,并且P1的写入操作先于P2的写入操作到达共享内存,那么所有处理器都必须按照A先于B的顺序观察到这些写入操作。
P1先写a=1,然后P2再写a=2,但是P2先到达共享内存。上述假设是错误的(会有内存屏障(memory fences)或其他同步机制来避免??),因为TSO内存模型,强调,所有的处理器看到(向buffer里写,其他处理器看不到)的写顺序是一致的,因为p1先写a=1然后p2 再写a=2,所以对所有处理器,一定是先观察到a=1,然后a=2.
x86或其他TSO 内存模型中观察不到 r1=1,r2=0:
1.The write queue guarantees that thread 1 writes x to memory before y;
2.the system-wide agreement about the order of memory writes (the total store order) guarantees that thread 2 learns of x’s new value before it learns of y’s new value;
一个TSO与 顺序一致性差异的例子:
//thread1
x = 1;
r1 = y;
<br>
//thread2
y = 1;
r2 = x;
是否可以看见 r1=0;r2=0
一致性模型:不可能;对x/y 的赋值,一定有一个先执行,后面读取时一定是读取的更新后的值。
X86/TSO:可能,因为有write buffer,从共享内存读取的是初始值。
为了解决上述问题,一般程序提供 barrier,强制同步。
下面这个例子,可以更好的解释为什么叫Total Store Order
//thread1
x=1;
<br>
//thread2
y=1;
<br>
//thread3
r1 = x;
r2 = y;
<br>
//thread4
r3 = y;
r4 = x;
是否可能:r1=1,r2=0; r3=1,r4=0?
一致性模型与TSO 均不能
r1=1,r2=0 意味对于thread3,x先写。因为TSO,所以对thread4,也一定是x先写。故r4不可能=0;
ARM/POWER Relaxed Memory Model
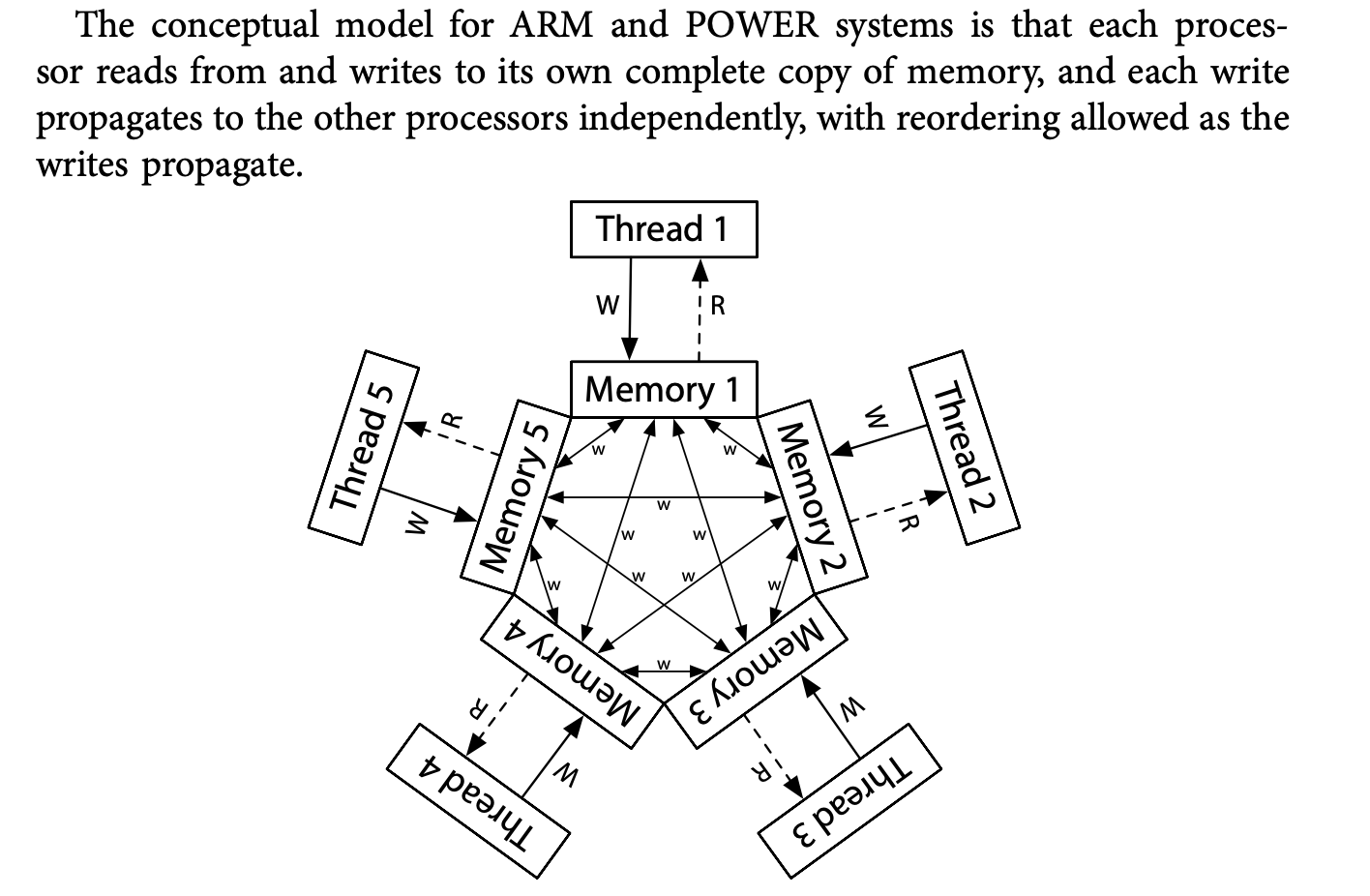
不做任何保障,前面的所有例子都有可能出现。每个处理器都有一个共享变量的副本,但不同处理器之间副本的同步是可以任意排序的!
当我们专注于单个内存位置时,RMM也提供了一定的保障
//thread1
x=1;
//thread2
x=2;
//thread3
r1=x;
r2=x;
//thread4
r3=x;
r4=x;
能否出现r1=1,r2=2 ; r3=2,r4=1?
一致性:no
TSO:no
RMM:no
The answer is no, even on ARM/POWER: threads in the system must agree about a total order for the writes to a single memory location. That is, threads must agree which writes overwrite other writes. This property is called called coherence. Without the coherence property, processors either disagree about the final result of memory or else report a memory location flip-flopping from one value to another and back to the first. It would be very difficult to program such a system.
coherence.
ARMv8 strengthened the memory model by making it “multicopy atomic
最后文章引入了一个新的主题:若排序。发生竞争时,按照一定规则排序。
No2 编程语言的内存模型
Programming language memory models answer the question of what behaviors parallel programs can rely on to share memory between their threads
//thread1
x = 1;
done = 1;
//thread2
while(done == 0){}
printf(x);
程序能否按照预期完成打印出 1?
现代多线程语言(c/java/rust…)的一些通用回答:
1.首先,如果 x 和 done 是普通变量,则线程 2 的循环可能永远不会停止。一种常见的编译器优化是在变量首次使用时将其加载到 register 中,然后尽可能长时间地重用该 register 以供将来访问该变量。如果线程 2 在线程 1 执行之前复制到 done 寄存器中,则它可能会在整个循环中继续使用该寄存器,而不会注意到线程 1 稍后修改了 done 。
2.其次,即使线程 2 的循环确实停止了,在观察到 done=1后,它可能仍会打印 x=0。编译器通常根据优化启发式方法对程序读取和写入进行重新排序,甚至仅根据生成代码时遍历哈希表或其他中间数据结构的方式。线程 1 的编译代码可能最终写入done=1 先于 x =1,或者线程 2 的编译代码可能先print再while 。
Modern languages provide special functionality, in the form of atomic variables or atomic operations, to allow a program to synchronize its threads
原子变量 & 原子操作:
- The compiled code for thread 1 must make sure that the write to
xcompletes and is visible to other threads before the write todonebecomes visible.x=1 先于 done = 1对其他线程可见。
- The compiled code for thread 2 must (re)read
doneon every iteration of the loop.循环中每次都要从内存读取done
- The compiled code for thread 2 must read from
xafter the reads fromdone.当我读到done=1 时一定可以读到 x =1
- The compiled code must do whatever is necessary to disable hardware optimizations that might reintroduce any of those problems.
原子操作/原子变量,需要阻止硬件的优化(乱序执行)
Hardware, Litmus Tests, Happens Before, and DRF-SC
处理器会对指令做新的排序,The gold standard is [sequential consistency](https://research.swtch.com/hwmm#sc), in which any execution must behave as if the programs executed on the different processors were simply interleaved in some order onto a single processor.目前没有重要的架构提供它,因为较弱的保证实现了性能提升
// Thread 1 // Thread 2
x = 1 r1 = y
y = 1 r2 = x
r1=1,r2=0?
On sequentially consistent hardware: no.
On x86 (or other TSO): no.
On ARM/POWER: yes!
In any modern compiled language using ordinary variables: yes!
In a modern language, the reordering that can happen during compilation makes this outcome possible no matter what the underlying hardware
今天的处理去不保证严格的顺序一致性,而是保证“data-race-free sequential-consistency”, or DRF-SC
一个系统要保证无数据竞争的顺序一致性,需要提供synchronizing instructions 用于在不同处理器上执行的代码之间创建 happen before 关系。
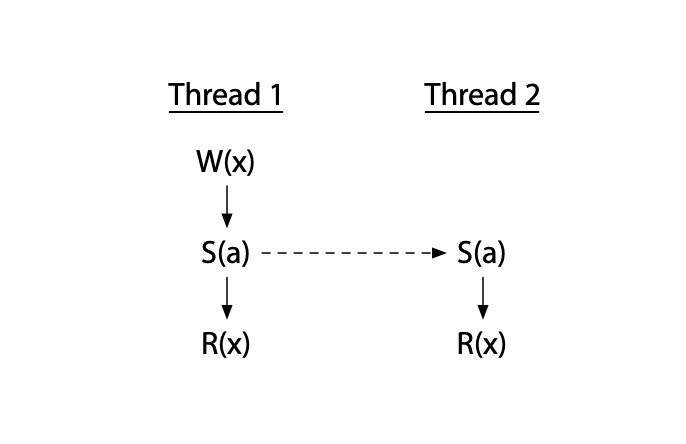
同步指令,用于确保线程1的写 先于线程2的读发生。或者说将线程1写的结果同步给线程2.
Processors that provide DRF-SC (all of them, these days) guarantee that programs without data races behave as if they were running on a sequentially consistent architecture.
编译器优化
It is generally accepted that a compiler can reorder ordinary reads from and writes to memory almost arbitrarily, provided the reordering cannot change the observed single-threaded execution of the code
// Thread 1 // Thread 2 // Thread 3 // Thread 4
x = 1 x = 2 r1 = x r3 = x
r2 = x r4 = x
Can this program see r1=1,r2=2; r3=2,r4=1?
On sequentially consistent hardware: no.
On x86 (or other TSO): no.
On ARM/POWER: no. coherence
In any modern compiled language using ordinary variables: yes!
Original Java Memory Model (1996)
第一版java语言规定:volatile 变量的所有读取和写入都需要直接在主内存中按程序顺序执行
但是volatile变量是 non-synchronizing
int x;
volatile int done;
// Thread 1 // Thread 2
x = 1; while(done == 0) { /* loop */ }
done = 1; print(x);
volatile 确保了,循环一定可以跳出,但因为是非同步的,故编译器还是有可能对 x 和 done 的赋值重新排序
java原始内存模型的另一个缺陷就是:强制一致性。
// p and q may or may not point at the same object.
int i = p.x;
// ... maybe another thread writes p.x at this point ...
int j = q.x;
int k = p.x;
因为其他线程更新了p.x,不能将其优化为:k=i;
New Java Memory Model (2004)
一个data-race-free 的程序,需要同步操作,建立 happens-before ,旨在一个线程写非原子变量时其他线程不会读写该变量。java中同步操作:
- The creation of a thread happens before the first action in the thread.
- An unlock of mutex m happens before any subsequent lock of m.
- A write to volatile variable v happens before any subsequent read of v.
What does “subsequent” mean? Java defines that all lock, unlock, and volatile variable accesses behave as if they ocurred in some sequentially consistent interleaving, giving a total order over all those operations in the entire program. “Subsequent” means later in that total order. That is: the total order over lock, unlock, and volatile variable accesses defines the meaning of subsequent, then subsequent defines which happens-before edges are created by a particular execution, and then the happens-before edges define whether that particular execution had a data race. If there is no race, then the execution behaves in a sequentially consistent manner.
java定义了一个总的顺序,总的顺序定义了Subsequent,通过Subsequent定义了happen-before,happen-before又定义了发生data race 时的具体行为。
// Thread 1 // Thread 2
x = 1 y = 1
r1 = y r2 = x
r1=1,r2=0?
On sequentially consistent hardware: no.
On x86 (or other TSO): yes!
On ARM/POWER: yes!
On Java using volatiles: no.
In Java, for volatile variables
xandy, the reads and writes cannot be reordered: one write has to come second, and the read that follows the second write must see the first write. If we didn’t have the sequentially consistent requirement—if, say, volatiles were only required to be coherent—the two reads could miss the writes.
1.volatile 不会重排序
2.volatile 一定一个先写,一个后写,对后写变量的读时,一定可以看到先写变量更新后的值。
后面是对java内存模型的更深入的讲解,暂时就不了解了。
补充一个相对完成的happen-before:
1.单个线程内,前面 happen before 后面
2.两个线程间,vloatile 变量的写 happen before 后续对其的读
3.一个锁的解锁 happen before 后续对其的加锁
4.thread.start();start前的操作 happen before 新开启的线程
5.join,线程的所有操作,happen before 对该线程的join
6.线程中断
7.对象终结
rule:传递性
c++的内存模型
暂时略过。
0x4理解并发程序的执行

没法保证load 与 store 是原子性的。
peterson 算法。
参考书籍:《The Art of Multiprocessor Programming》
b站有人提到不加barrier为什么peterson-simple 还是会有问题?
与前面的内存模型与可见性有关。如何准确的解释?因为不存在数据冒险,所以先加载进来了共享变量,但共享变量在加载进来后到后续判断使用期间发生了变化。读取了旧值。
todo:之前留下来的内存模型相关文章。
todo:project NEMU实验 PA
python generator = 状态机 ,共享全局变量
转化为 图
程序性质:
Safety Properties: 从任意节点出发,到达不了红色节点
Liveness Properties:从任意状态出发,有限步内到达蓝色/绿色 节点
live lock ? 强联通分量
第三周阅读材料
锁
aha,前面的内容是什么呢?完全不记得这个了呢。
锁的基本思想:一个变量,为程序员提供了最小程度的调度控制。
如何实现锁?需要硬件&操作系统提供哪些支持。
如何评价锁:
- 最基本的互斥
- 公平性,是否有线程被饿死
- 性能,一个线程没有竞争,一个cpu多个线程,多个cpu多个线程。
方案:
interrupt
保证临界区代码不会被中断,🤔,只能用于单处理器。
硬件原语
test-and-set
原子交换
没有硬件支持的基本版本:
typedef struct __lock_t { int flag; } lock_t;
<br>
void init(lock_t *mutex) {
// 0 -> lock is available, 1 -> held
mutex->flag = 0;
}
<br>
void lock(lock_t *mutex) {
while (mutex->flag == 1) // TEST the flag
; // spin-wait (do nothing)
mutex->flag = 1; // now SET it!
}
<br>
void unlock(lock_t *mutex) { mutex->flag = 0;
1.无法实现原子性,两个线程都跳过了while
2.性能差,自旋等待 spin-waiting
test-and-set:
int test_and_set(int *old_ptr, int new) {
int old = *old_ptr;
*old_ptr = new;
return old;
}
通过硬件,原子性的执行上述方法。
解决了上面的获取&设置 的非原子性问题。
正确互斥
没有公平性
性能:单cpu浪费极大,多cpu相对较好
compare-and-swap
int CompareAndSwap(int *ptr, int expected, int new) {
int original = *ptr;
if (original == expected)
*ptr = new;
return original;
}
可用于 wait-free synchronization
如果用于自旋锁 几乎等价 test-and-set
loadlinked - storeconditional
fetch-and-add
question:
自旋过多,太多的线程浪费cpu在while上了。– 操作系统原语:yield
偶然性:一直自旋(浪费),立即让出(饿死)
队列来了。
一段linux 源码:
条件变量
希望线程满足某个条件之后再继续执行
条件变量:一个队列,不满足条件,线程加入队列,条件满足时,线程被唤醒。
P252:调用signal&wait时 最好总是持有锁。
生产者/消费者(有界缓冲区)
生产者把数据放入缓冲区,消费者把数据从缓冲区取走。
信号mesa释义:暗示状态发生了变化,但并不保证对于唤醒的线程状态是其期望的。
因为mesa语义:我们总是用while代替if(wait)。
例子p259:
覆盖条件:广播。唤醒所有正在等待的线程。
信号量
锁
二值信号量
init 1
条件变量
init 0
生产者/消费者
信号量+互斥锁
读写锁
第一个读者获取写锁,最后一个读者释放写锁。读可以并发。
写需要获取写锁。
读者容易饿死写者。
0x5 互斥
互斥的困难:不能同时 读/写 共享内存。
硬件提供原子指令:load & store :https://en.cppreference.com/w/cpp/header/stdatomic.h
void Tsum() {
for (int i = 0; i < N; i++) {
asm volatile("lock addq $1, %0": "+m"(sum));
}
}
x86汇编指令:lock 前缀 确保了原子性&内存屏障
自旋锁:
model-checker spin-lock.py。https://jyywiki.cn/OS/2022/slides/5.slides.html#/2/5
硬件:
lock指令(原子指令),是按照顺序执行的,前一个lock的操作对后续的lock可见。无论有多少个核。原子指令可以理解为串行化,不存在并发。
load
exec
store
X86:缓存一致性 与 lock(80486 总线控制锁)
risc-v:Load-Reserved/Store-Conditional (LR/SC)
标记:reserved
exec
store时,检查标记还在没,一旦标记没了就不执行写入
自旋锁性能影响:
0:原子操作触发缓存同步
1:空转,线程越多,浪费的越多
2:获取锁的线程被cpu切出去了,100%浪费
sum-scalability 线程越多,运行的速度更慢。
除了时间复杂度与空间复杂度外,还有:Scalability
使用场景:

互斥锁:
也叫睡眠锁,通过系统调用,避免切换与自选,没有获取锁的线程直接睡眠。
如何实现长临界区的互斥呢?
把锁的实现放到操作系统,c语言只负责exec。

自旋与睡眠 结合 futex:失败while时,执行系统调用

解决问题,最重要的是理解问题,理解问题最重要的是知道问题的假设;
解决提出问题的人:改变假设。
0x6 同步
线程同步:某个时间点,状态互知
Todo:理解 modelcheck,完成 https://jyywiki.cn/OS/2022/slides/6.slides.html#/1/4
生产者/消费者
条件变量
If -> while
万能:while 检测条件变量,+ broadcast
只有一个单位资源的时候,使用信号量比较合适。
Todo:有意思🤔 条件变量作业 https://jyywiki.cn/OS/2022/slides/6.slides.html#/2/6
哲学家吃饭问题:
每个叉子上锁+先左手再右手=死锁
书中:以为顺序修正
ppt:
1.万能,一把锁,哲学家获取了锁才能尝试拿叉子。
2.生产者/消费者:一个waiter。
定律:Premature optimization is the root of all evil (D. E. Knuth)
Job queue 可以实现几乎任何并行算法
第四周阅读材料
29并发数据结构
Crux:如何添加锁到数据结构
数据结构->线程安全 :1.正确性,2.效率
计数器
简单拓展:加锁的计数器
效率测试:理想状态=多线程运行的与单线程同样快
懒惰计数器sloppy counter:
多个局部计数器,一个全局计数器,阈值 控制局部与全局之间的同步。
并发链表
简单实现:一个链表一个锁
拓展:hand-over-hand lock(lock coupling) 过手锁(耦合锁),链表每个节点一个锁
并发队列
并发散列表
Take-away message
先用一把大锁,实现正确的同步,直到遇到性能问题,再去优化到满足需求。
32常见并发问题
非死锁缺陷
- 违反原子性,一个线程访问,一个线程设置,却没有锁
- 违反顺序性,一个线程创建,一个线程访问。条件变量
死锁缺陷
产生死锁的四个条件:
- 互斥
- 持有并等待
- 不可被抢占
-
循环等待
-
循环:全序、偏序 ? 锁的地址来确定加锁顺序
-
持有并等待:更大的锁,不适用封装
-
不可被抢占:trylock 注意活锁
-
互斥:无锁数据结构
- 通过调度避免死锁,Dijkstra 银行家算法。
- 允许死锁,发生时再恢复
TOM WEST定律:不要总是完美,不是所有值得做的事情都值得做好。
33基于事件的并发
Crux :不用线程,如何构建并发服务器
1.等待某事发生
2.检查事件类型
3.处理事件
事件循环:
while (1) {
events = getEvents();
for (e in events)
processEvent(e);
}
处理程序:系统唯一活动,非并发
调度:显示决定接下来处理那件事
Key:不允许处理某个事件时发生阻塞调用。
基于事件的问题:
- 异步IO:处理:发起io请求后立即返回,提供 其他函数检测io请求是否已经处理完/unix signal
- 状态管理:发出异步IO时,打包程序状态,以便IO处理完后使用。手工管理stack。
- 其他问题:单cpu转向多cpu时,必须要并发。与业务高度耦合。
0x7真实世界的并发
高性能计算中的并发
LCS:Longest Common Subsequence。kmp
任务分解:
计算图 并行化
- 任务如何分配到线程
- 线程间如何交互
示例 https://jyywiki.cn/pages/OS/2022/demos/mandelbrot.c
数据中心里的并发
在服务海量地理分布请求的前提下
- 数据要保持一致 (Consistency)
- 服务时刻保持可用 (Availability)
- 容忍机器离线 (Partition tolerance)
一台计算机的并发
关键指标:QPS, tail latency
线程:资源开销大
协程:一旦block阻碍整个线程
go:Goroutine概念上是线程,实际是线程和协程的混合体
一个cpu一个线程,线程下面无数协程,一旦block,立刻yeild,几乎100%占用cpu,cpu上都没有线程切换
原子操作 -> 条件变量 -> 任何并发算法
go:

单线程+事件模型
promise流程图
0x8并发bug及应对
软件:需求在数字世界的投影。
bug多:编程语言的缺陷,只管 “翻译” 代码,不管和实际需求 (规约) 是否匹配。投影的过程,许多信息丢失了
始终假定自己的代码是错的,不停的去证明。
多assert,相互印证
死锁:
spinlock:aa,还没释放锁,程序中断了,处理程序也需要该锁。加锁后如何避免中断?
abba:顺序
理解 https://jyywiki.cn/pages/OS/2022/demos/spinlock-xv6.c
todo lockdep 检测死锁
todo Thread Sanitizer 检测数据竞争
这一部分:放弃–不要总是完美,不是所有值得做的事情都值得做好。
动态程序分析。动态分析工具:Sanitizers https://jyywiki.cn/OS/2022/slides/8.slides.html#/5/5
gcc 编译选项
0x9操作系统的状态机模型
普通的c程序,由操作系统负责加载然后执行,操作系统也是程序,它又由谁加载?
todo:全系统模拟器是什么?
最小c代码:minimal.S
1.如何把这段代码加载进入内存?
2.必须要提供类似于systemcall 之类的方法
软硬件的约定:
概念:cpu state:各种寄存器
reset后,pc一定指向某个地方
软件与硬件连接:cpu reset 后pc 指向一条有效的指令。

X86: 一般reset 后pc 指向0xffff0(指向固件上一段程序的跳转指令,电脑启动运行的第一个软件)
firmware:
1.扫描硬件
2.找到有操作系统的硬件
3.加载操作系统,剩余一切,交给操作系统
bios/uefi
legacy bios:
1.约定:启动磁盘的前512字节=MBR(master boot record)
2.由firmware 将其搬到物理内存的0x7c00(firmware 与操作系统的第一次也是唯一一次握手)。
此时状态:

qemu,查看启动过程的代码:0x9 42分钟。
在hello镜像目录新增bootloader.gdb
target remote localhost:1234
break *0x7c00
新增shell 脚本
#!/bin/bash
qemu-system-x86_64 \
-machine accel=tcg \
-S -s \
-drive format=raw,file=./hello-x86_64-qemu &
pid=$!
gdb -x bootloader.gdb; kill -9 $!
wa *0x7c00
x/10i ($cs*16 + $rip)
x/16xb 0x7c00
查看镜像
vi hello-x86_64-qemu
%!xxd #转成16进制阅读,内存0x7c00 处的代码真的就是跟镜像一致!
前面讲了启动加载:初始化操作系统状态机
传奇黑客:qemu ffmpeg
操作系统:
reset -> bios -> bootloader -> main
《操作系统真象还原》
todo:理解thread-os.chttps://jyywiki.cn/pages/OS/2022/demos/thread-os.c
hard
mpe_init(mp_entry);//给每个cpu运行mp_entry,初始化进程空间,设置好pc? 那么此时运行main的这个cpu呢?
cpu(reset) -> bios ->bootloader ->main
操作系统的状态机模型:
1.mpe_init 之前的全局状态+每个cpu的寄存器被mp_entry初始化之后的状态
2.然后操作系统可以选择cpu1执行,或者cpu2执行…
中断:将当前cpu寄存器状态暂存,然后运行中断处理程序
0xA状态机模型的应用
https://jyywiki.cn/pages/OS/2022/demos/ilp-demo.c
可以测试cpu 实际1s能执行多少指令。
amazing:
程序是状态机,初始状态+指令(确定性的指令)= 一定可以复现过程
一般复杂程序还有一类:rdrand / systemcall 等不确定性的指令,如何复现呢? – 只需要记录其结果
经过n条确定性指令,执行不确定性指令a的到结果b。记录:初始状态+指令(确定性)+(指令数+结果)=复现
Record & replay:


linux profile:
Linux Kernel perf (支持硬件 PMU) - ilp-demo.c
- perf list, perf stat (-e), perf record, perf report
model checker
一些真正的 model checkers
- TLA+ by Leslie Lamport;
- Java PathFinder (JFP) 和 SPIN
KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs
约束求解器