大模型 RAG Demo
RAG
偶然间从前同事Yzh处了解到RAG,简化理解为,为大模型输入,新增一个context,使之大模型的回答,在自身语料的基础上,可以更符合相关业务知识,毕竟这些业务知识,并不会出现在互联网上。加之公司本身就有许多的文档资料,各种FS与TS。不过这玩意儿为什么没有火的一塌糊涂?
6月接触到这个概念,事实上5月我就放弃了jyy的OS课剩余的作业部分,度过了没有明确目标的两个月…今天2025-07-08,flag:试图在一周内建立起一个demo。开干!
来一张amazon的介绍图:

之前搜了一些资料,也有一些课程教学如何用java去编写,但我实在不想使用java来搞这些了… fuck java…
deeplearning.ai上有一节讲述用langchain构建对话机器人的课程。主要区别在于原教程使用的openAI,因为众所周知的原因,本文涉及相关全部换成了Qwen相关组件。
python3 -m venv langchain
source langchain/bin/activate
load
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
# openai.api_key = os.environ['OPENAI_API_KEY']
#step 1 load data
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/TS_CityPlan2024+作废流程 - Overview.pdf")
pages = loader.load()
print(len(pages))
page = pages[0]
print(page.page_content[:500])
print(page.metadata)
"""
from langchain.document_loaders.generic import GenericLoader, FileSystemBlobLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
url="https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir="docs/youtube/"
loader = GenericLoader(
#YoutubeAudioLoader([url],save_dir), # fetch from youtube
FileSystemBlobLoader(save_dir, glob="*.m4a"), #fetch locally
OpenAIWhisperParser()
)
docs = loader.load()
"""
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://liaozk.wiki/man_complete/os/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F_%E5%B9%B6%E5%8F%91")
docs = loader.load()
print(docs[0].page_content[:500])
split
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
# openai.api_key = os.environ['OPENAI_API_KEY']
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
chunk_size =26
chunk_overlap = 3
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
text1 = 'abcdefghijklmnopqrstuvwxyz'
print(r_splitter.split_text(text1))
text2 = 'abcdefghijklmnopqrstuvwxyzabcdefg'
print(r_splitter.split_text(text2))
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
print(r_splitter.split_text(text3))
print(c_splitter.split_text(text3))
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator = ' '
)
print(c_splitter.split_text(text3))
some_text = """When writing documents, writers will use document structure to group content. \
This can convey to the reader, which idea's are related. For example, closely related ideas \
are in sentances. Similar ideas are in paragraphs. Paragraphs form a document.
\
Paragraphs are often delimited with a carriage return or two carriage returns. \
Carriage returns are the "backslash n" you see embedded in this string. \
Sentences have a period at the end, but also, have a space.\
and words are separated by space."""
print(len(some_text))
c_splitter = CharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separator = ' '
)
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separators=["
", "
", " ", ""]
)
print(c_splitter.split_text(some_text))
print(r_splitter.split_text(some_text))
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["
", "
", "\. ", " ", ""]
)
print(r_splitter.split_text(some_text))
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["
", "
", "(?<=\. )", " ", ""]
)
print(r_splitter.split_text(some_text))
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/TS_CityPlan2024+作废流程 - Overview.pdf")
pages = loader.load()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="
",
chunk_size=1000,
chunk_overlap=150,
length_function=len
)
docs = text_splitter.split_documents(pages)
print(len(docs))
print(len(pages))
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0)
text1 = "foo bar bazzyfoo"
print(text_splitter.split_text(text1))
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
print(docs[0])
print(pages[0].metadata)
from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_document = """# Title
\
## Chapter 1
\
Hi this is Jim
Hi this is Joe
\
### Section
\
Hi this is Lance
## Chapter 2
\
Hi this is Molly"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_document)
print(md_header_splits[0])
print(md_header_splits[1])
22.32 效率确实低,才完成了加载&分割,next embed,检索,整合进入API。
23:55:本想用openAI的embed试一试,but 太贵了,基础5$…,中国还被禁止了…
embedding
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
# openai.api_key = os.environ['OPENAI_API_KEY']
"""
from langchain.document_loaders import PyPDFLoader
# Load PDF
loaders = [
# Duplicate documents on purpose - messy data
PyPDFLoader("./data/WIN+ 扫码开放全量扫码记录接口 - Overview.pdf")
]
docs = []
for loader in loaders:
docs.extend(loader.load())
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
print(len(splits))
print(splits[0])
"""
"""
client = openai.OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
"""
from langchain_community.embeddings import DashScopeEmbeddings
embedding = DashScopeEmbeddings(
model = "text-embedding-v4",
)
"""
sentence1 = "i like dogs"
sentence2 = "i like canines"
sentence3 = "the weather is ugly outside"
embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)
import numpy as np
print(f"相似度={np.dot(embedding1, embedding2)}")
print(f"相似度={np.dot(embedding1, embedding3)}")
print(f"相似度={np.dot(embedding2, embedding3)}")
from langchain.vectorstores import Chroma
persist_directory = './vector_persist/'
vectordb = Chroma.from_documents(
documents=splits[0:10],
embedding=embedding,
persist_directory=persist_directory
)
print(vectordb._collection.count())
question = "查询⻔店扫码记录的接口uri是什么?"
docs = vectordb.similarity_search(question,k=3)
print(len(docs))
print(docs[0].page_content)
print(docs[1].page_content)
print(docs[2].page_content)
vectordb.persist()
question = "最新的接口改动是什么呢?"
docs = vectordb.similarity_search(question,k=5)
print(docs)
print(docs[0].page_content)
print(docs[1].page_content)
"""
# 加载已存在的向量数据库
from langchain.vectorstores import Chroma
vectordb = Chroma(
persist_directory='./vector_persist/',
embedding_function=embedding
)
# 进行相似性搜索
question = "查询⻔店扫码记录的接口uri是什么?"
docs = vectordb.similarity_search(question, k=3)
# 打印结果
for i, doc in enumerate(docs):
print(f"文档 {i+1}:")
print(doc.page_content)
print("-"*50)
20250709:白天花了点时间,用上了阿里的embedding,now 是时候攻坚剩下的内容了,今晚完成20.27start,争取22点前回去!
retrieval
检索的算法之一
MMR:Maximal Marginal Relevance
1.先选出最切合的top-k
2.然后从k中选出最不同的作为结果
检索的算法之二
self-query:
利用LLM将自然语言转换为结构化查询
compression:将向量数据库中检索出的相关信息,进一步压缩,作为LLM的context
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
from langchain.vectorstores import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
embedding = DashScopeEmbeddings(
model = "text-embedding-v4",
)
persist_directory='./vector_persist/'
from langchain.vectorstores import Chroma
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embedding
)
print(vectordb._collection.count())
texts = [
"""The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).""",
"""A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.""",
"""A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms.""",
]
smalldb = Chroma.from_texts(texts, embedding=embedding)
question = "Tell me about all-white mushrooms with large fruiting bodies"
docs1 = smalldb.similarity_search(question, k=2)
docs2 = smalldb.max_marginal_relevance_search(question,k=2, fetch_k=3)
for i, doc in enumerate(docs1):
print(f"文档 {i+1}:")
print(doc.page_content)
print("-"*50)
for i, doc in enumerate(docs2):
print(f"文档 {i+1}:")
print(doc.page_content)
print("-"*50)
question = "查询⻔店扫码记录的接口uri是什么?"
docs_ss = vectordb.similarity_search(question,k=3)
print(docs_ss[0].page_content[:100])
print(docs_ss[1].page_content[:100])
docs_mmr = vectordb.max_marginal_relevance_search(question,k=3)
print(docs_mmr[0].page_content[:100])
print(docs_mmr[1].page_content[:100])
question = "查询⻔店扫码记录的接口uri是什么??"
"""
docs = vectordb.similarity_search(
question,
k=3,
filter={"source":"docs/cs229_lectures/MachineLearning-Lecture03.pdf"}
)
for d in docs:
print(d.metadata)
"""
from langchain_community.llms import Tongyi
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [
AttributeInfo(
name="source",
description="The lecture the chunk is from, should be one of `docs/cs229_lectures/MachineLearning-Lecture01.pdf`, `docs/cs229_lectures/MachineLearning-Lecture02.pdf`, or `docs/cs229_lectures/MachineLearning-Lecture03.pdf`",
type="string",
),
AttributeInfo(
name="page",
description="The page from the lecture",
type="integer",
),
]
document_content_description = "Lecture notes"
llm = Tongyi(
model="qwen-max",
temperature=0
)
retriever = SelfQueryRetriever.from_llm(
llm,
vectordb,
document_content_description,
metadata_field_info,
verbose=True
)
question = "查询⻔店扫码记录的接口uri是什么?"
docs = retriever.get_relevant_documents(question)
for d in docs:
print(d.metadata)
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
def pretty_print_docs(docs):
print(f"
{'-' * 100}
".join([f"Document {i+1}:
" + d.page_content for i, d in enumerate(docs)]))
# Wrap our vectorstore
llm = Tongyi(
model="qwen-max",
temperature=0
)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever()
)
question = "查询⻔店扫码记录的接口uri是什么?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever(search_type = "mmr")
)
question = "查询⻔店扫码记录的接口uri是什么?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
'''
from langchain.retrievers import SVMRetriever
from langchain.retrievers import TFIDFRetriever
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Load PDF
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()
all_page_text=[p.page_content for p in pages]
joined_page_text=" ".join(all_page_text)
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1500,chunk_overlap = 150)
splits = text_splitter.split_text(joined_page_text)
# Retrieve
svm_retriever = SVMRetriever.from_texts(splits,embedding)
tfidf_retriever = TFIDFRetriever.from_texts(splits)
question = "What are major topics for this class?"
docs_svm=svm_retriever.get_relevant_documents(question)
docs_svm[0]
question = "what did they say about matlab?"
docs_tfidf=tfidf_retriever.get_relevant_documents(question)
docs_tfidf[0]
'''
Q&A
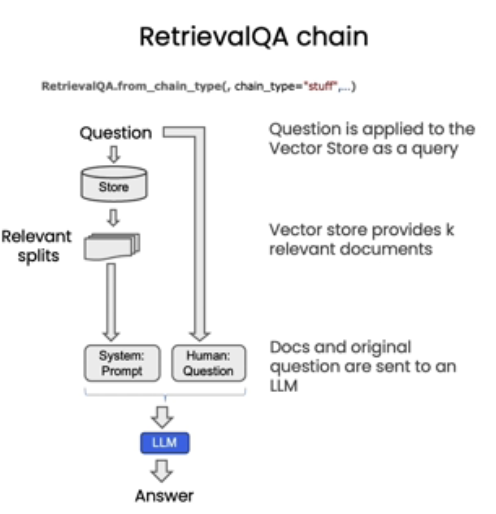
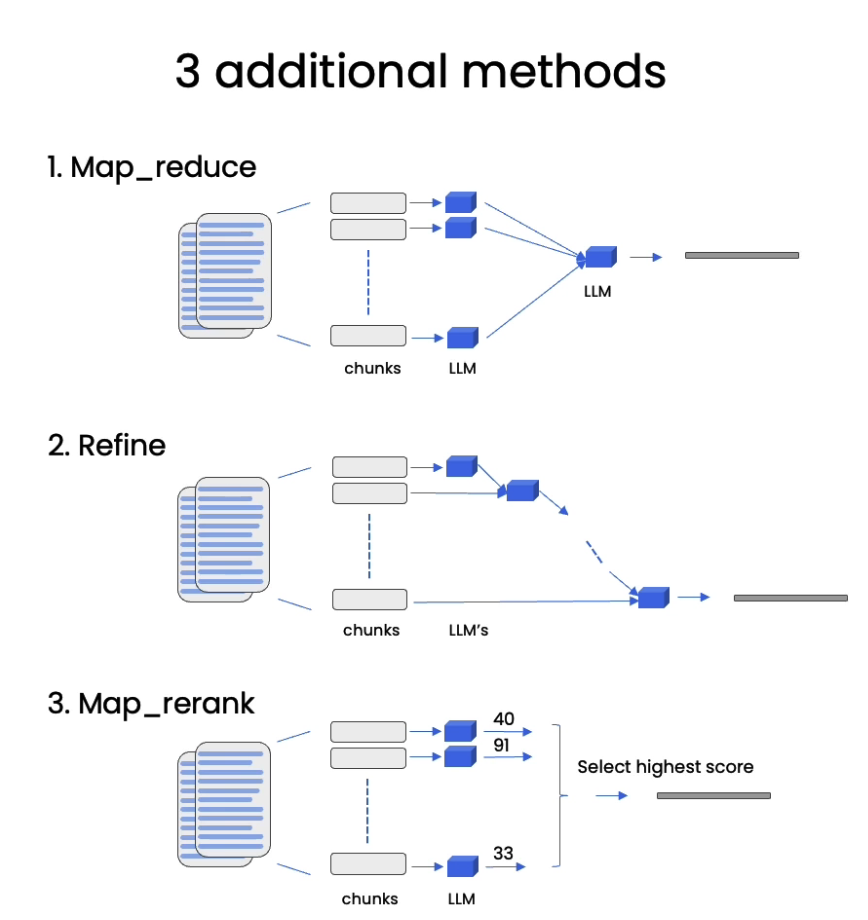
有三种方式将我们前面检索的内容插入到context中
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
from langchain.vectorstores import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
persist_directory='./vector_persist/'
embedding = DashScopeEmbeddings(
model = "text-embedding-v4",
)
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
question = "查询⻔店扫码记录的接口uri是什么?"
docs_mmr = vectordb.max_marginal_relevance_search(question,k=3)
from langchain_community.llms import Tongyi
llm = Tongyi(
model="qwen-max",
temperature=0
)
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
result = qa_chain({"query": question})
print(result["result"])
from langchain.prompts import PromptTemplate
# Build prompt
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
# Run chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
print(result["result"])
print(result["source_documents"][0])
"""
qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="map_reduce"#need transfrom
)
result = qa_chain_mr({"query": question})
print(result["result"])
"""
qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="refine"
)
result = qa_chain_mr({"query": question})
print(result["result"])
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
question = "查询⻔店扫码记录的接口uri是什么?"
result = qa_chain({"query": question})
print(result["result"])
至此粗略的完成了全部的内容
chatBot
需要慢慢打磨…,我还是需要学一点python相关的东西…
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain_community.llms import Tongyi
def load_db(file, chain_type, k):
# load documents
loader = PyPDFLoader(file)
documents = loader.load()
# split documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)
# define embedding
embeddings = DashScopeEmbeddings(model = "text-embedding-v4")
# create vector database from data
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# define retriever
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
# create a chatbot chain. Memory is managed externally.
qa = ConversationalRetrievalChain.from_llm(
llm = Tongyi(model="qwen-max", temperature=0),
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
return_generated_question=True,
)
return qa
import panel as pn
import param
class cbfs(param.Parameterized):
chat_history = param.List([])
answer = param.String("")
db_query = param.String("")
db_response = param.List([])
def __init__(self, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.loaded_file = "./data/WIN+ 扫码开放全量扫码记录接口 - Overview.pdf"
self.qa = load_db(self.loaded_file,"stuff", 4)
def call_load_db(self, count):
if count == 0 or file_input.value is None: # init or no file specified :
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
else:
file_input.save("temp.pdf") # local copy
self.loaded_file = file_input.filename
button_load.button_style="outline"
self.qa = load_db("temp.pdf", "stuff", 4)
button_load.button_style="solid"
self.clr_history()
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
def convchain(self, query):
if not query:
return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)
result = self.qa({"question": query, "chat_history": self.chat_history})
self.chat_history.extend([(query, result["answer"])])
self.db_query = result["generated_question"]
self.db_response = result["source_documents"]
self.answer = result['answer']
self.panels.extend([
pn.Row('User:', pn.pane.Markdown(query, width=600)),
pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))
])
inp.value = '' #clears loading indicator when cleared
return pn.WidgetBox(*self.panels,scroll=True)
@param.depends('db_query ', )
def get_lquest(self):
if not self.db_query :
return pn.Column(
pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),
pn.Row(pn.pane.Str("no DB accesses so far"))
)
return pn.Column(
pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),
pn.pane.Str(self.db_query )
)
@param.depends('db_response', )
def get_sources(self):
if not self.db_response:
return
rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]
for doc in self.db_response:
rlist.append(pn.Row(pn.pane.Str(doc)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
@param.depends('convchain', 'clr_history')
def get_chats(self):
if not self.chat_history:
return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)
rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]
for exchange in self.chat_history:
rlist.append(pn.Row(pn.pane.Str(exchange)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
def clr_history(self,count=0):
self.chat_history = []
return
cb = cbfs()
file_input = pn.widgets.FileInput(accept='.pdf')
button_load = pn.widgets.Button(name="Load DB", button_type='primary')
button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning')
button_clearhistory.on_click(cb.clr_history)
inp = pn.widgets.TextInput( placeholder='Enter text here…')
bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks)
conversation = pn.bind(cb.convchain, inp)
jpg_pane = pn.pane.Image( './img/convchain.jpg')
tab1 = pn.Column(
pn.Row(inp),
pn.layout.Divider(),
pn.panel(conversation, loading_indicator=True, height=300),
pn.layout.Divider(),
)
tab2= pn.Column(
pn.panel(cb.get_lquest),
pn.layout.Divider(),
pn.panel(cb.get_sources ),
)
tab3= pn.Column(
pn.panel(cb.get_chats),
pn.layout.Divider(),
)
tab4=pn.Column(
pn.Row( file_input, button_load, bound_button_load),
pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )),
pn.layout.Divider(),
pn.Row(jpg_pane.clone(width=400))
)
dashboard = pn.Column(
pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')),
pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4))
)
dashboard.show()