操作系统_持久化
0x16速通
0x17存储设备原理
最早:Delay line,绳子,需要放大
然后:Magnetic core 磁芯内存。带来了概念 core dump (内存 dump 到一个外部设备上)
今天基本没有了
ulimit -a
real-time non-blocking time (microseconds, -R) unlimited
core file size (blocks, -c) 0 # 因为太容易崩溃了🤣
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 6391
max locked memory (kbytes, -l) 214148
max memory size (kbytes, -m) unlimited
open files (-n) 65535
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 6391
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited

可以gcc a.out core:将core再搬到内存
1.逻辑上存储设备就是一个巨大的 bit/byte array
2.局部性允许我们,按大块去读写
磁
磁带
磁鼓
磁盘
磁盘也有调度算法:电梯调度书法
现在磁盘也是带有soc的,调度算法由os下放到了磁盘本身
cat /sys/block/vda/queue/scheduler
[mq-deadline] none
mq-deadline:优先读,写不至于饿死
none:没有调度算法,来就写入磁盘
坑
光盘
磁盘&光盘 避免不了机械部件
电
要快:电
想办法让电持久化
Flash Memory:越大越快
http://xiaqunfeng.cc/2023/07/02/ssd-all-flash-FTL/
FTL: Flash Translation Layer
未来:
软件包:定义了软件的初始状态
如果数据不会丢失了,可以将软件的某个中间状态存储下来,不再发布软件的初始状态,直接发布快照,中间状态。
take-away message
- Q: 状态机的状态和持久的状态是如何存储的?
- 1-Bit 信息的存储
- 磁 (磁带、磁盘)、坑 (光盘)、电 (Flash SSD)
- 构成性格各异的存储设备
- 重新思考 “状态的存储”
- NVM 来了:主存的机器状态不会断电丢失
- 但寄存器/缓存依然是 volatile 的
- 计算机系统是否会经历彻底的 “重新设计”?
- Operating system implications of fast, cheap, non-volatile memory (HotOS’13)
0x18输入输出设备模型
串口,终于到了一直疑惑的地方了
- Operating system implications of fast, cheap, non-volatile memory (HotOS’13)
- NVM 来了:主存的机器状态不会断电丢失
- 计算机与外设的接口
- 总线、中断控制器和 DMA
- GPU 和异构计算
io:一组功能定义好的线。线-寄存器。一组交换数据的接口与协议
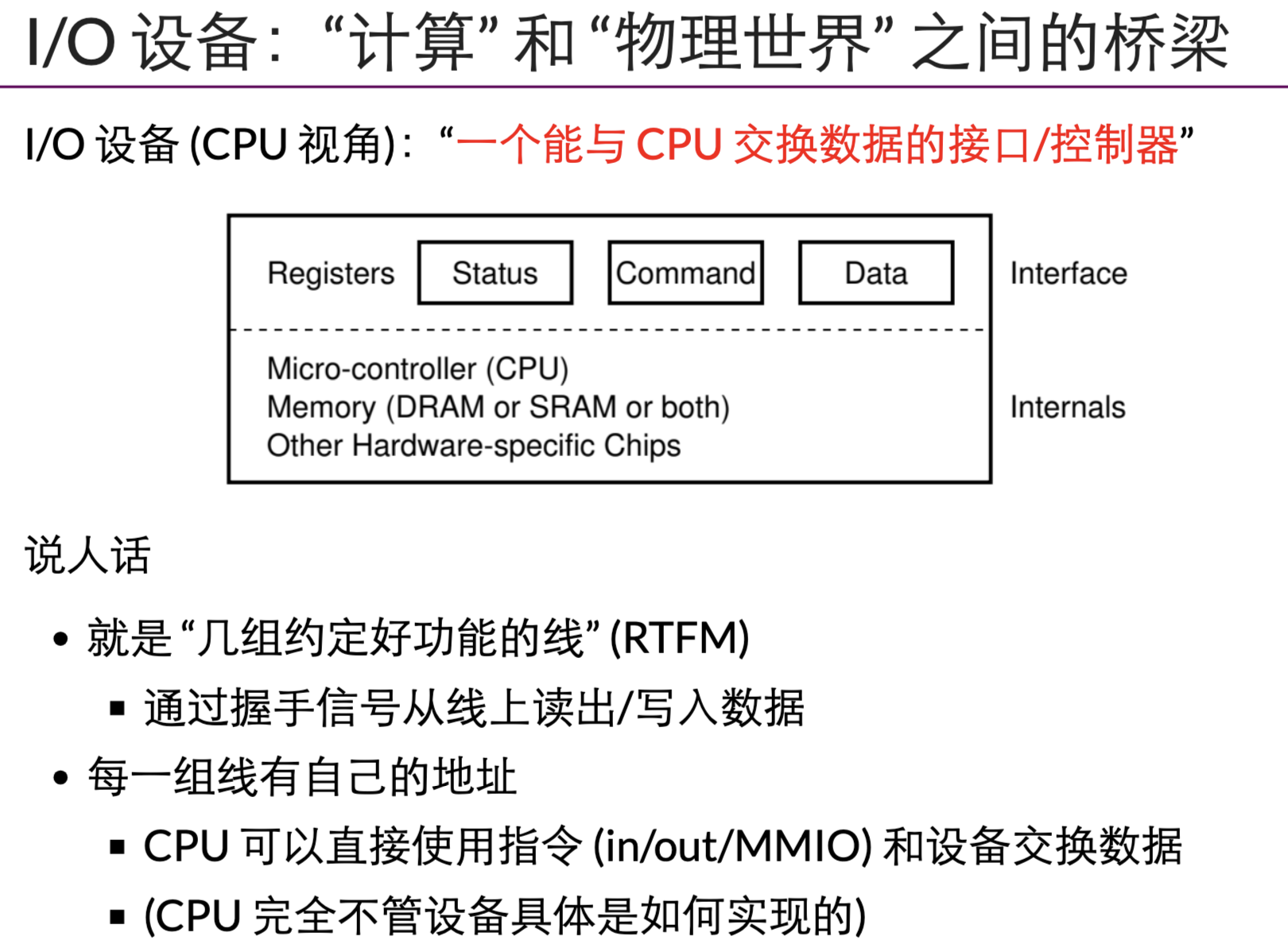
cpu与io设备之间交换:状态、命令、数据
串口:一个地址,可以输入/输出数据流
```c #define COM1 0x3f8 // status、command、data static int uart_init() { outb(COM1 + 2, 0); // 控制器相关细节 outb(COM1 + 3, 0x80); outb(COM1 + 0, 115200 / 9600); … }
static void uart_tx(AM_UART_TX_T *send) { outb(COM1, send->data); //向寄存器传输数据(一般还要等设备就绪) }
static void uart_rx(AM_UART_RX_T *recv) { recv->data = (inb(COM1 + 5) & 0x1) ? inb(COM1) : -1;//先读取状态,有数据,再从寄存器读 }
<br>
磁盘驱动:
<br>
```c
void readsect(void *dst, int sect) {
waitdisk();//等待磁盘就绪
out_byte(0x1f2, 1); // sector count (1)
out_byte(0x1f3, sect); // sector
out_byte(0x1f4, sect >> 8); // cylinder (low)
out_byte(0x1f5, sect >> 16); // cylinder (high)
out_byte(0x1f6, (sect >> 24) | 0xe0); // drive
out_byte(0x1f7, 0x20); // command (write) 向寄存器0x1f7 写入0x20(读取命令)
waitdisk();//等待磁盘准备完成
for (int i = 0; i < SECTSIZE / 4; i ++)
((uint32_t *)dst)[i] = in_long(0x1f0); // data 从数据端口不停的读取
}
由于设备的复杂性,大部分简化为了寄存器。
打印机:
-postscript
https://jyywiki.cn/pages/OS/2022/demos/page.ps
语言-编译器-打印机
总线
与设备交互,抽象成与指定的寄存器交互。Q:寄存器难道不冲突?
早期没有总线的时代,默认计算机是一个封闭的设备,将所有的io设备寄存器统一编号,链接至mux,调用那个设备就向指定的唯一编号的寄存器交互。
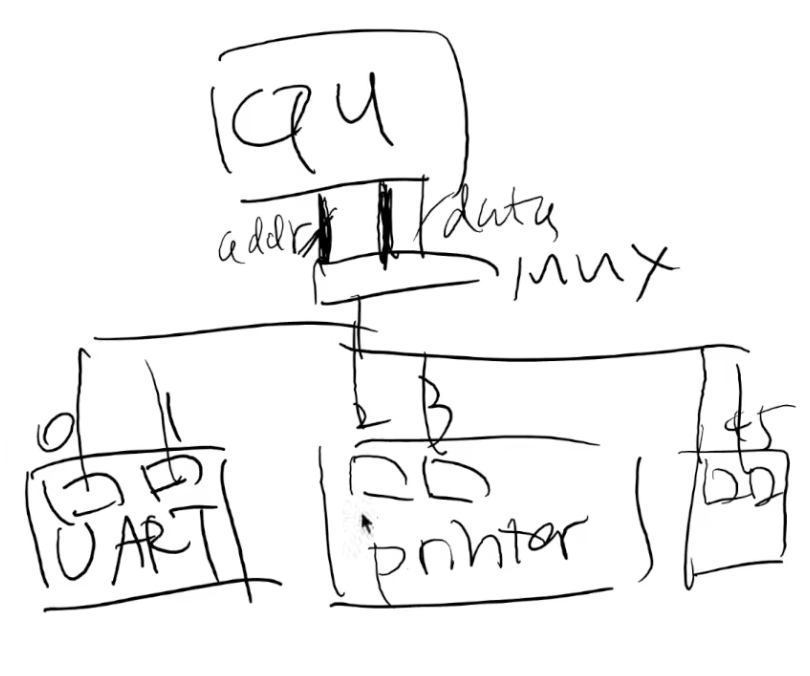
如果你只造 “一台计算机”
- 随便给每个设备定一个端口/地址,用 mux 连接到 CPU 就行
- 你们的实验 (AbstractMachine) 和自制 CPU 就是这么做的
but IO越来越多,如何在CPU 不动的情况下,连接越来越多的IO设备?
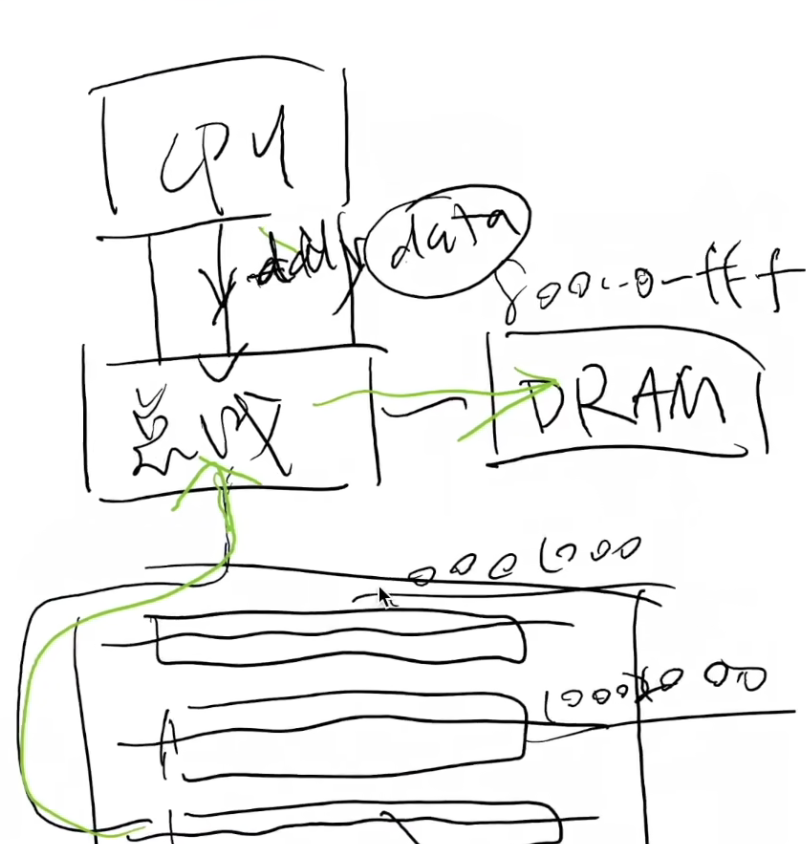
cpu只与总线交互,总线直接与具体的设备交互(我要获取第3个插槽的第6个寄存器的值)。(没有什么是抽象一层解决不了的🤣);
进一步,将所有的设备统一到地址空间:DARM(0x800~0xfff)设备(0x101,0x102….)等
总线:一个特殊的 I/O 设备
提供设备的注册和地址到设备的转发
- 你们的实验 (AbstractMachine) 和自制 CPU 就是这么做的
- 把收到的地址 (总线地址) 和数据转发到相应的设备上
- 例子: port I/O 的端口就是总线上的地址
- IBM PC 的 CPU 其实只看到这一个 I/O 设备这样 CPU 只需要直连一个总线 就行了!
- IBM PC 的 CPU 其实只看到这一个 I/O 设备这样 CPU 只需要直连一个总线 就行了!
- 今天 PCI 总线肩负了这个任务
- 总线可以桥接其他总线 (例如 PCI → USB)
- 总线可以桥接其他总线 (例如 PCI → USB)
-
lspci -tvlsusb -tv- 查看系统中总线上的设备
- 概念简单,实际非常复杂……
- 电气特性、burst 传输、中断……
abm:上查看pci总线上的设备:https://jyywiki.cn/pages/OS/2022/demos/pci-probe.c
中断
cpu除了与IO连接外,还有中断控制器
当前:LAPIC和IOAPIC,IOAPIC处理外部的中断例如IO中断等将其转化为LAPIC信号

IPI:处理核间中断(一个cpu可以给另外的cpu发送中断信号)DMA
除了总线与中断控制器外还有一类IO设备
让cpu不停的将数据搬到总线,太费时间了,单独交给另外一个简化的“cpu”。绕过cpu传输数据

显卡
DMA:一个特殊的专门处理memcopy的cpu
还能不能拥有其他cpu?
在4k的画布上,60fps的频率进行计算每一点的rgb值:NES Picture Processing Unit (PPU) 最早的GPU?
计算几何:任何多边形都可以被分解为多个三角形
数学的方法对物理时间建模
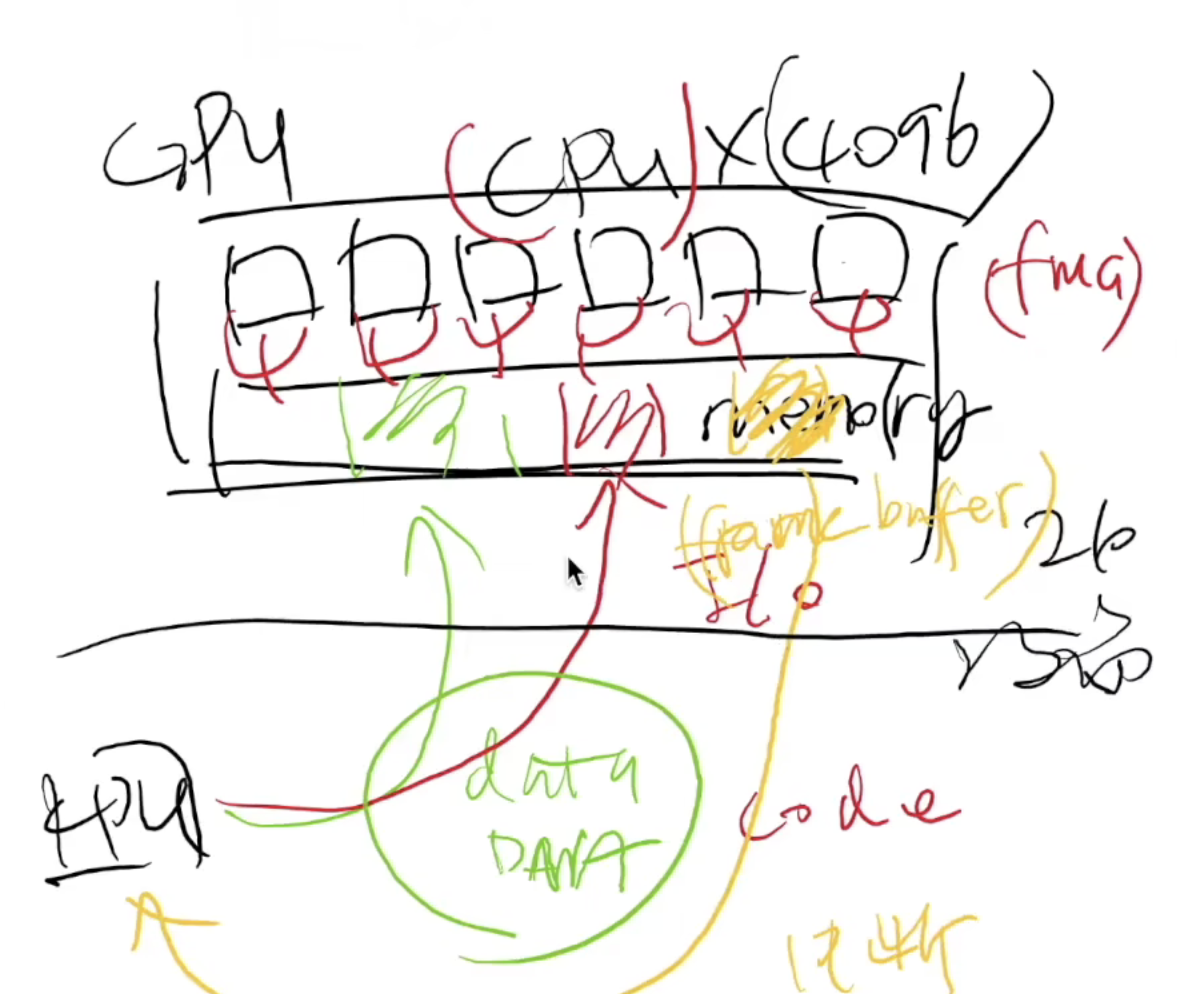
cpu通过DMA将data&程序(GPU认的程序)推送到显存,然后GPU计算输出到显存,然后中断,cpu再将显存计算后的值拿出来 。某种程度GPU是另外一台计算机0x19设备驱动
总线、dma、gpu等
最高层次的抽象:在OS眼里都是【一组寄存器+协议】(一个设备,一个协议)
将寄存器暴露给应用程序:非常不可靠,与危险。
抽象成更高级的API:putch 到 printfIO设备抽象
鼠标,键盘,磁盘等都是IO设备
LInux中设备可以分为:字符设备char… device & 块设备block device;键盘是流设备,磁盘是块设备
I/O 设备的主要功能:输入和输出
- 电气特性、burst 传输、中断……
- “能够读 (read) 写 (write) 的字节序列 (流或数组)”
- 常见的设备都满足这个模型
- 终端/串口 - 字节流
- 打印机 - 字节流 (例如 PostScript 文件)
- 硬盘 - 字节数组 (按块访问)
- GPU - 字节流 (控制) + 字节数组 (显存)
操作系统:设备 = 支持各类操作的对象 (文件)
- read - 从设备某个指定的位置读出数据
- write - 向设备某个指定位置写入数据
- ioctl - 读取/设置设备的状态
驱动:将系统调用翻译成与相关寄存器的交互
抽象的api越简单,设备功能越复杂,驱动越难写
字节流与字节块抽象的缺陷:设备的配置 & 附加附加功能
巨大无比的ioctl(linux 差不多1000w行代码与这个调用相关😱)
linux 驱动
todo:玩一玩minmal,试着在上面运行驱动code for GPU
GPU抽象:SIMT(Single Instruction, Multiple Thread) cpu:取指令,译码,执行
gpu:许多处理器,共享相同的取码,译码,然后各自有自己cache+执行单元(共享PC指针,执行相同的指令)
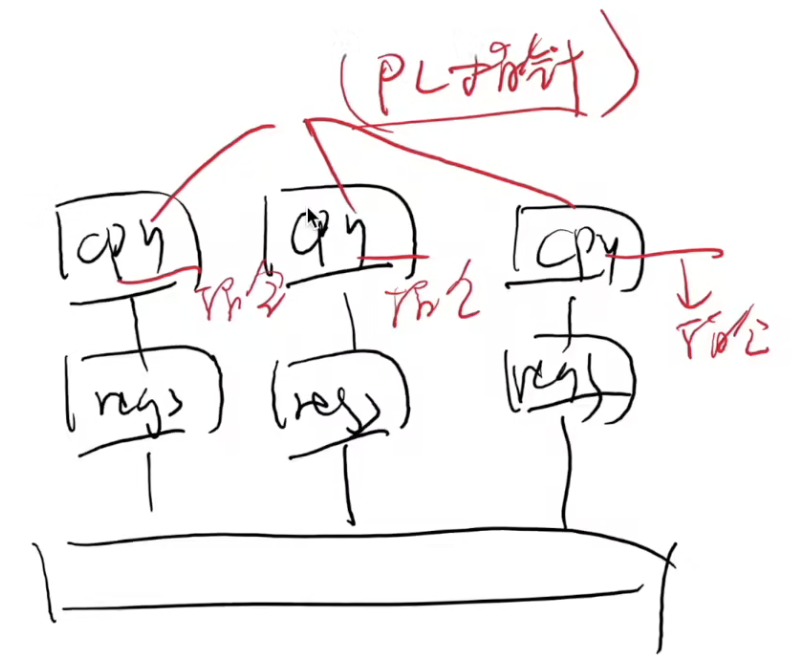
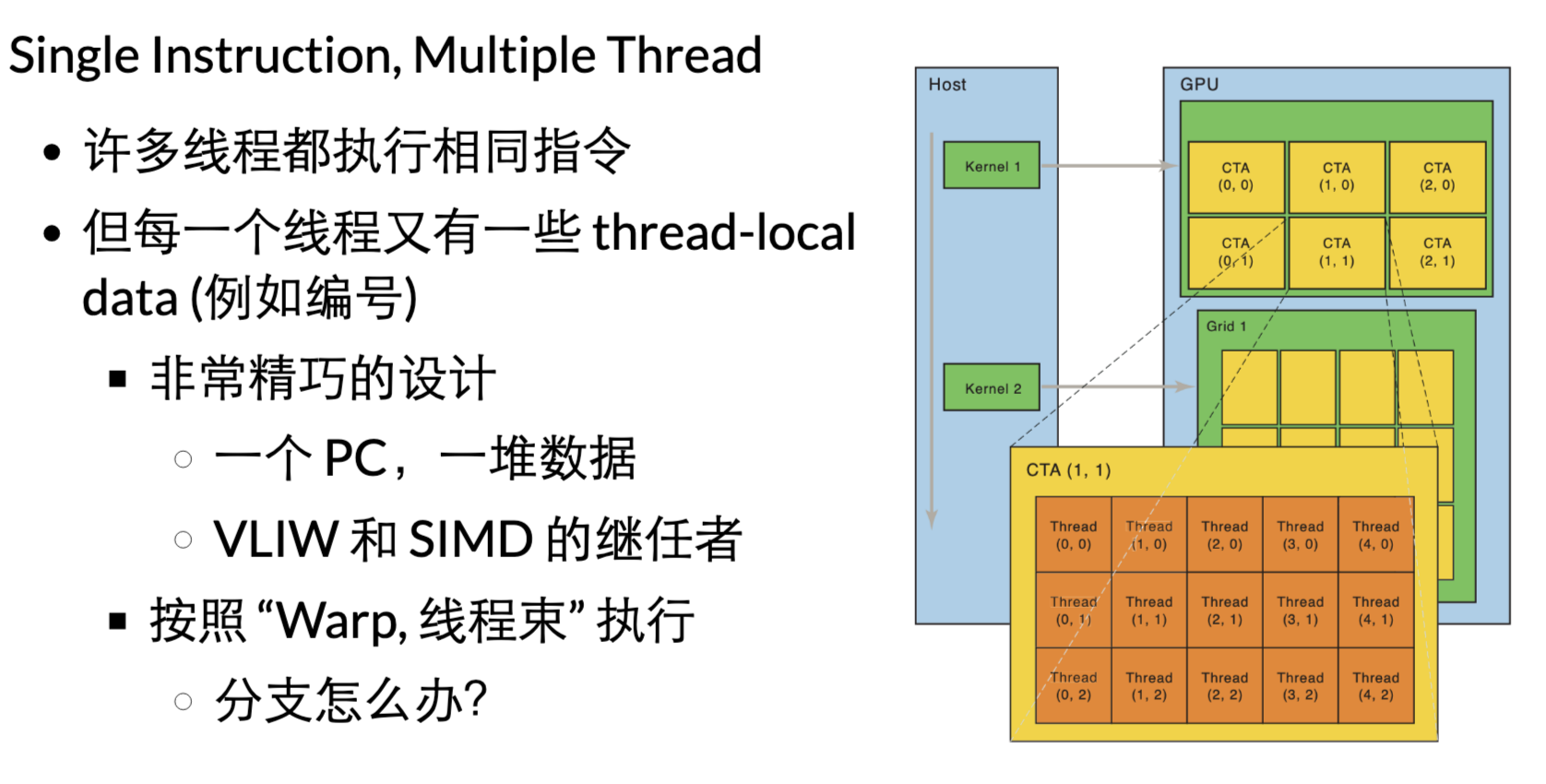
对于condition,编译器优化-展开成没有分支的控制流:同一条指令,因为thread-local数据不一样,实际不同效果
todo:玩一玩,cuda示例程序
cuda:全套工具链

存储设备驱动
应用程序,不访问磁盘,访问的是文件系统
文件系统,提交request给block layer,然后再进行调度
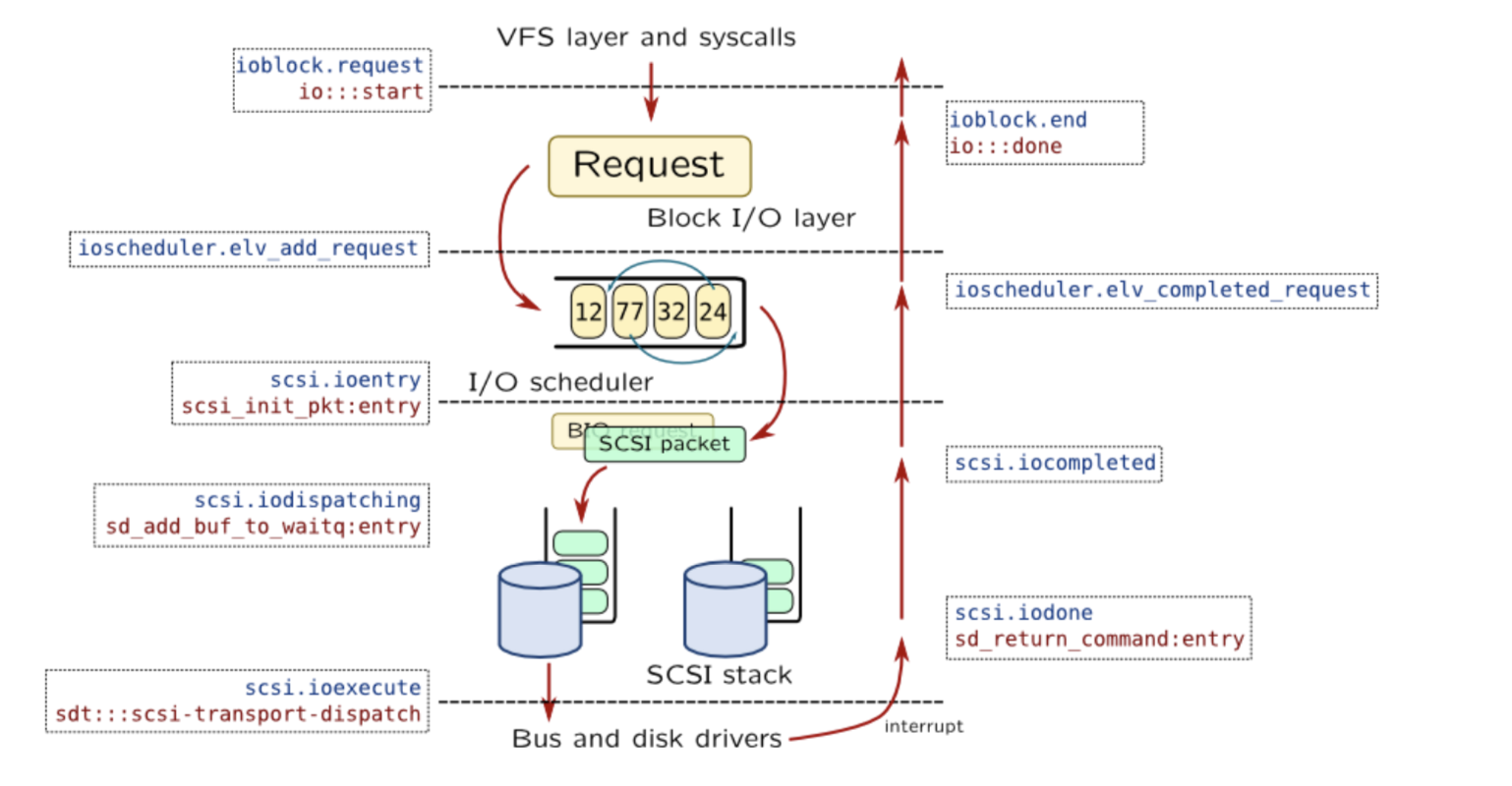


Takeaway messages - 设备驱动
- 把 read/write/ioctl 翻译成设备听得懂的协议
- 字符设备 (串口、GPU) + DMA
- 块设备 (磁盘)
0x1a文件API
多个应用程序共享存储设备
printf 线程安全,多个应用程序并发执行,是安全的
系统只有一个设备,可读,可写,但会涉及到多个应用程序调用同一个设备
cuda:驱动负责调度
write:
磁盘被抽象为block array,对于多个应用程序来说,如何处理竞争?
所有的文件=字节序列
磁盘=字节序列(块)
文件系统,就是一个虚拟磁盘:让每个应用程序以为自己独占整个磁盘?no 是每个文件就是一个虚拟磁盘,应用程序可能涉及多个文件

文件系统就是在磁盘上虚拟出许多的虚拟磁盘(每一个文件就是一个std::vector)
最简单的文件系统:K-V
每一个设备是一个字节序列,设备里面的文件目录实际是虚拟出来了的linux文件系统
mount 系统调用
linux mount
创建设备
目录挂载到设备
switch root

目录根是怎么来的?
文件又是如何挂载上去的?
loopdevice:将文件(.iso.img)模拟成设备,可以像挂载设备一眼挂载文件,对设备的操作被驱动转化为对文件的操作。
linux 启动时如何从内存文件系统切换物理文件系统:
1.initramfs 内存文件系统,加载必要驱动
2.创建目录,将sda磁盘设备mount到某个文件
3.将内存中的/proc等虚拟目录挂载到新磁盘根目录
4.切换跟目录,释放内存文件系统其他资源
磁盘是一个block array,文件就是一堆的虚拟磁盘。
文件系统是一个数据结构,磁盘就是文件系统的物理载体,磁盘也是一个设备。
将sda mount到文件:实际是通过驱动将设备上的文件系统挂载到指定目录目录API
mkdir
rmdir
rm -rf: unlinkat
getdents: 遍历目录
readdir
更友好的api
合适的 API + 合适的编程语言
- Globbing
from pathlib import Path <br> for f in Path('/proc').glob('*/status'): print(f.parts[-2], \ (f.parent / 'cmdline').read_text() or '[kernel]')
这才是人类容易使用的方式 - C++17 filesystem API 那叫一个难用 😂

注意:大部分unix文件系统的所有文件都是硬连接,所以删除叫unlink!
目录是一个特殊文件,存放文件名称与对应inode号
硬连接是一个目录项,不同名称指向同一个inode,删除文件减少inode的引用计数,为0就释放数据。
类似两个指针指向同一个文件(不能硬连接目录,跨文件系统)

软连接则是一个文件了,储存的是文件名称与对应地址
因为软连接无限制:可以成环了…
进程有自己的当前工作目录!pwd
chdir 能修改= cd
cd 时shell自己的命令,没有脚本叫cd
文件系统调用
文件描述符:进程访问文件 (操作系统对象) 的 “指针” - 通过 open/pipe 获得
- 通过 close 释放
- 通过 dup/dup2 复制
- fork 时继承
文件描述符不仅指向文件,还指向一个具体的文件位置。读512后会自动将位置挪到512字节之后(书签就是文件描述符里面的偏移量) read(fd, buf, 512);- 第一个 512 字节read(fd, buf, 512);- 第二个 512 字节-
lseek(fd, -1, SEEK_END);//最后一个字节 //lseek管理文件位置
文件管理的复杂性:https://jyywiki.cn/OS/2022/slides/26.slides.html#/4/4
Takeaway messages - 文件系统的两大主要部分
- 虚拟磁盘 (文件)
- mmap, read, write, lseek, ftruncate, …
- 虚拟磁盘命名管理 (目录树和链接)
- mount, chdir, mkdir, rmdir, link, unlink, symlink, open, …
0x1b FAT 和 ext2/UNIX 文件系统
如何实现文件系统的API
- mount, chdir, mkdir, rmdir, link, unlink, symlink, open, …
- 虚拟磁盘 (文件)
- 目录 (索引)
- “图书馆” - mkdir, rmdir, link, unlink, open, …
- 文件 (虚拟磁盘)
- “图书” - read, write, mmap, …
- 文件描述符 (偏移量)
- “书签” - lseek
只有bread,bwrite 如何实现这一切
文件系统就是一个数据结构,只是其假设与数据结构不同:
数据结构的假设:
1. RAM,地址空间 2. 每条指令执行/字节数据读取都是O(1)的
文件系统假设:
1. 按块访问:读取/写入1字节,不再是O(1)的需要:读一块,再读1字节
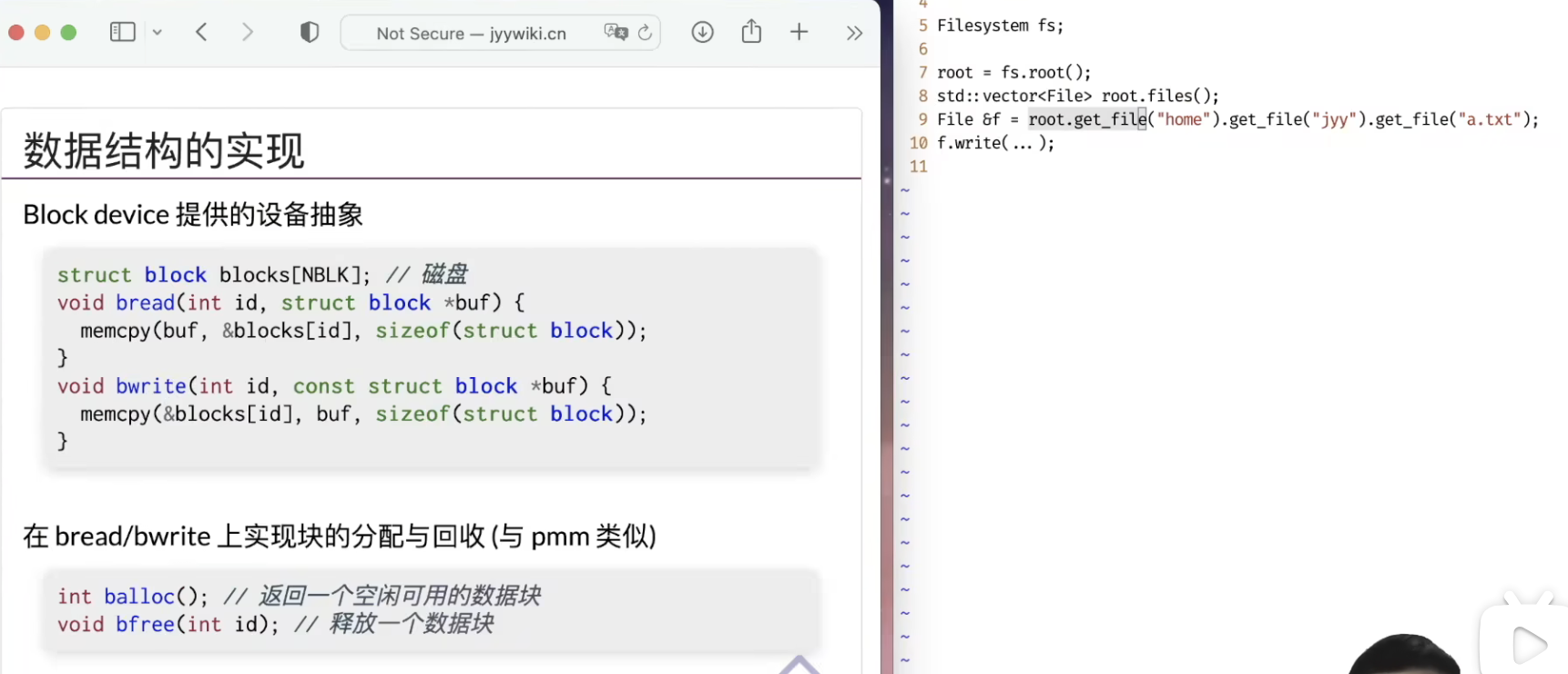
将右边的操作,用左边的api实现
构建一个文件系统
原始:block array
Step1:block set 集合中管理,放入取出 balloc,bfree
Step2:实现虚拟磁盘(文件),一个文件需要多少块就balloc多少块,实现可变长的byte array
Step3:用文件实现目录
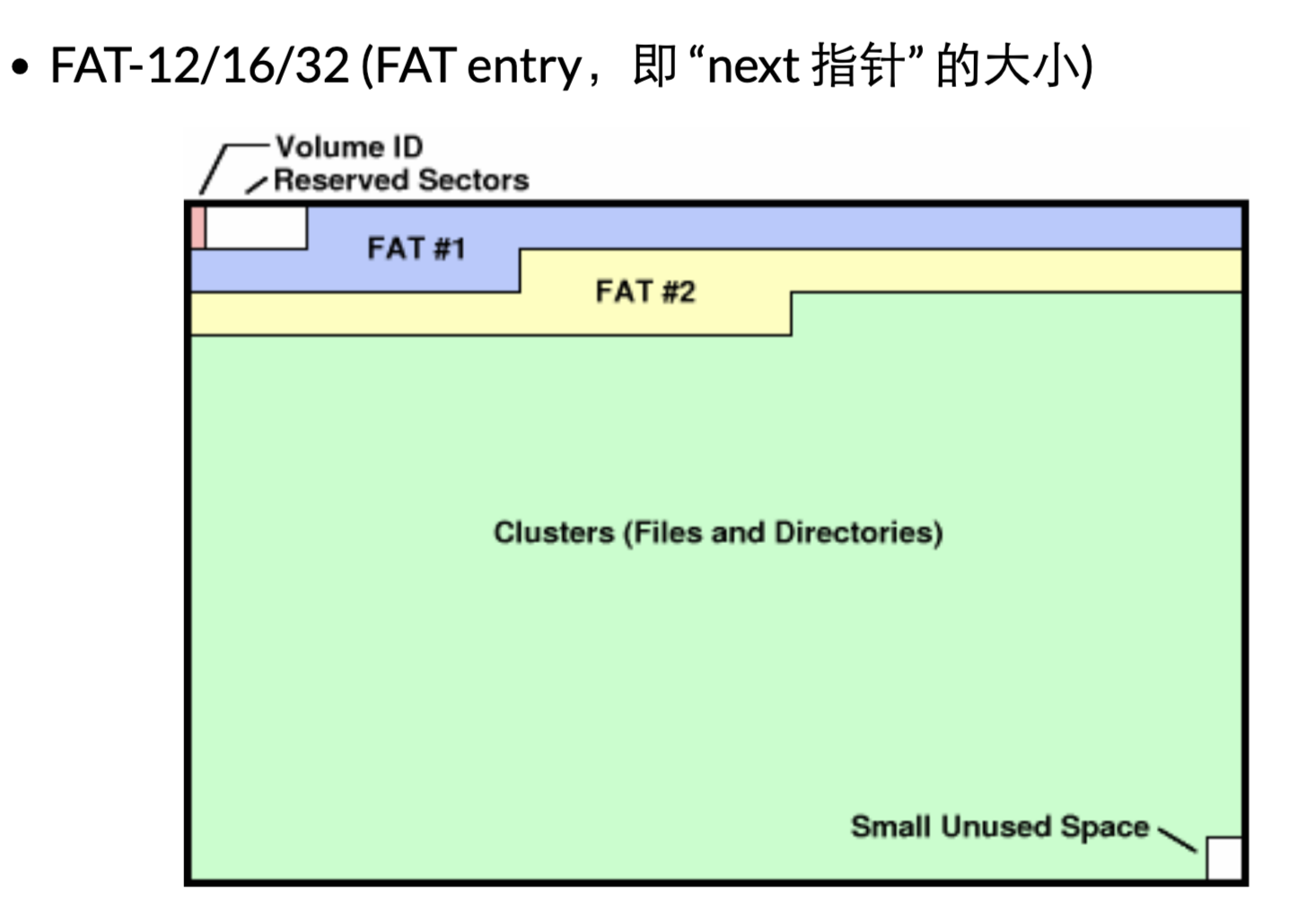
File Allocate Table
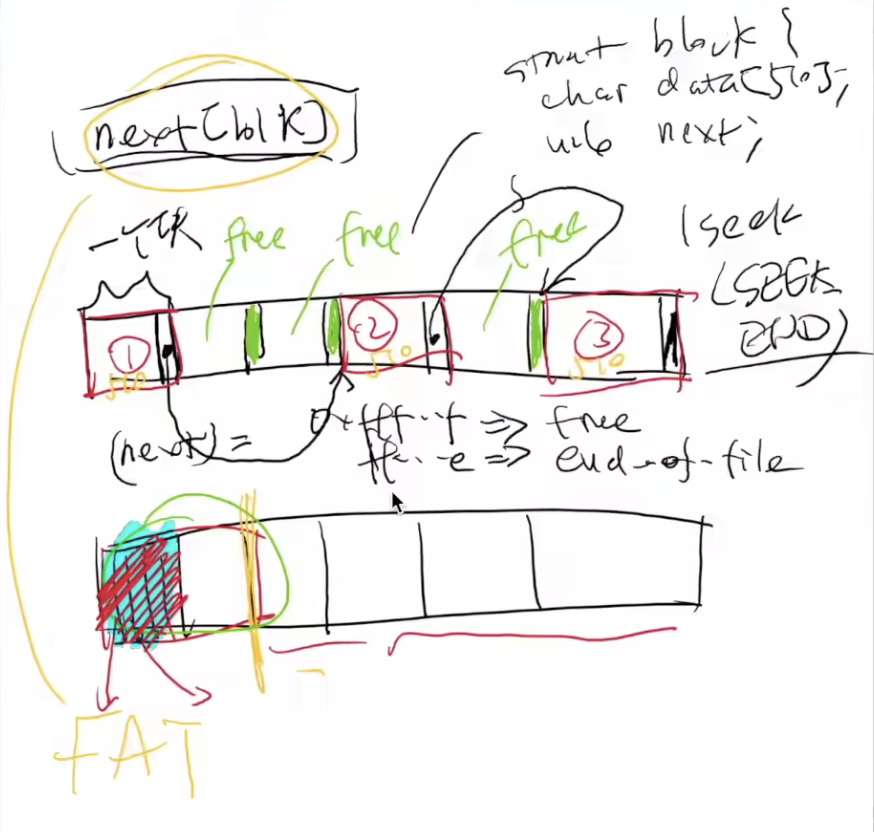
FAT:一块集中的区域存放每一块的指针,指针部分的区域可以多处备份。
RTFM 得到必要的细节
一个fat就是一个next指针数组
mkfs.fat
照抄手册,遍历目录树:fatree.c
todo 玩一玩fat文件系统ext2
fat 适合小文件,链表不长
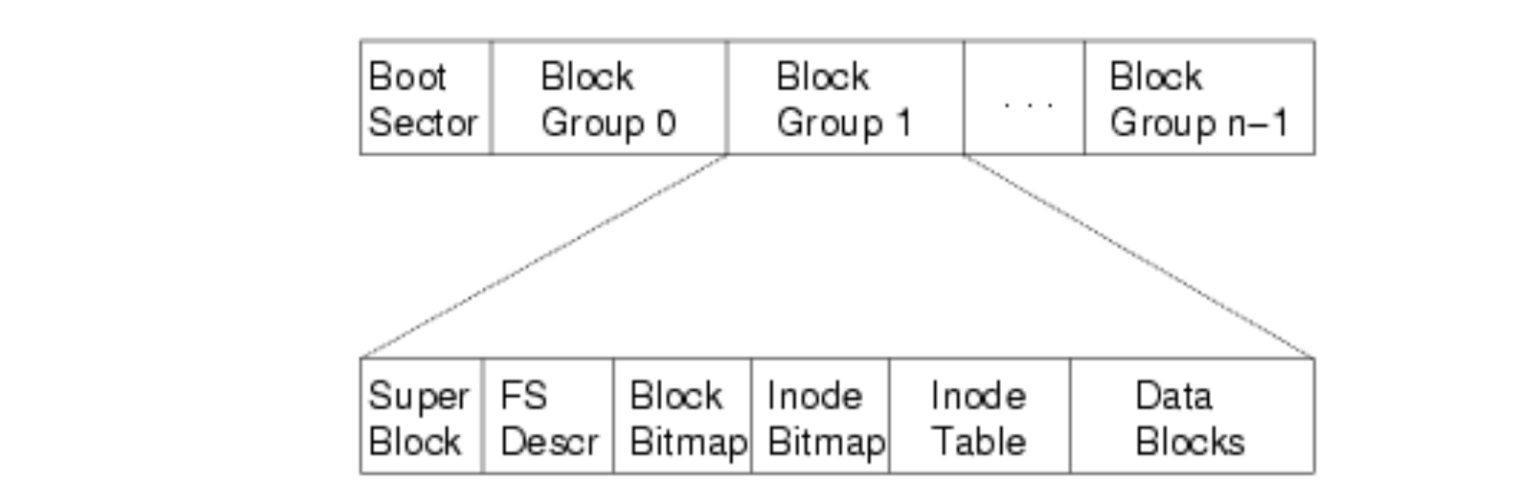
如何更好的支持大文件?ext2:
1.将文件的元数据集中存放
2.小文件用链表,大文件用树()
ext2.h 里有你需要知道的一切
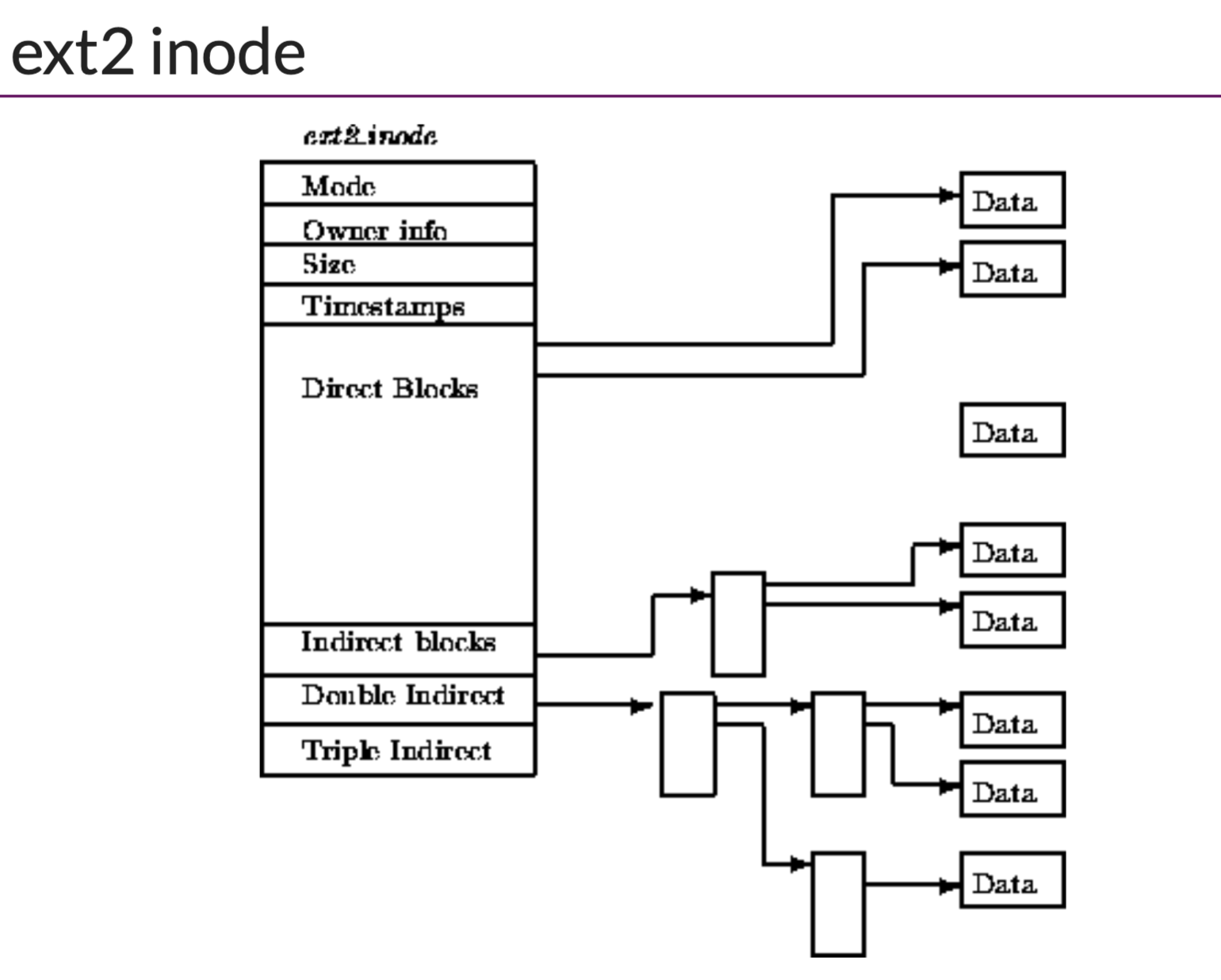
inodetable包含所有的inode条目(文件的元数据),小数据直接存放在inode内,大数据通过多级索引到datablock。
etx2的目录:
k-v:inode编码-名称
Takeaway messages
- “书签” - lseek
- 文件系统实现 = 自底向上设计实现数据结构
- balloc/bfree
- FAT/inode/…
- 文件和目录文件
- 先是有了bwrite+bread
- 实现balloc,bfree(fat中就是fattable,inode中就是不同类型bitmap)
- 实现文件FAT/Inode 虚拟磁盘(可变长的字节序列作为文件)
- 实现目录
理解了如何管理内存,也就明白了文件。
0x1c持久数据的可靠性
- 1bit
- 设备
- ———————————上面是物理层,下面是软件层———————–
- 驱动
- block I/O - Block Array
- 文件系统
数据结构的另外假设:内存可靠+可以接受断电数据丢失
文件无法接受上述假设
- RAID (Redundant Array of Inexpensive Disks)
- 崩溃一致性
RAID
传统的虚拟,是将一个物理实体,虚拟成多个逻辑实体
- 进程:把一个 CPU 分时虚拟成多个虚拟 CPU
- 虚存:把一份内存通过 MMU 虚拟成多个地址空间
- 文件:把一个存储设备虚拟成多个虚拟磁盘
RAID则是反向虚拟,将多个物理实体,虚拟成一个逻辑实体
A case for redundant arrays of inexpensive disks (RAID)
如何实现反向的虚拟呢?
最简单:
镜像(RAID1)=一个虚拟磁盘,保存多个物理副本
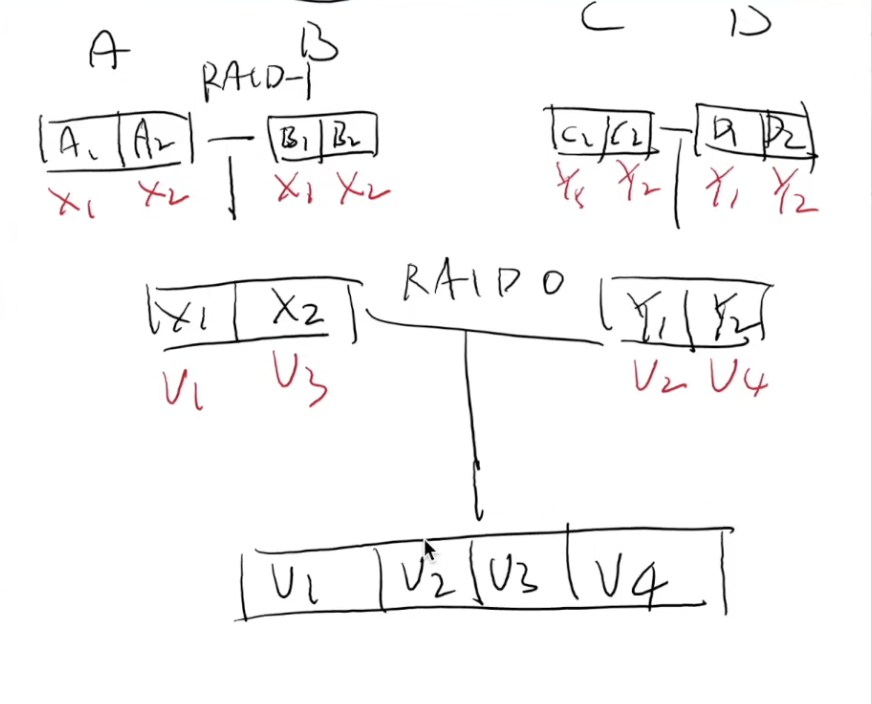
RAID0: 交错排列,扩大容量,扩大速度,但不容错
高阶RAID
RAID提出了一个巨大的思想,虚拟磁盘到物理磁盘之间的映射p=f(v)。f 有多种设计。
RAID10 = ((RAID1)0)
RAID4
n个bit序列,如何在n1的空间,找到是哪一个bit序列丢失了? -异或XOR
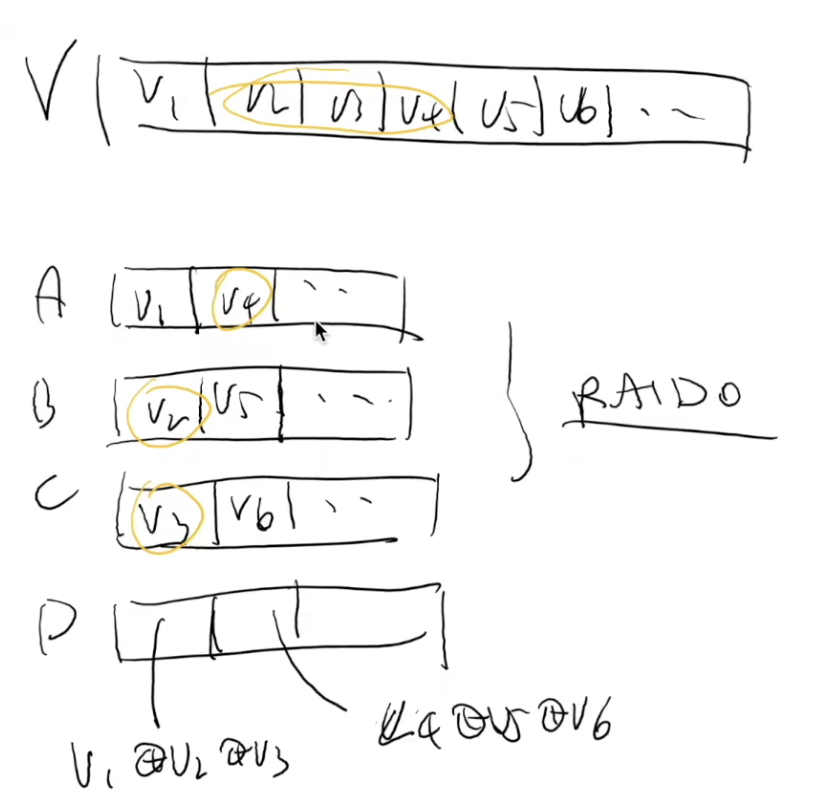
专门一块磁盘存放校验和check sum:a,b,c中任一坏了,依旧可以恢复
顺序读,随机读,顺序写,都ok,但随机写,涉及到更新check-sum,每次随机写都需要额外读d盘
专门留一块磁盘作为奇偶校验盘。
- {V1,V2,V3}→{A1,B1,C1,D1}{V1,V2,V3}→{A1,B1,C1,D1}
- V1→A1V1→A1, V2→B1V2→B1, V3→C1V3→C1 (不容错)
- D1=V1⊕V2⊕V3D1=V1⊕V2⊕V3 (奇偶校验)
性能分析
Sequential/random read: 3x (75% 总带宽)
Sequential write: 3x (75% 总带宽)
Random write (tricky)
-
D1=V1⊕V2⊕V3
-
写入任意V1,V2,V3都需要更新D1
-
更新 V1 需要 readb({A1,D1}), writeb({A1,D1})
RAID5:将check-sum 放到每一个盘 -
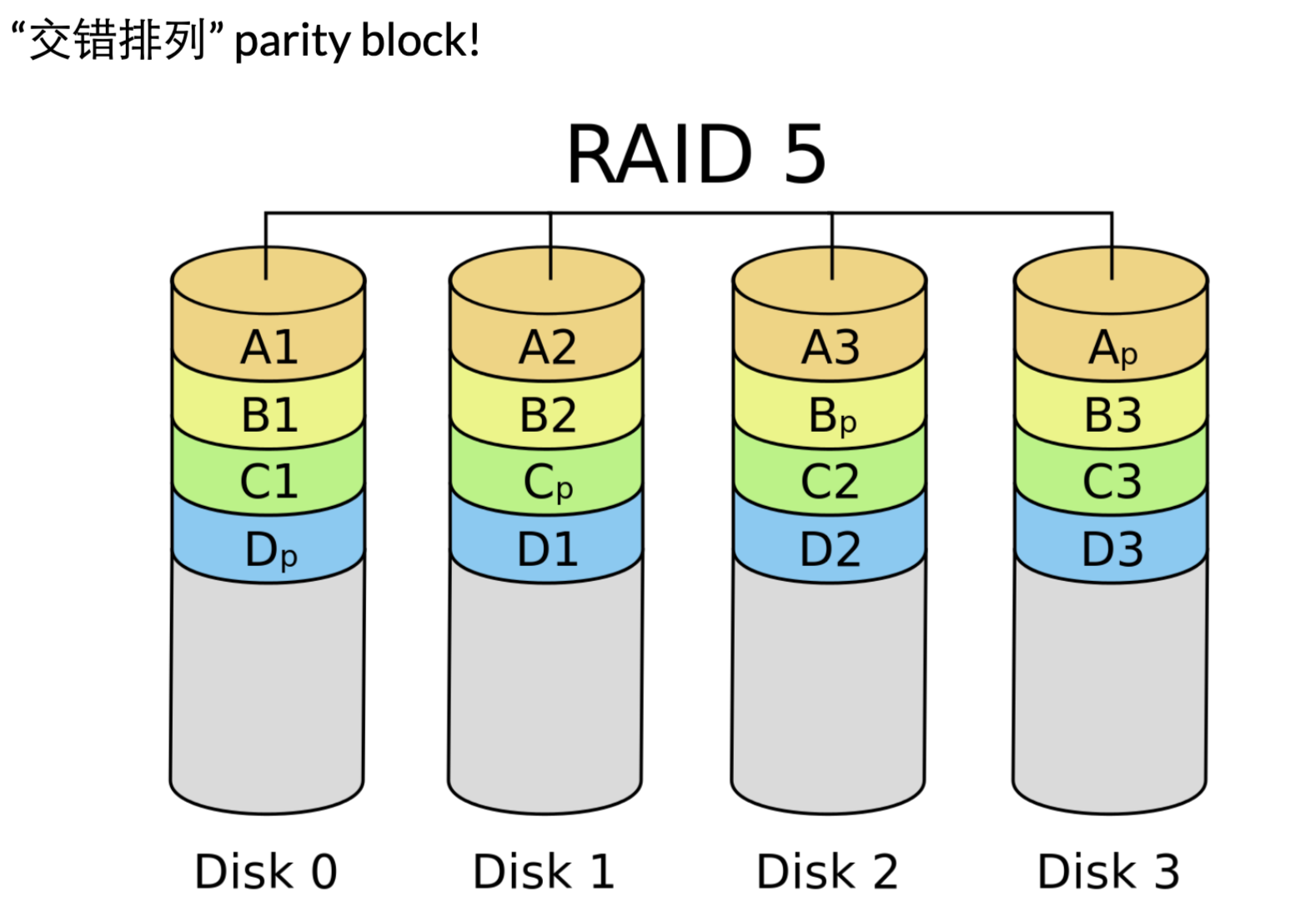
让每一块盘都有均等的机会存储 parity
-
- Sequential read/write: 3x (75% 总带宽)
- Random read (tricky)
- (read 足够大,所有磁盘都可以提供数据) 4x (100% 总带宽)
- Random write (tricky)
- D1=V1⊕V2⊕V3 写入任意 V1,V2,V3 都需要更新 D1
- 奇偶校验依然严重拖慢了随机写入
- 但至少 n块盘可以获得 n/4的随机写性能
- 有一定的 scalability
相比于RAID4 主要优化在于:读取&写入checksum,放到了多个盘,无需在一个盘上排队,并行数量由1变成n。
类似里程碑:The Google file system (SOSP’03) 和 MapReduce: Simplified data processing on large clusters (OSDI’04) 开启 “大数据” 时代
raid:将多台不可靠的磁盘,组成了一块可靠,性能更强的磁盘
大数据:将多台不可靠的计算机,组成一块更强更可靠的计算机(program model)
崩溃一致性-FSCK&日志
现有文件系统,即使append 1个字节,也涉及磁盘上多个块的修改,在硬件不提供all or nothing的情况下,如何软件层面实现一致性?
Crash Consistency: Move the file system from one consistent state (e.g., before the file got appended to) to another atomically (e.g., after the inode, bitmap, and new data block have been written to disk).
平时编程时假设不会发生的事,操作系统都要给你兜底
磁盘除了bwrite,bread 额外提供了bflush。
File System Checking (FSCK)
最终解决一致性: Journaling
数据结构的两种视角:
1.物理视角,一个完整的最终状态的数据结构
2.日志视角,初始状态+操作 = 最终状态
两个 “视角”
- 存储实际=数据结构
- 文件系统的 “直观” 表示
- crash unsafe
- Append-only 记录所有历史操作
- “重做” 所有操作得到数据结构的当前状态
- 容易实现崩溃一致
二者的融合
- 数据结构操作发生时,用 (2) append-only 记录日志
- 日志落盘后,用 (1) 更新数据结构
- 崩溃后,重放日志并清除 (称为 redo log;相应也可以 undo log)
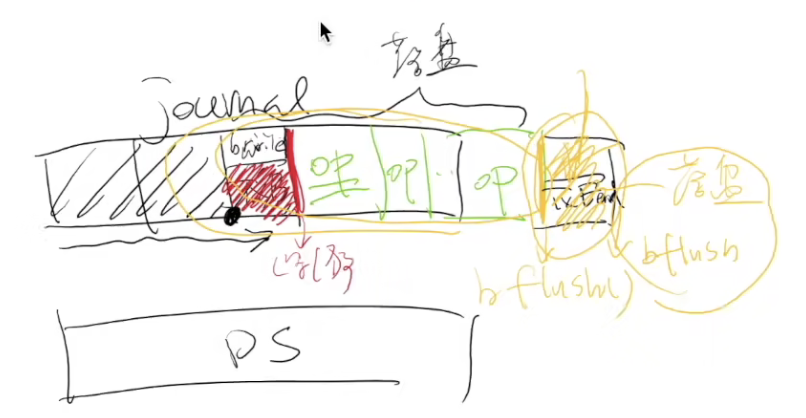
- 先写tx开始(无论是否flush)
- 再写op
- 写完op必须flush落盘
- 最后写tx结束并flush
- 然后再写入数据
崩溃后磁盘找到了tx结束的部分,则保证data部分与journaling一致,如果没发现tx结束的标记则删除对应日志。

实际中:Journaling Block Device,组团保存。
Takeaway messages
- 多个 bwrite 不保证顺序和原子性
- Journaling: 数据结构的两个视角
- 真实的数据结构
- 执行的历史操作
阅读材料
No.36 IO设备
常见系统架构:
内存总线,通用IO总线(PCI),外围设备IO总线
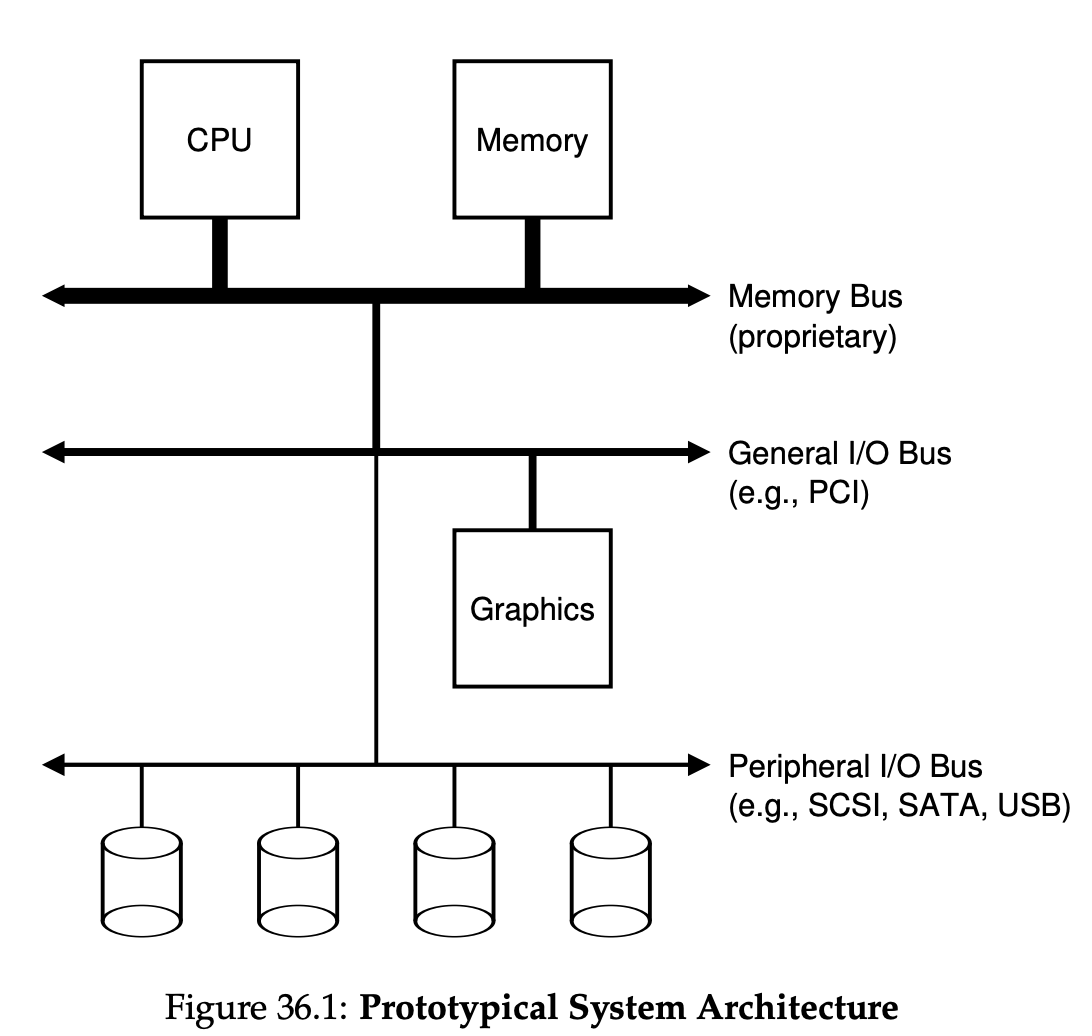
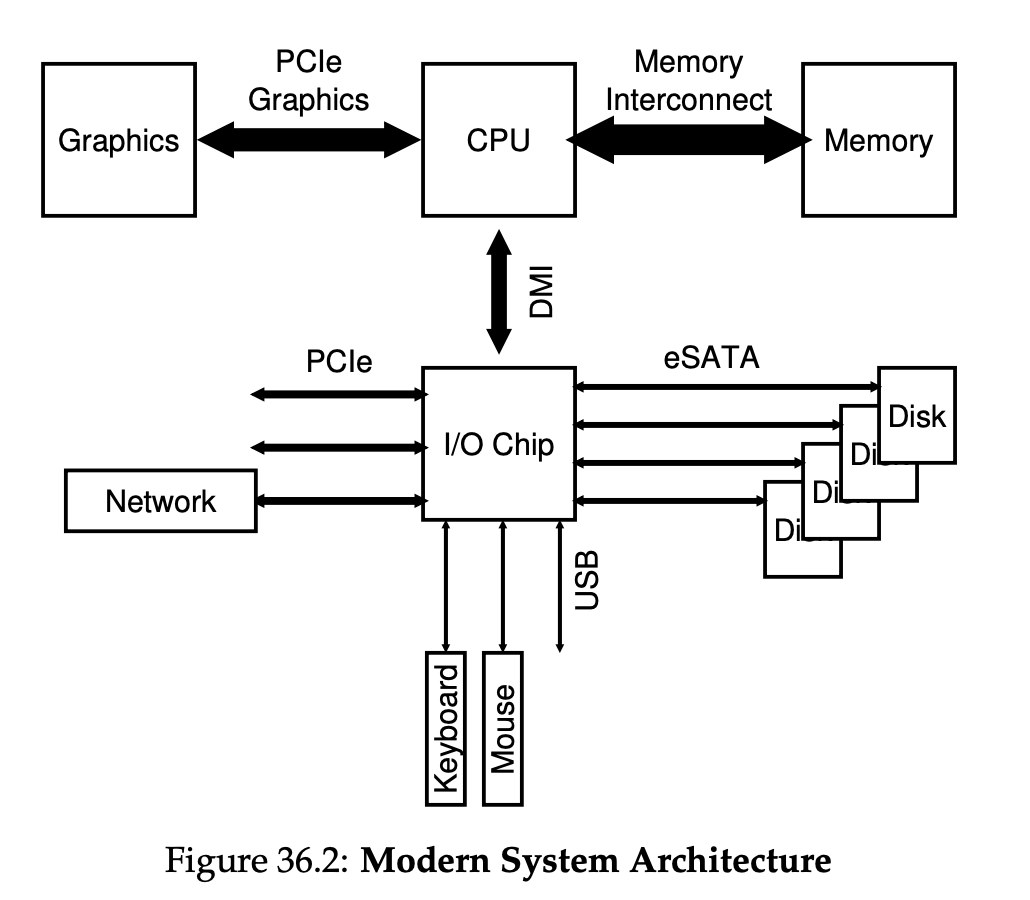
标准设备
标准设备抽象:暴露给外部的硬件接口+内部的逻辑实现
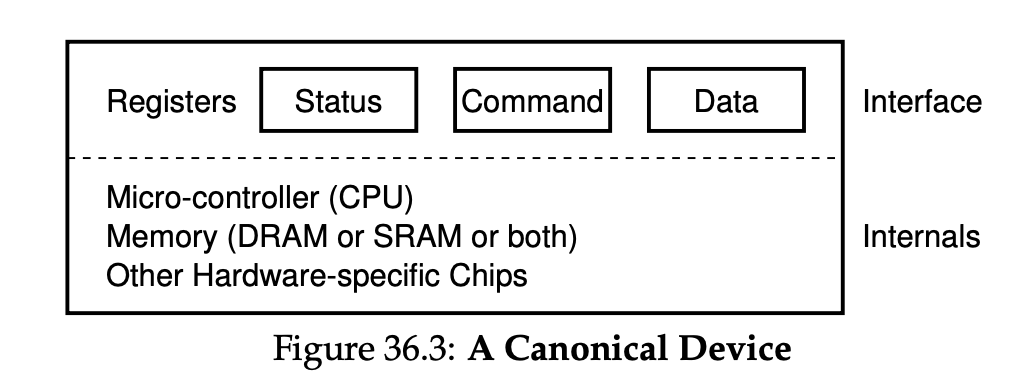
标准协议
标准设备有3个寄存器:状态寄存器,指令寄存器,数据寄存器
一般协议:
1.轮询状态寄存器,等待设备进入可接受命令的就绪状态
2.os下发数据到数据寄存器
3.将命令写入命令寄存器,设备开始执行
4.os轮询状态寄存器,判断命令是否执行成功
中断减少cpu开销
标准协议中,1&4的轮询会消耗大量cpu时间,引入中断
向设备发起请求后就中断,执行其他命令,设备执行完后再中断,恢复执行
note有时中断并非最佳方案:
1.设备非常快时
2.网络IO:大量请求,导致cpu全处理中断去了
中断的优化:合并,设备发出中断前,等待一会儿,可能会将几个中断合并成一个
DMA
额外设备,使得数据从内存到磁盘无需经过CPU
os与设备的交互
1.特权指令,x86的 in/out 指令
2.内存映射,将设备寄存器映射到特定地址空间
最终都可以抽象为,向特定寄存器写入数据。
驱动
设备接口(上面的与设备的交互)到 os接口之间的翻译。

总结
中断与DMA 用于提高设备效率
IO指令与内存映射IO,两种方式访问设备寄存器
驱动
No.37磁盘
关于磁盘的物理结构,不再介绍,记录磁盘的延迟:
all延迟 = 寻道+旋转+传输
调度算法:
1.SSTF shortest-seek-time-frist 最短寻道时间
2.电梯调度SCAN
3.SPFT shortest-positioning-time-frist 最短定位时间
现在关于磁盘的相关调度算法已经下放到了设备内部与OS无关了
No.38 廉价冗余列阵
更大,更快,更可靠
接口与内部
接口:一个很大的磁盘
内部:多个物理磁盘
故障模型
故障-停止 :一旦内部磁盘发生故障,可以立即停止磁盘工作
RAID0
磁盘条块化,提供更好的性能,没有任何冗余
读写被分解到多个磁盘,实现读写的并行执行。
RAID1
镜像,提供了冗余,但性能基本没变化
RAID10
((Raid1)0) 峰值减半
RAID4
单独一块盘,进行校验
校验方法
1.读取所有位置的内容,然后计算校验值
2.读取原本的校验值,P ^new^ = (C^new^ XOR C^old^ ) XOR P^old^
RAID5
旋转奇偶校验,将校验分散到所有盘。使之可以并行。
No.39 文件与目录
进程:虚拟化的cpu
地址空间:虚拟化的内存
存储虚拟化的关键:文件&目录
文件:线性数组,有一个用户不知道的inode号
目录:一个文件,k-v对,inode-文件名称
文件接口
创建:open
读:read
写:write
偏移量:lseek
刷盘:fsync
重命名:rename
元数据:stat fstat
删除文件:unlink
目录:mkdir、opendir、readdir、closedir、rmdir
硬连接:link,目录与inode连接,unlink,解连接,但inode的引用为0时,文件系统释放inode
软连接:名称-路径
文件系统
mkfs:创建文件系统
mount:挂载文件系统
No.40文件系统实现
VSFS very simple file system
superblock
inode-bitmap
data-bitmap
inode-list
data
inode
index node :存放的一些matadata,权限、扇区位置等
inode中一般还包含一些直接指针和多重间接指针
目录文件一般存放在特定区域,诸如:编号为2的inode
文件读写
读取:依次打开路径中的inode,直至最终文件的inode。
文件/usr/liaozk/hello.txt
1.打开根目录inode,发现里面存了usr这个目录文件
2.打开usr目录文件inode,发现liaozk目录文件
3.打开liaozk目录文件inode,发现hello.txt 文件对应的inode
4.打开hello inode
No.41局部性与快速文件系统
最开始:unix :super-inodes-data
然后:FFS:fast file system
第一层:分组(类似ext的block group)
第二层:super-inodeBitmap-dataBitmap-inodes-data
分配策略:
1.inode与关联的data放在一起
2.相同目录尽量放在同一个组内
3.大文件,分块分组存放
其他优化:引入小分组+布局优化
No.42崩溃一致性
因为文件数据结构,更新某一个文件必然涉及到磁盘的多个部分,而硬件不提供 一致性保证。
FSCK
处理逻辑不一致的部分,但在处理过程中又崩溃了,可能导致更大的危害
journaling
回到前面
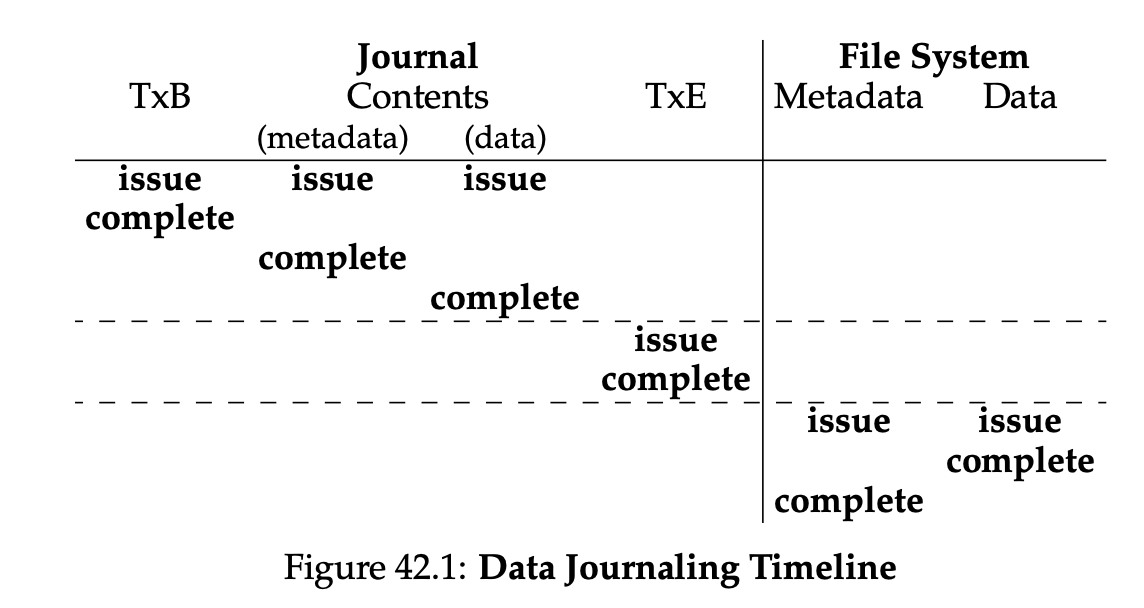
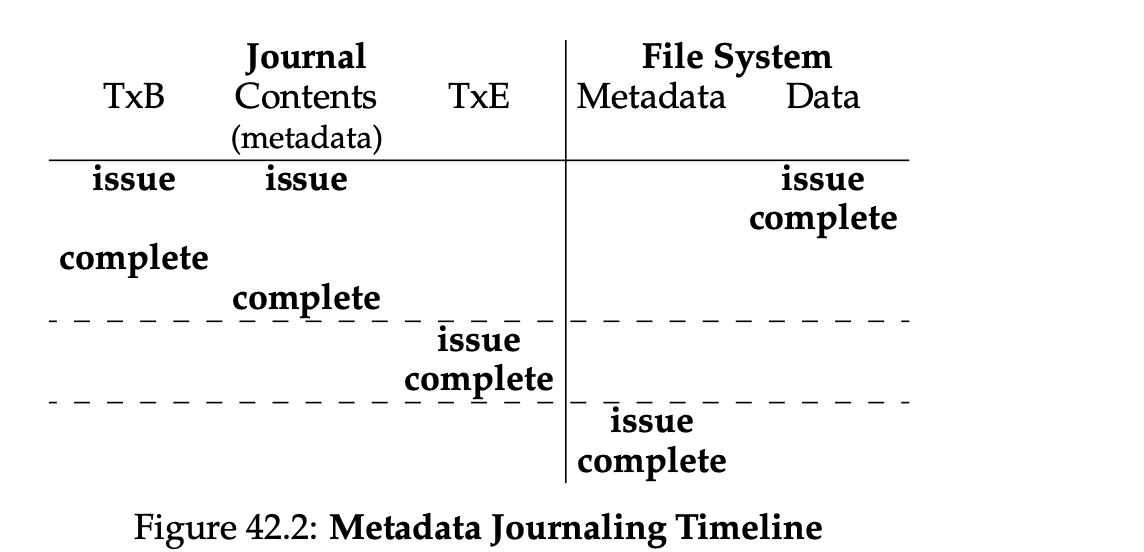
元数据日志:日志中不记录data,只记录其他元数据。
1.数据写入
2.日志元数据写入
3.日志提交
4.元数据更新到磁盘
5.释放
其他方法:
1.软更新,复杂的更新顺序
2.copy on write
3反向指针
No.43日志结构文件系统
因为缓存,文件系统的瓶颈就是写入
LFS:Log-structured File System
不深入了解了:写入时,将所有的更新缓存在内存段中,段满后进行一次长长时间的顺序传输,LFS不覆盖现有文件,永远都是将段写入空闲位置。
具体展示略…
0x1d xv6文件系统
注意要使用 gdb-multiarch
注意区分 fat 的逻辑实现与物理实现。逻辑上就是一个一个块连起来就是文件,物理上有fat entry 与 data簇
如何读代码:https://jyywiki.cn/OS/2022/slides/29.slides.html#/2/2
20250510:脚本异常Cannot locate block for frame,无法从frame中读取block,f.block() 异常了可能与版本等优化有关
论google的重要性:https://sourceware.org/gdb/current/onlinedocs/gdb.html/Frames-In-Python.html#Frames-In-Python:Return the frame’s code block. See Blocks In Python. If the frame does not have a block – for example, if there is no debugging information for the code in question – then this will throw an exception.
检查原生的makefile:编译mkfs时确实没有添加debug信息,编译选项加上-ggdb即可。
Todo:优化-可以对trace.py修改在返回的时候添加断点实现,读取方法的返回值。
#部分输出:
ialloc(type=1)
winode(inum=1)
rsect(sec=32)
wsect(sec=32)
iappend(inum=1, n=16)
rinode(inum=1)
rsect(sec=32)
rsect(sec=46)
wsect(sec=46)
winode(inum=1)
rsect(sec=32)
wsect(sec=32)
nmeta 46 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 1) blocks 1954 total 2000
sec=32 是第一个inode所在的地方
sec=46 是第一个datablock所在的地方(第一个inode指向的数据区)
buffer cache
通过观察上面的fs,修改一个文件涉及到与磁盘的多次顺序交互。
真正的读写文件过程中:
bread/bwrite –> buffer cache –> os read/write
buffer cache 也提供了bread&bwrite,其中bread调用bget,没有才从磁盘读
调试sys_read?
sys_write
commit中:
static void
commit()
{
if (log.lh.n > 0) {
write_log(); // Write modified blocks from cache to log
write_head(); // Write header to disk -- the real commit
install_trans(0); // Now install writes to home locations
log.lh.n = 0;
write_head(); // Erase the transaction from the log
}
}
write_log:将logheader中涉及的块,依次读出来,追加写到磁盘日志头后面的block中
write_head:将logheader中块的数量,及每一块的序号,写到磁盘日志头
install_trans:将磁盘日志中的每一块内容,写到磁盘真正对应块
keypoint:log.lh.block[]保存的是涉及的每一block的序号!
这里比较容易搞混but,AI万岁。
//bomb
void crash() {
static int count = 20;
if (--count < 0) {
printf("boom~ system crash!");
*((uint*)0x100000) = 0x5555;//riscv文档规定,写入这个虚拟机就会关闭
}
}
xv-6 riscv make qemu 后可以在qemu的监控器中 info mtree(查看内存树结构) 得到
0000000000100000-0000000000100fff (prio 0, i/o): riscv.sifive.test
这段地址是riscv给我们的测试使用地址。
任何指令集都有提供软件关闭物理机器的指令(操作系统中的关机)。
???kvmmap(kpgtbl, 0x100000, 0x100000, PGSIZE, PTE_R|PTE_W) 额外映射这一页?
“Get out of your comfort zone.”
懒惰是我们的本性,克服懒惰,获得激励和 “self motivation”
Takeaway messages
- 调试代码的建议
- 先了解一下你要调试的对象
- 然后从 trace 开始
- 不要惧怕调试任何一部分
0x1e现代存储系统
关系型数据库&分布式存储系统
文件系统就是一个数据结构的物理化,我们为什么还需要数据库等等文件系统
优点:直观
缺点:低 scalability,低可靠性
性能不是瓶颈的时候,为什么要自找麻烦关系型数据库

重新来理解数据库,历来近乎刻板似的把数据库当作数据存储而没有思考为什么?
数据库提供了哪些不同于传统文件系统的功能?
1.通过关系,将对数据的管理从应用逻辑里抽取出来了。把数据从应用程序剥离出来,实现一个复杂的系统,然后优化。
2.实现高性能的检索(索引+查询优化(类似编译器))
3.ACID
Q:数据库的表在文件系统中(磁盘中)的数据结构是什么?一个有特定数据结构的db文件?
虚拟磁盘 (文件) 上的数据结构
- 把 SQL 查询翻译成 read, write, lseek, fsync 的调用
- 并发控制 (事务处理)
想学习如何实现? - Bustub from CMU 15-445
- L0 - C++ Primer
- L1 - Buffer Pool Manager
- L2 - Hash Index
- L3 - Query Execution
- L4 - Concurrency Control
- SQLite
分布式数据存储
k-v storage
网络+数据中心 = 互联网
社交网络,2010开始,已经没有关系型数据库可以支撑了
深处潮流中,没法发现潮流在历史中的位置
文件系统 -> 数据库-> big storage 分布式存储

cap:延迟与一致性 无法同时满足
分布式系统的基础 :“分布式共识协议” - In search of an understandable consensus algorithm (USENIX ATC’14, Best Paper Award 🏅)
- 单进程 (多线程),按 key 排序
- 支持 transactions
- 支持快照 (对某个状态的瞬时只读快照)
一种实现方法:日志 snapshot()返回当前文件的长度-
put(k, v)
都直接把 (k, v) 追加写入到文件尾部- 效率极高
- 效率极高
-
get(k, v)
遍历整个文件- 效率极低 (“读放大”) → 怎么办?
一个模拟出的 “Memory Hierarchy”
- 效率极低 (“读放大”) → 怎么办?
- 写入直接 append to log file
- Crash safe; 不能更快了
解决读放大 - 不管三七二十一,先在内存中维护 log 的实时数据结构 (memtable)
- get 可以先在内存
- Level 0: 直接把 memtable dump 到磁盘
- 查找失败时,会到下一层继续查找
- Level 1: 在 Level 0 满 (4MB) 时,排序所有 key,与 Level 1 合并
- 下一层大小是上一层 10 倍
- Level 2: 在 Level 1 满时,把操作应用到 Level 2, …
0x1fAndroid 系统
android
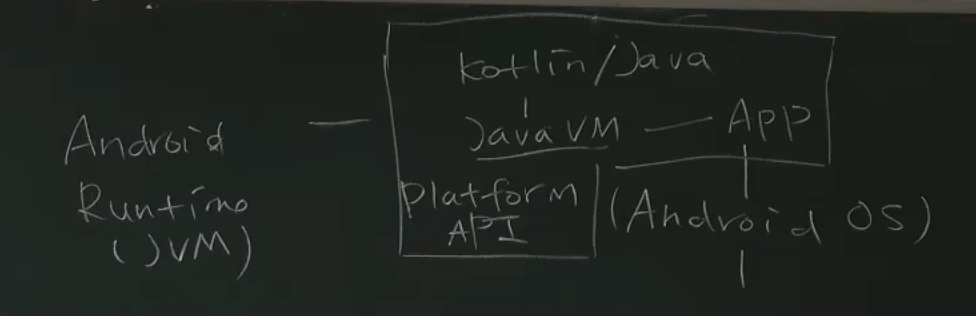
Linux + Framework + JVM - 在 Linux/Java 上做了个二次开发?
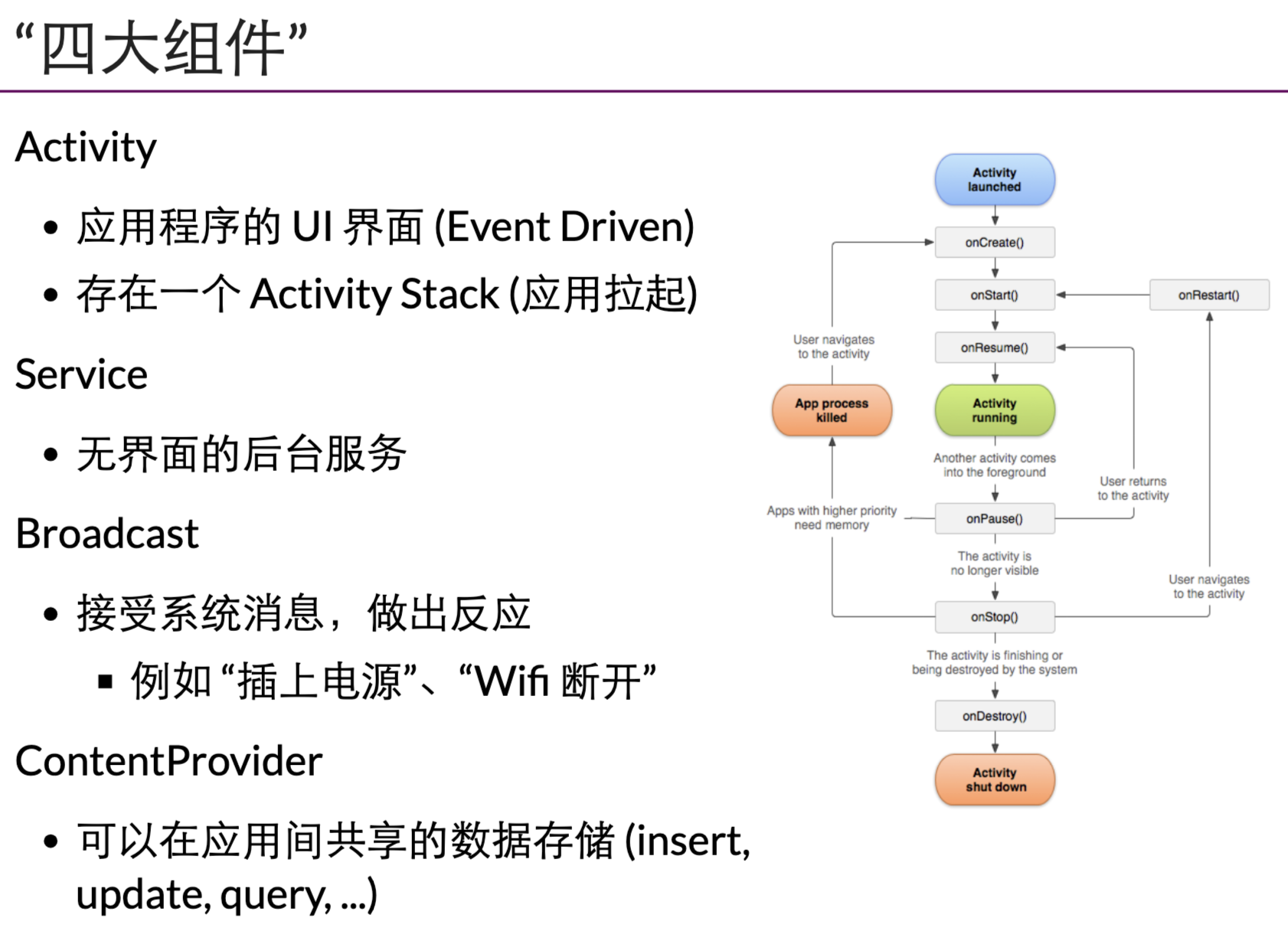
- 并不完全是:Android 定义了应用模型
每一个手机应用都是一个独立的linux 进程
app 是java vm 上的程序
andriod 在linux core 的基础上给 app 提供了完整的运行环境,提供了其他的抽象。所以andriod 是os
推荐阅读:andriod runtime 教科书级别
利用死锁,保持应用永远在线…
adb 连接手机与电脑
0x20总结
从逻辑门到操作系统
数字逻辑电路:
所有的数字系统都是状态机
数字系统就是计算机世界内最小的公理系统
把状态机描述出来
电路,数字系统
编程语言+算法: 四个学期的问题求解
每一个程序,其实也是在描述一个状态机
状态:栈,堆,局部变量
状态迁移:语句
如何使程序在数字系统上运行?
1.数字系统到体系结构(ISA 指令集 )
2.编译器(一个程序 ):将编程语言描述的状态机转换为ISA描述的状态机
3.操作系统(一个程序):状态机的管理,共享相同的硬件资源
https://jyywiki.cn/OS/2022/slides/32.slides.html#/1/4
从裸机到可以执行软件的状态。
操作系统:定义了一些对象与对应的API